https://course.tianmaying.com/node
这个系列的文章看起来很不错,值得学习一下。
/Users/baidu/Documents/Data/Interview/Web-Server开发/深入浅出Node.js-f46c.pdf
深入浅出Node笔记:
// math.js exports.add = function () { var sum = 0, i = 0, args = arguments, l = args.length; while (i < l) { sum += args[i++]; } return sum; }; // program.js var math = require('math'); exports.increment = function (val) { return math.add(val, 1); };
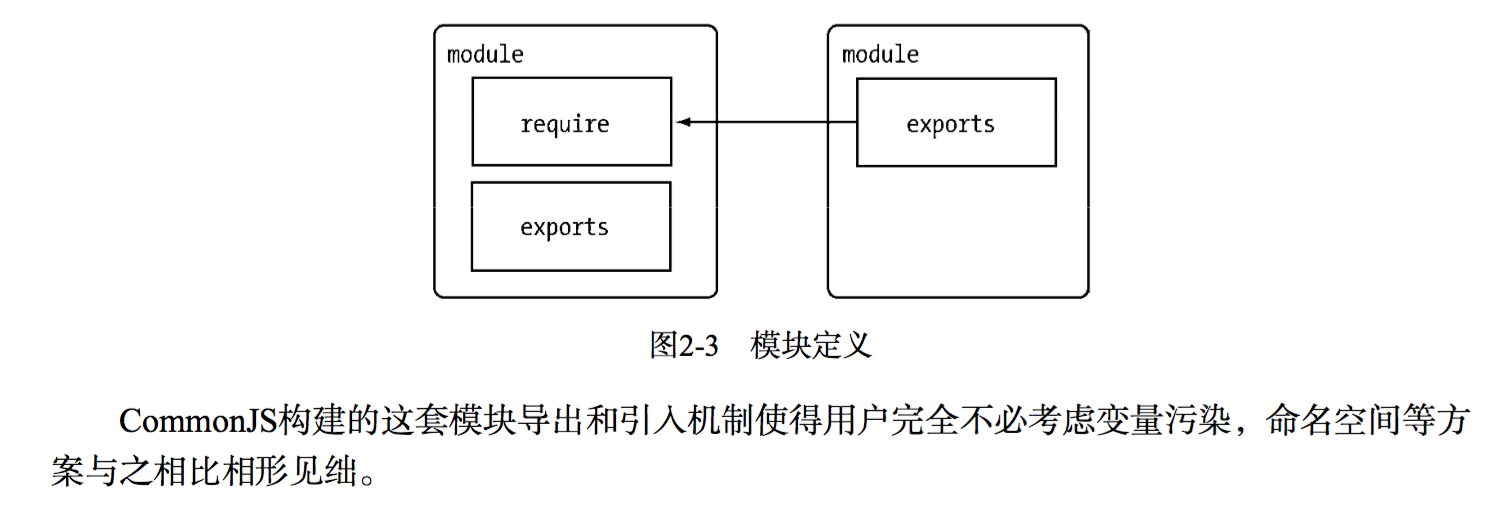
写一个例子:
$ cat module_path.js
console.log(module.paths);
运行:
$ node module_path.js [ '/Users/baidu/Documents/Data/Work/Code/Self/nodejs/node_modules', '/Users/baidu/Documents/Data/Work/Code/Self/node_modules', '/Users/baidu/Documents/Data/Work/Code/node_modules', '/Users/baidu/Documents/Data/Work/node_modules', '/Users/baidu/Documents/Data/node_modules', '/Users/baidu/Documents/node_modules', '/Users/baidu/node_modules', '/Users/node_modules', '/node_modules' ]
看到P66,有点枯燥。
http://blog.csdn.net/g9yuayon/article/details/1568980
明眼老大们自然可以看出这是函数编程的风格。其实JavaScript本就是采用C语言句法的简化版LISP,异常灵活。
用下面的例子看看:
http://blog.csdn.net/u012273376/article/details/52736906
利用nodejs做爬虫
上文中分析了设计和实现的过程,最后是利用从一个json文件里获取出数据,并存储来实现的。
http://www.bilibili.com/index/index-icon.json
内容类似:
{"fix":[{"id":"568","type":"fix","title":"u4e1bu6797","deltime":"0","posttime":"1475232463","edittime":"1475232495","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQueAcLCTAAAlMkM6OCk652.gif","weight":"2","links":["http://search.bilibili.com/all?keyword=%E4%B8%9B%E6%9E%97"]},{"id":"567","type":"fix","title":"u975eu6d32u6b22u8fceu4f60","deltime":"0","posttime":"1475232419","edittime":"1475232446","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQa2AeYm6AACICFF4-Wk024.gif","weight":"2","links":["http://search.bilibili.com/all?keyword=%E9%9D%9E%E6%B4%B2%E6%AC%A2%E8%BF%8E%E4%BD%A0"]},{"id":"566","type":"fix","title":"u806au54e5","deltime":"0","posttime":"1475232380","edittime":"1475232380","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQa6ABU5vAAAQAHdNgM4913.gif","weight":"2","links":["http://search.bilibili.com/all?keyword=%E8%81%AA%E5%93%A5"]},{"id":"565","type":"fix","title":"u975eu6d32u4eba (..u2022u02d8_u02d8u2022..)","deltime":"0","posttime":"1475232306","edittime":"1475232339","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQauAQVjgAAAZKlLn9aM964.gif","weight":"1","links":["http://search.bilibili.com/all?keyword=%E9%9D%9E%E6%B4%B2"]},{"id":"564","type":"fix","title":"SSR","deltime":"0","posttime":"1475232266","edittime":"1475232273","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQaiAHLMeAABMJhP3294905.gif","weight":"3","links":["http://search.bilibili.com/all?keyword=SSR"]},{"id":"563","type":"fix","title":"u9759u7535","deltime":"0","posttime":"1475232209","edittime":"1475232209","sttime":"1475145660","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/16/oYYBAFfuQaaAVYlOAAAPBHWFJBA697.gif","weight":"1","links":["http://search.bilibili.com/all?keyword=%E9%9D%99%E7%94%B5"]},{"id":"562","type":"fix","title":"u8214u51b0u68d2","deltime":"0","posttime":"1474973710","edittime":"1474973710","sttime":"1474887000","endtime":"0","state":"1","icon":"http://i0.hdslb.com/group1/M00/B8/10/oYYBAFfqTrOAOUUFAAASBQb9Glo754.gif","weight":"1","links":["http://search.bilibili.com/all?keyword=%E8%88%94%E5%86%B0"]},
......
在这个目录 /Users/baidu/Documents/Data/Work/Code/Self/nodejs/bilibili_spider 写了代码 index.js
const fs = require('fs') const request = require('request')
function getJsonFile(jurl) { request({ url: jurl, gzip: true }, function(err, res, body) { if (!err && res.statusCode == 200) { console.log('===获取Json成功==='); let result = JSON.parse(body); for (let i=0; i<result.fix.length; i++) { saveGif(result.fix[i].icon, result.fix[i].title); } } else { console.log('===Error info===', err, 'Code:'+res.statusCode); return false; } } ); }
function saveGif(url, title) {
console.log('存储图片=>' + title);
request(url).pipe(fs.createWriteStream('./gif/'+title+'.gif'));
console.log('图片' + title + '存储完成');
}
其中有几点需要说明和了解:
1. (() => {
const jsonUrl = 'http://www.bilibili.com/index/index-icon.json';
getJsonFile(jsonUrl);
})();
这是一个匿名函数。类似 ()(); 这样的就是匿名函数。为什么要加两个括号呢,因为第二个括号是用来调用的。
2. request是需要用npm来安装的
3. request(url).pipe(fs.createWriteStream('./gif/'+title+'.gif'));
这个用法要了解。
4. 如果目录(gif)不存在,文件是无法创建成功的。命令行看到打印出了结果,是因为JS是异步执行的。
第一次运行时候报错:
SyntaxError: Block-scoped declarations (let, const, function, class) not yet supported outside strict mode
上网搜了之后,在第一行增加了严格模式的声明:
"use strict";
然后运行,报了另外的错:
Error: options.uri is a required argument
上网查了半天,没想到在匿名函数前面加个log居然就好了。。。代码片段如下:
console.log("hi0");
(() => {
//console.log("hi1");
const jsonUrl = 'http://www.bilibili.com/index/index-icon.json';
//console.log("hi2");
getJsonFile(jsonUrl);
//console.log("hi3");
})();
function getJsonFile(jurl) {
//jurl = url.parse(jurl);
request({
url: jurl,
gzip: true
}, function(err, res, body) {
......
运行结果如下:
$ node index.js hi0 ===获取Json成功=== 存储图片=>丛林 图片丛林存储完成 存储图片=>非洲欢迎你 图片非洲欢迎你存储完成 存储图片=>聪哥 图片聪哥存储完成 存储图片=>非洲人 (..•˘_˘•..) 图片非洲人 (..•˘_˘•..)存储完成
文件内容如下:
莫非是由于异步调用的原因?
需要增加一个console.log,增加对异步调用的延迟?
未解。。。
后来又上网查了查,增加url模块的校验,感觉跟之前的也没差别:
"use strict"; const fs = require('fs') const request = require('request') const url = require('url'); //console.log("hi0"); (() => { //console.log("hi1"); const jsonUrl = 'http://www.bilibili.com/index/index-icon.json'; //console.log("hi2"); getJsonFile(jsonUrl); //console.log("hi3"); })(); function getJsonFile(jurl) { jurl = url.parse(jurl); request({ url: jurl, gzip: true }, function(err, res, body) { if (!err && res.statusCode == 200) { console.log('===获取Json成功==='); let result = JSON.parse(body); for (let i=0; i<result.fix.length; i++) { saveGif(result.fix[i].icon, result.fix[i].title); } } else { console.log('===Error info===', err, 'Code:'+res.statusCode); return false; } } ); } ......
可以看到,增加url.parse,去掉了console.log,调用也能成功了。实在是不知所以然。
然后我又仿照下面这个程序:
http://cnodejs.org/topic/54bdaac4514ea9146862abee
写了一个抓取lofter上图片的程序:
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var mkdirp = require('mkdirp');
var url = 'http://loftermeirenzhi.lofter.com/tag/人像?page=';
var dir = './images';
mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
});
var getImages = function(indexes) {
for (var i=1; i<=indexes; i++) {
var newUrl = url + i;
request(newUrl, function(error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body);
var $ = cheerio.load(body);
// selector
$('.img img').each(function() {
var src = $(this).attr('src');
console.log('正在下载' + src);
download(src, dir);
});
}
});
}
}
var download = function(url, dir) {
var fileName = Math.floor(Math.random()*100000) + url.substr(-4, 4);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(dir+'/'+fileName+'.jpg'));
});
};
getImages(1);
上面这一句我不是非常明白,感觉应该是先class再标签
$('.img img')
实际去抓的时候,发现只能抓下一个头图。而页面中实际的图是没有能够抓下来的。