原文地址:https://blog.csdn.net/fly_yr/article/details/49633099
序
最近做一个项目需要用到OpenCL,由于之前没有接触过,所以在环境配置第一关就遇到了一些问题,查阅很多资料才配置完成,现在记录如下,希望给一些童鞋一些帮助。
整个步骤也很简单:
- 了解系统配置,选择合适的安装包
- 安装CUDASDK
- 更新驱动
- VS2013下新建C++项目配置环境:
- 项目右键属性VC++目录,添加包含目录、库目录
- 项目右键属性连接器->输入,添加附加依赖项
- 添加测试代码,测试安装完成。
详细操作如下所示!
了解系统配置
首先,你需要了解自己电脑的硬件配置,显卡是哪个厂商出产的啊,支持不支持OpenCL等。这个方面,我们可以利用GPU-Z的工具来查看。
GPU-Z下载地址
这是我主机配置截图: 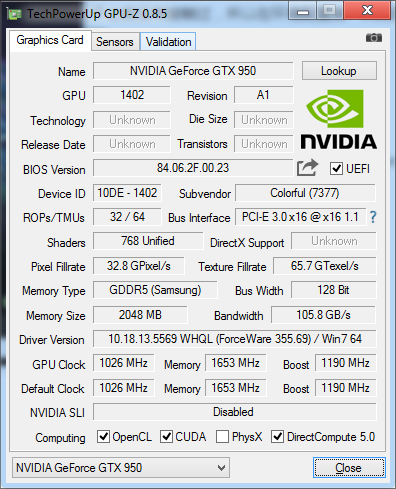
可以看到我的主机显卡是 英伟达 厂商 NVIDIA GetForce GTX 950 ,在最下面一栏 Computing中显示 支持OpenCL,CUDA。
安装CUDA SDK
查阅资料,发现对于NVIDIA的显卡,并没有单独的OpenCL SDK供安装使用,它是被CUDA SDK Tookits包含的,所以我们只需要下载安装CUDA Tookit即可,我安装的是目前的最新版本CUDA Tookit 7.5下载地址。
选择与自己系统相匹配的版本,安装即可。
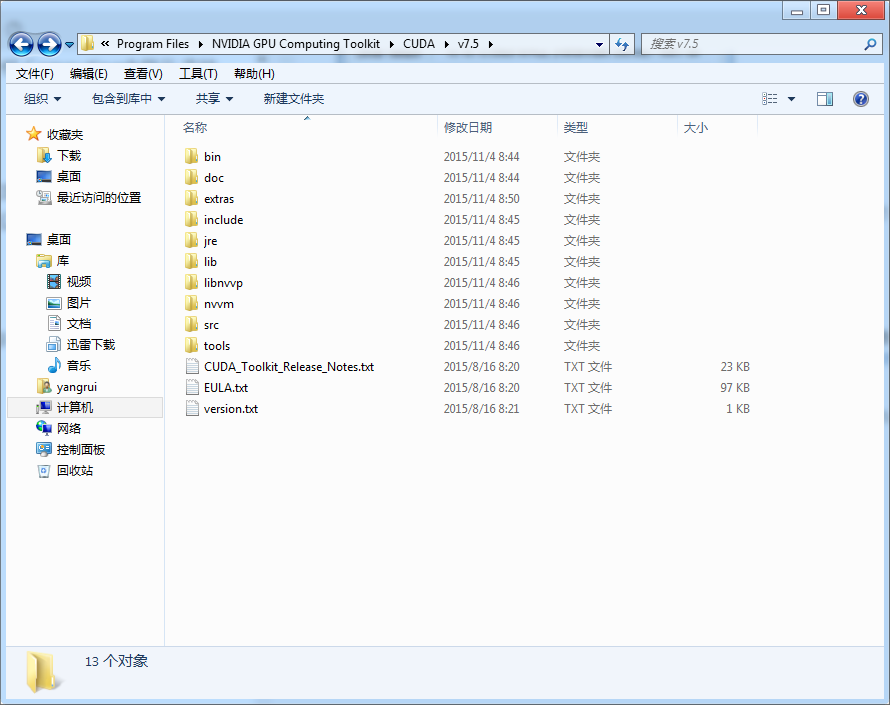
安装完成后,所在目录默认路径为:C:Program FilesNVIDIA GPU Computing ToolkitCUDAv7.5
更新显卡驱动
根据你的系统选择更新为最新的显卡驱动!
首先,检查当前显卡驱动版本:
控制面板—>设备管理器—>显卡—>(右键更新..)
当前我的显卡是最新版本,因此结果为: 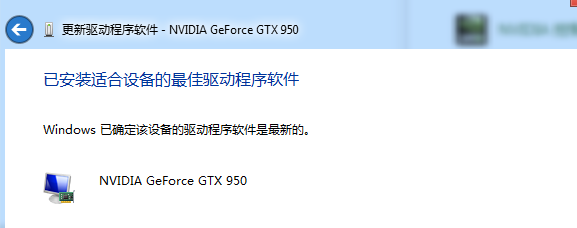
此时,即可进行下一步,配置VS环境。
如若你的版本不是最新版,需到官网下载更新驱动!
配置VS环境
- 打开VS,新建普通控制台C++项目,test。
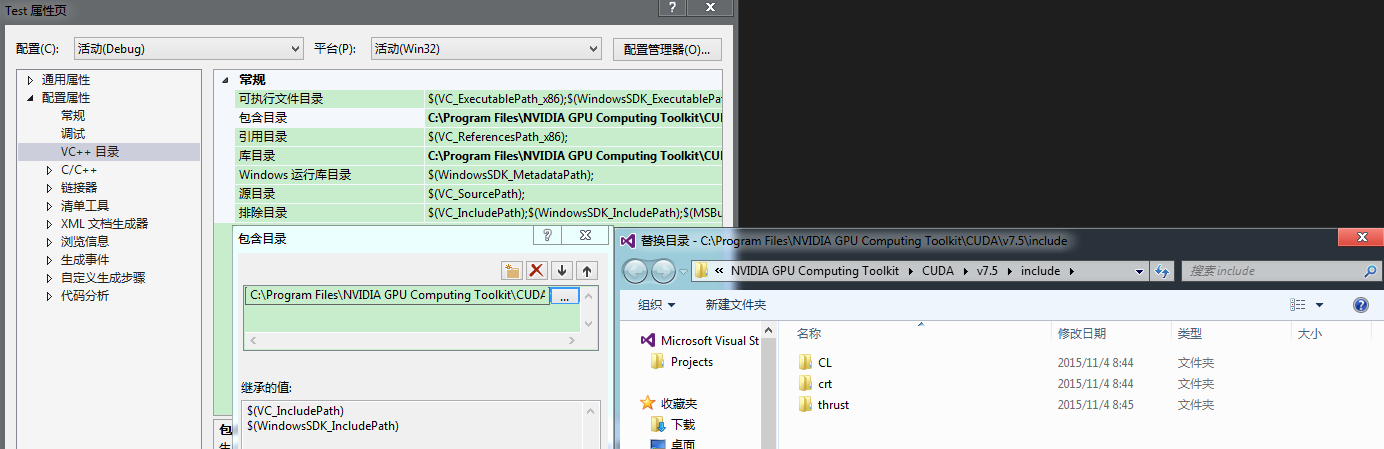
项目属性—>选择VC++目录,分别在包含目录和库目录下添加:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv7.5include
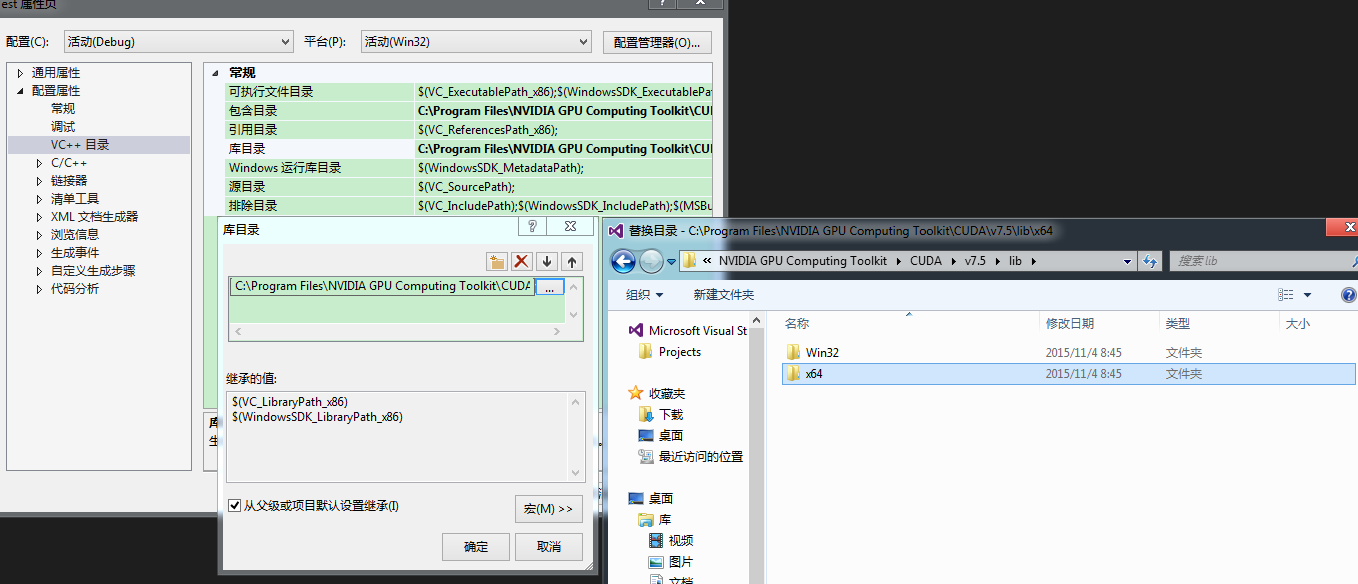
库目录根据版本选择,32位系统则选择win32
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv7.5libx64项目属性—>链接器—>输入,添加opencl.lib
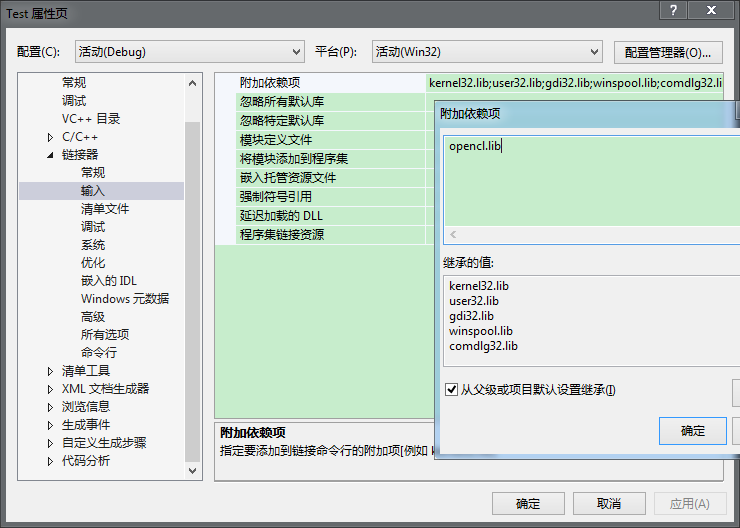
确定,配置完成!
编写测试程序,验证
(1). HelloWorld.cl
__kernel void hello_kernel(__global const float *a,
__global const float *b,
__global float *result)
{
int gid = get_global_id(0);
result[gid] = a[gid] + b[gid];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(2). main.cpp
//
// Book: OpenCL(R) Programming Guide
// Authors: Aaftab Munshi, Benedict Gaster, Timothy Mattson, James Fung, Dan Ginsburg
// ISBN-10: 0-321-74964-2
// ISBN-13: 978-0-321-74964-2
// Publisher: Addison-Wesley Professional
// URLs: http://safari.informit.com/9780132488006/
// http://www.openclprogrammingguide.com
//
// HelloWorld.cpp
//
// This is a simple example that demonstrates basic OpenCL setup and
// use.
#include <iostream>
#include <fstream>
#include <sstream>
#ifdef __APPLE__
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#endif
///
// Constants
//
const int ARRAY_SIZE = 1000;
///
// Create an OpenCL context on the first available platform using
// either a GPU or CPU depending on what is available.
//
cl_context CreateContext()
{
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
// First, select an OpenCL platform to run on. For this example, we
// simply choose the first available platform. Normally, you would
// query for all available platforms and select the most appropriate one.
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
{
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
}
// Next, create an OpenCL context on the platform. Attempt to
// create a GPU-based context, and if that fails, try to create
// a CPU-based context.
cl_context_properties contextProperties[] =
{
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformId,
0
};
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_GPU,
NULL, NULL, &errNum);
if (errNum != CL_SUCCESS)
{
std::cout << "Could not create GPU context, trying CPU..." << std::endl;
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_CPU,
NULL, NULL, &errNum);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to create an OpenCL GPU or CPU context." << std::endl;
return NULL;
}
}
return context;
}
///
// Create a command queue on the first device available on the
// context
//
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device)
{
cl_int errNum;
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
// First get the size of the devices buffer
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed call to clGetContextInfo(...,GL_CONTEXT_DEVICES,...)";
return NULL;
}
if (deviceBufferSize <= 0)
{
std::cerr << "No devices available.";
return NULL;
}
// Allocate memory for the devices buffer
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
if (errNum != CL_SUCCESS)
{
delete[] devices;
std::cerr << "Failed to get device IDs";
return NULL;
}
// In this example, we just choose the first available device. In a
// real program, you would likely use all available devices or choose
// the highest performance device based on OpenCL device queries
commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
if (commandQueue == NULL)
{
delete[] devices;
std::cerr << "Failed to create commandQueue for device 0";
return NULL;
}
*device = devices[0];
delete[] devices;
return commandQueue;
}
///
// Create an OpenCL program from the kernel source file
//
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
{
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open())
{
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
}
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
if (program == NULL)
{
std::cerr << "Failed to create CL program from source." << std::endl;
return NULL;
}
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (errNum != CL_SUCCESS)
{
// Determine the reason for the error
char buildLog[16384];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
sizeof(buildLog), buildLog, NULL);
std::cerr << "Error in kernel: " << std::endl;
std::cerr << buildLog;
clReleaseProgram(program);
return NULL;
}
return program;
}
///
// Create memory objects used as the arguments to the kernel
// The kernel takes three arguments: result (output), a (input),
// and b (input)
//
bool CreateMemObjects(cl_context context, cl_mem memObjects[3],
float *a, float *b)
{
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* ARRAY_SIZE, a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* ARRAY_SIZE, b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE,
sizeof(float)* ARRAY_SIZE, NULL, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL || memObjects[2] == NULL)
{
std::cerr << "Error creating memory objects." << std::endl;
return false;
}
return true;
}
///
// Cleanup any created OpenCL resources
//
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem memObjects[3])
{
for (int i = 0; i < 3; i++)
{
if (memObjects[i] != 0)
clReleaseMemObject(memObjects[i]);
}
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (context != 0)
clReleaseContext(context);
}
///
// main() for HelloWorld example
//
int main(int argc, char** argv)
{
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = { 0, 0, 0 };
cl_int errNum;
// Create an OpenCL context on first available platform
context = CreateContext();
if (context == NULL)
{
std::cerr << "Failed to create OpenCL context." << std::endl;
return 1;
}
// Create a command-queue on the first device available
// on the created context
commandQueue = CreateCommandQueue(context, &device);
if (commandQueue == NULL)
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Create OpenCL program from HelloWorld.cl kernel source
program = CreateProgram(context, device, "HelloWorld.cl");
if (program == NULL)
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Create OpenCL kernel
kernel = clCreateKernel(program, "hello_kernel", NULL);
if (kernel == NULL)
{
std::cerr << "Failed to create kernel" << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Create memory objects that will be used as arguments to
// kernel. First create host memory arrays that will be
// used to store the arguments to the kernel
float result[ARRAY_SIZE];
float a[ARRAY_SIZE];
float b[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++)
{
a[i] = (float)i;
b[i] = (float)(i * 2);
}
if (!CreateMemObjects(context, memObjects, a, b))
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Set the kernel arguments (result, a, b)
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error setting kernel arguments." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
size_t globalWorkSize[1] = { ARRAY_SIZE };
size_t localWorkSize[1] = { 1 };
// Queue the kernel up for execution across the array
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error queuing kernel for execution." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Read the output buffer back to the Host
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE,
0, ARRAY_SIZE * sizeof(float), result,
0, NULL, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error reading result buffer." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Output the result buffer
for (int i = 0; i < ARRAY_SIZE; i++)
{
std::cout << result[i] << " ";
}
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
运行结果
tips
在MacOS X 10.6中,OpenCL的头文件是存在OpenCL目录中,也就是
#include <OpenCL/opencl.h>- 1
但是在Windows下(以及可能所有其它的OS下),都是
#include <CL/cl.h>- 1
因此,如果想要让同一个程序,可以同时在各种OS下都能编译的话,在include头文件时,建议写成:
#ifdef __APPLE__
#include <OpenCL/opencl.h>
#else
#include <CL/cl.h>
#endif- 1
- 2
- 3
- 4
- 5
这样就可以同时在MacOS X 10.6下,以及其它的OS下使用。