网络爬虫名称:bilibili弹幕网视频日排行榜数据分析
网络爬虫爬取的内容:bilibili弹幕网视频日排行榜
设计方案概述:
实现思路:爬取网站html源代码,通过页面分析得到想要的数据位置,提取数据,之后数据可视化等操作
技术难点: html源码过于杂乱,难以提取数据
首先进行页面分析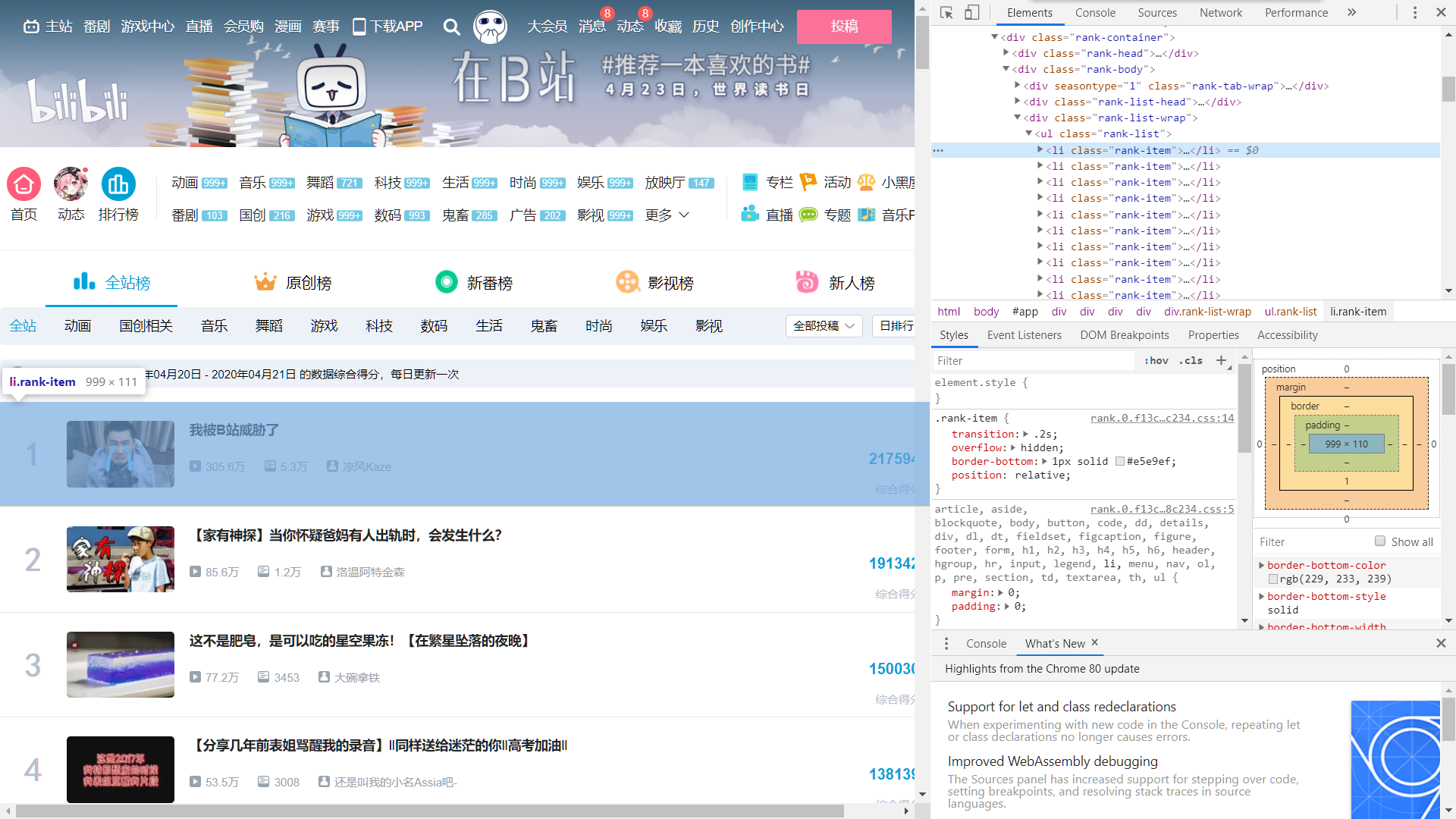
通过页面分析,我们得知我们需要的关键数据在"li"分支
将"li"分支展开,进一步分析
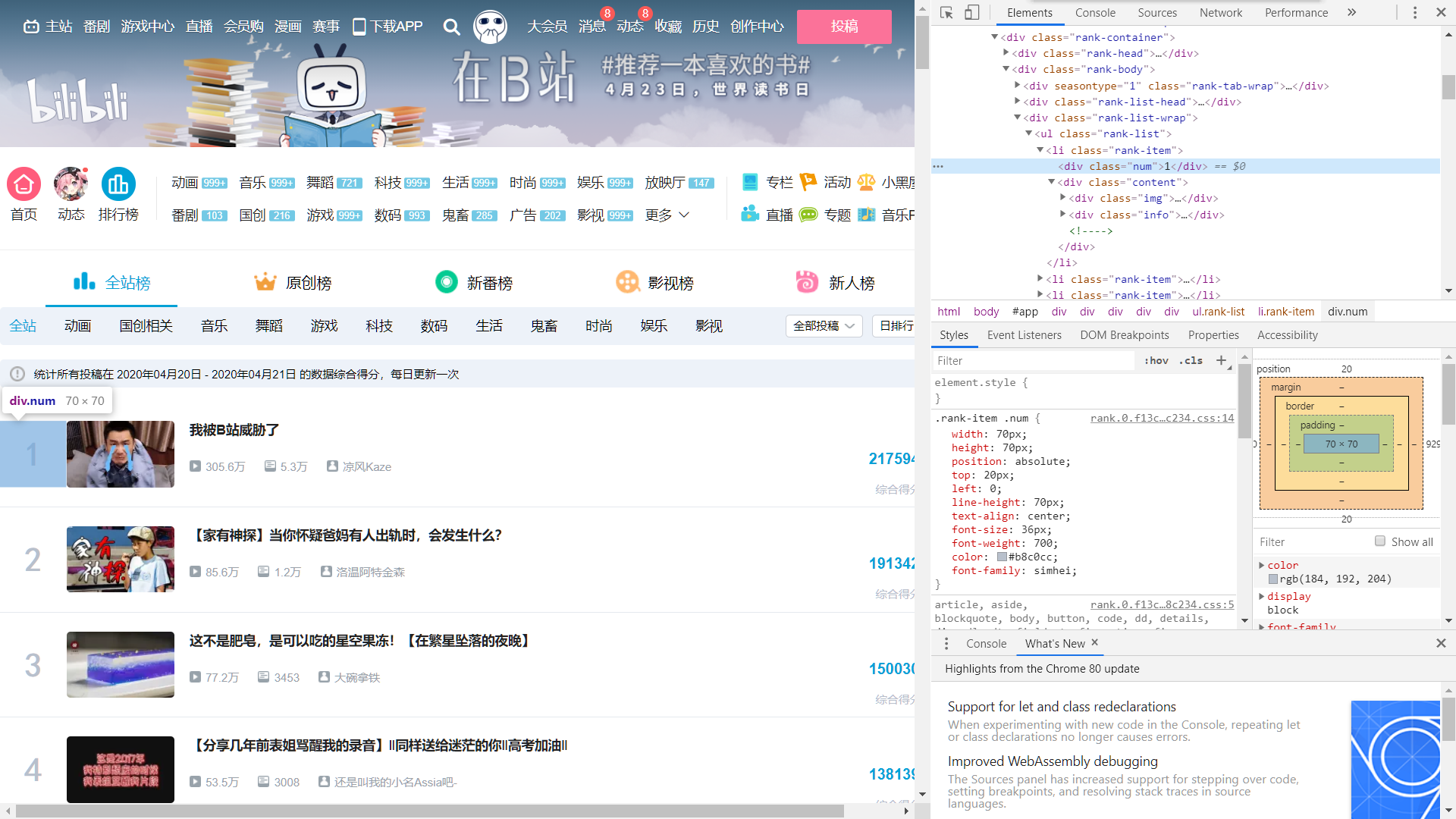

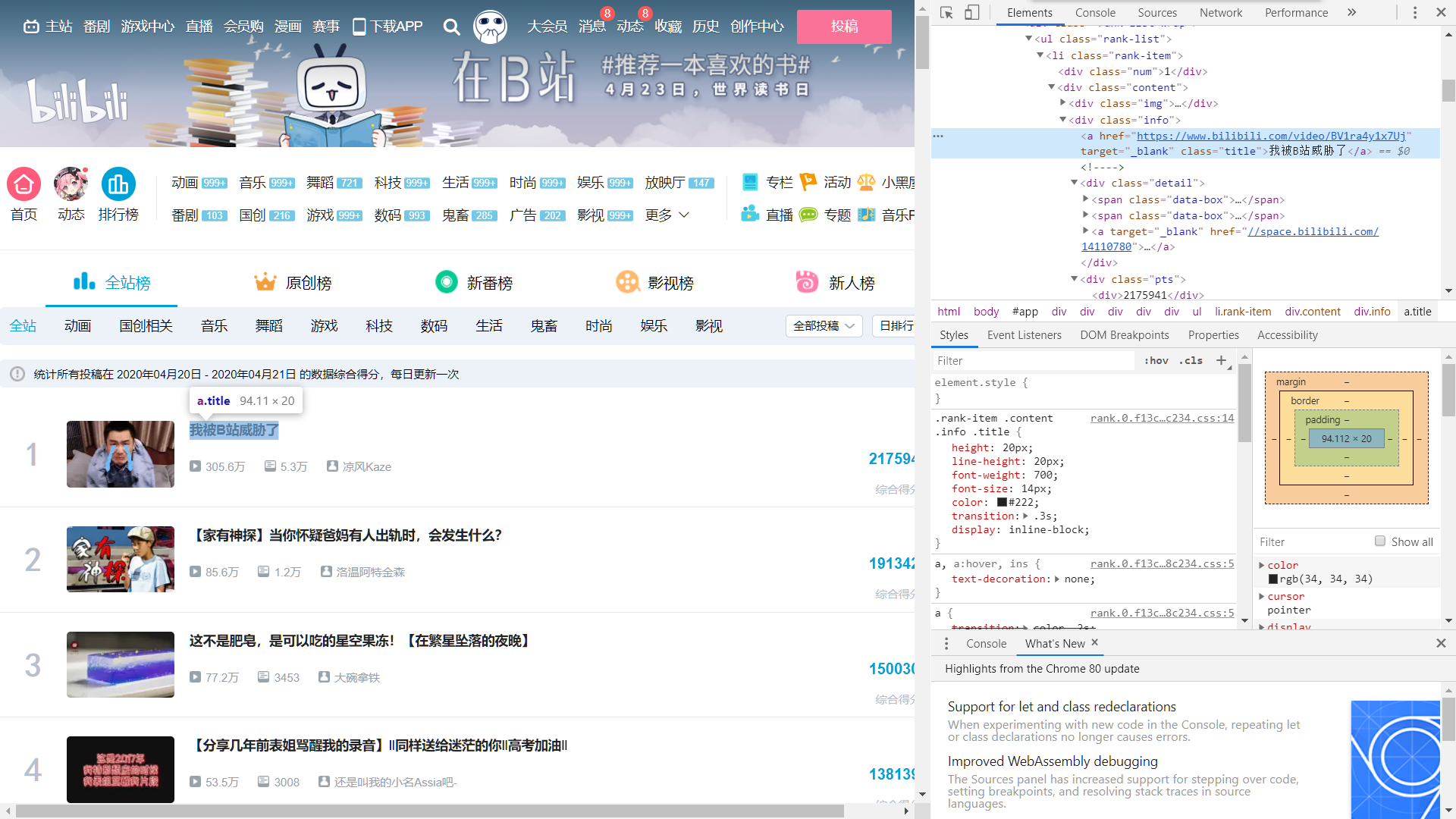

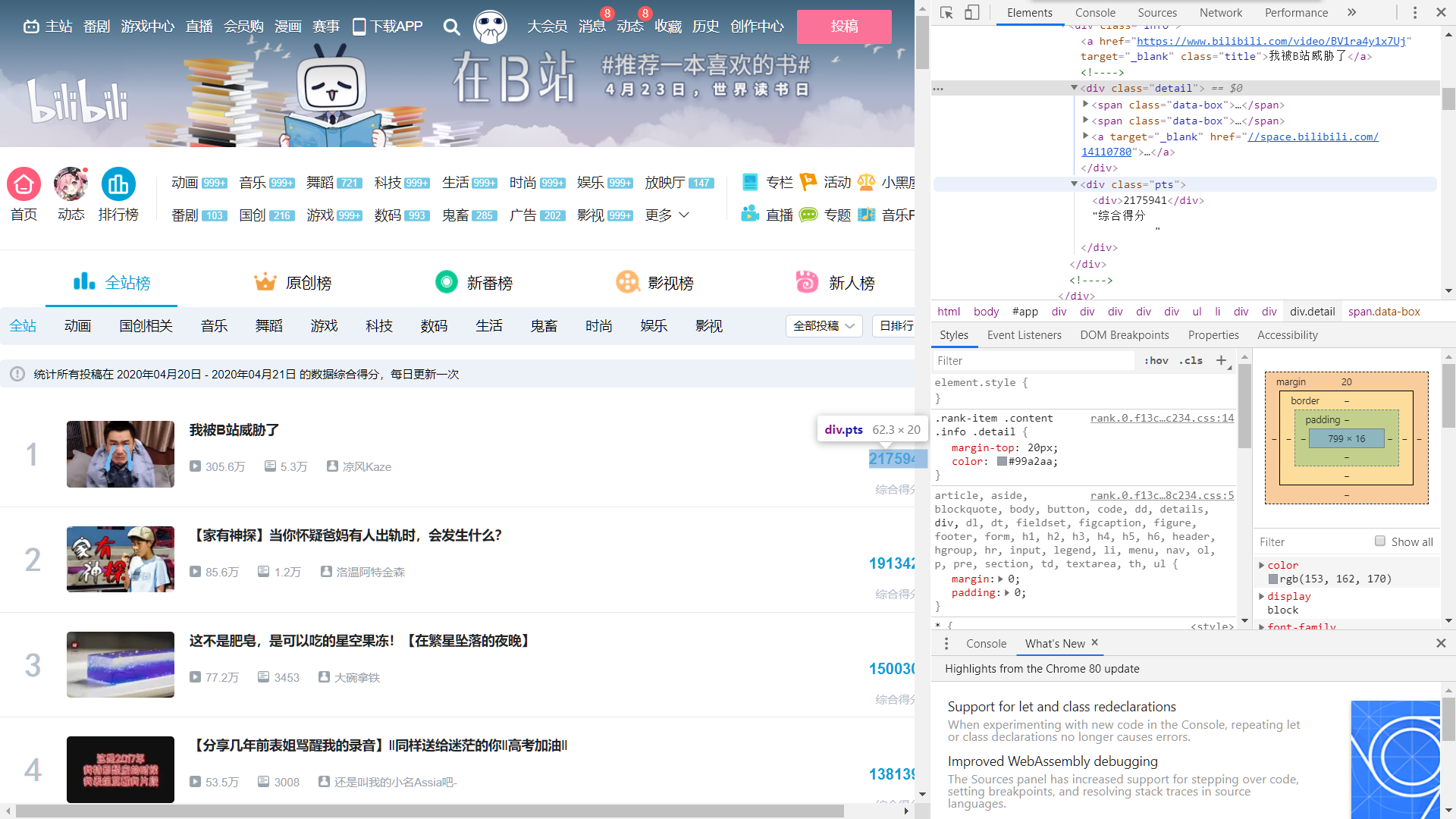
通过对"li"分支的分析,我们基本确定了播放量,弹幕数,综合得分等关键信息所在的位置
接下来开始爬取
import requests as rq from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt url = "https://www.bilibili.com/ranking/all/0/0/1" header = {"User-Agent":"Mozilla/5.0"} res = rq.get(url,headers=header,timeout=15) res.raise_for_status() res.encoding=res.apparent_encoding soup = BeautifulSoup(res.text)
使用requests库爬取,并通过BeautifulSoup库存放到变量Soup中,这里展示一下爬取到的html,可以看到是非常杂乱的

然后开始对数据进行提取,首先是获取视频标题,同样的,我输出一下提取到的标题
#获取视频标题 title = [] for dtitle in soup.find_all('img'): title.append(dtitle.get('alt'))

接下来同理,提取一些关键信息,因数据略大,就不输出展示了
#获取视频的播放量,弹幕数和UP主 cl_soup=soup.find_all(attrs={'class':'data-box'}) play_view_author = [] for cl_soup in cl_soup: play_view_author.append(cl_soup.text) play = play_view_author[0:300:3] #播放量 view = play_view_author[1:300:3] #弹幕数 author = play_view_author[2:300:3] #UP主 #获取视频的BV号 dBV = soup.find_all(attrs={'class':'title'}) link = [] for dBV in dBV: link.append(dBV.get('href')) for i in range(link.count(None)): link.remove(None) BV = [] for k in range(len(link)): BV.append(link[k][-12:]) #获取视频的综合得分 soup_pts=soup.find_all(attrs={'class':'pts'}) pts = [] for soup_pts in soup_pts: pts.append(eval(soup_pts.text[:-15]))
好的,现在关键信息已经获取完成,将其通过pandas库保存为csv表格方便稍后进行数据分析可视化调用
dt = {'排名':range(1,101),'标题':title,'播放量':play,'弹幕数':view,'综合得分':pts,'UP主':author,'BV号':BV} #创建字典
data = pd.DataFrame(dt) #以字典形式创建DataFrame
import datetime
date = datetime.datetime.now().strftime('%Y-%m-%d') #获取当前日期方便保存
data.to_csv('{}.csv'.format(date),index=False,header=True,encoding="utf-8-sig",mode="a") #保存为csv
此处应该注意,这里的保存时一定要写编码方式,否则很有可能保存的csv出现乱码的现象
接下来对数据进行清洗并可视化分析
读入csv文件
import pandas as pd import matplotlib.pyplot as plt from scipy.optimize import leastsq import numpy as np import datetime date = datetime.datetime.now().strftime('%Y-%m-%d') #获取当前日期 filename = '{}.csv'.format(date) colnames=["ranking","title","play","view","pts","author","BV"] data=pd.read_csv(filename,skiprows=1,names=colnames) plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文 plt.rcParams['axes.unicode_minus']=False #正常显示负号
由于从html中获得的播放量和弹幕数是带有"万"单位的,我们先对其进行转化
play = [] pl = list(data.play) for pl in pl: play.append(eval(pl[:-1])*10000) #将播放量转化为数字 view = [] vw = list(data.view) for i in vw: if i[-1]=="万": view.append(eval(i[:-1])*10000) else: view.append(eval(i)) #将弹幕数转化为数字
删除无用的列,并将转换好的播放量和弹幕数替换进去
del data["title"] del data["author"] del data["BV"] #删除无用列 play_s = pd.Series(play) view_s = pd.Series(view) data["play"] = play_s data["view"] = view_s #将转换好的弹幕数和播放量重新写入DataFrame中
重复值处理
data.duplicated() #重复值处理 #空值已在HTML处理时删除了,此处不再进行空值检测

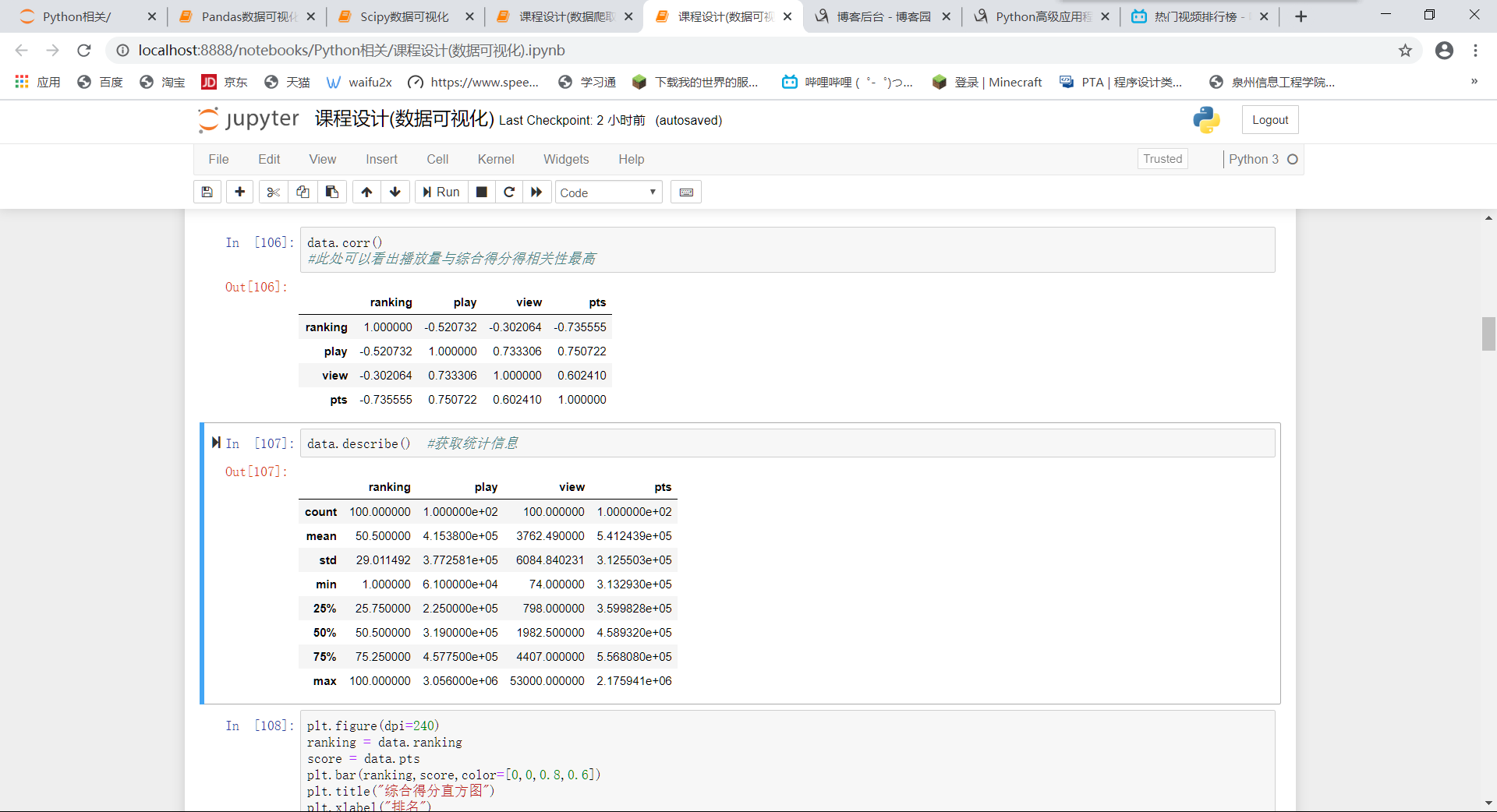
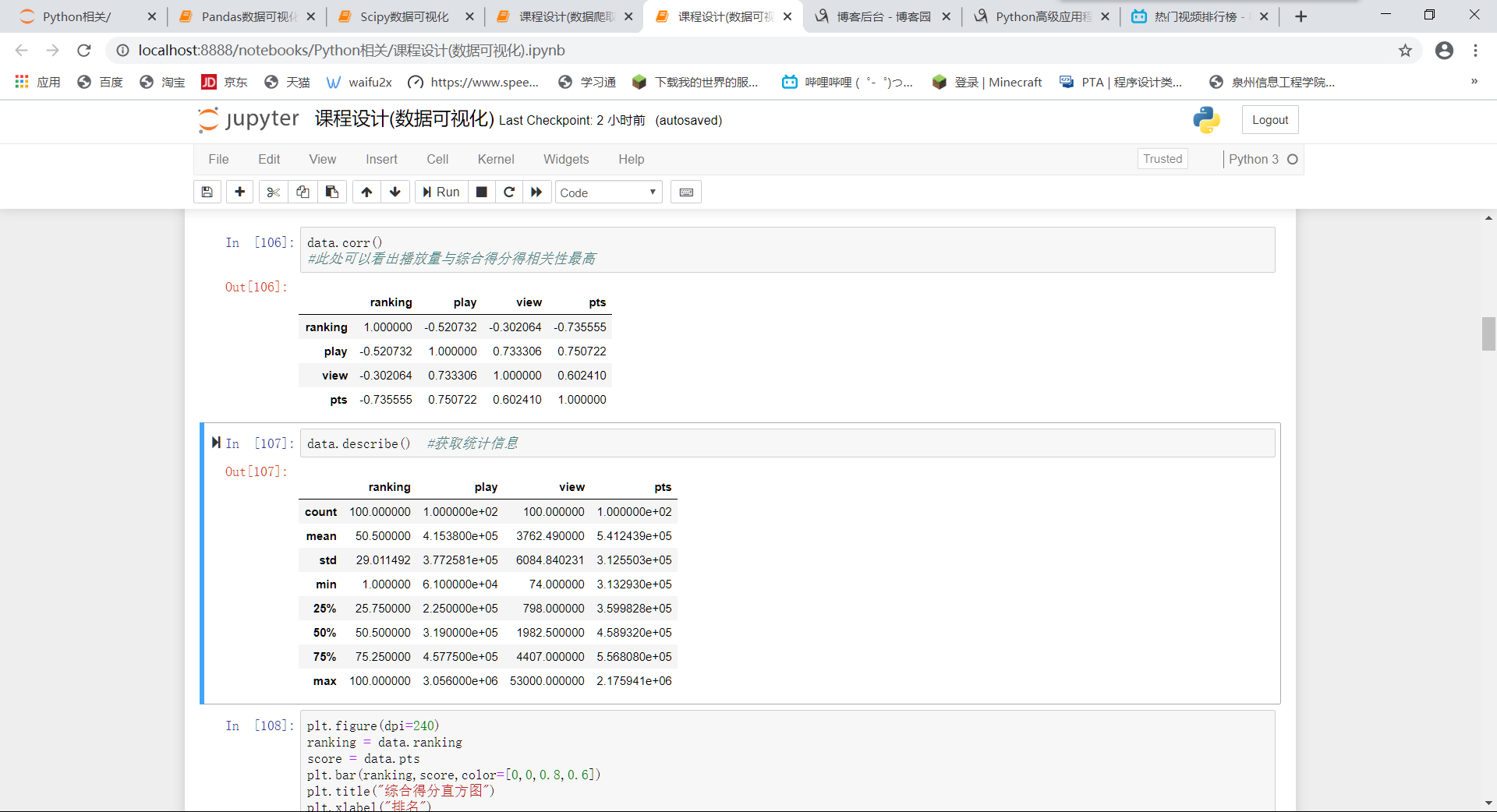
查看相关性以及统计数据
data.corr() #此处可以看出播放量与综合得分得相关性最高 data.describe() #获取统计信息
数据清洗到这里基本结束,接下来进行数据可视化分析
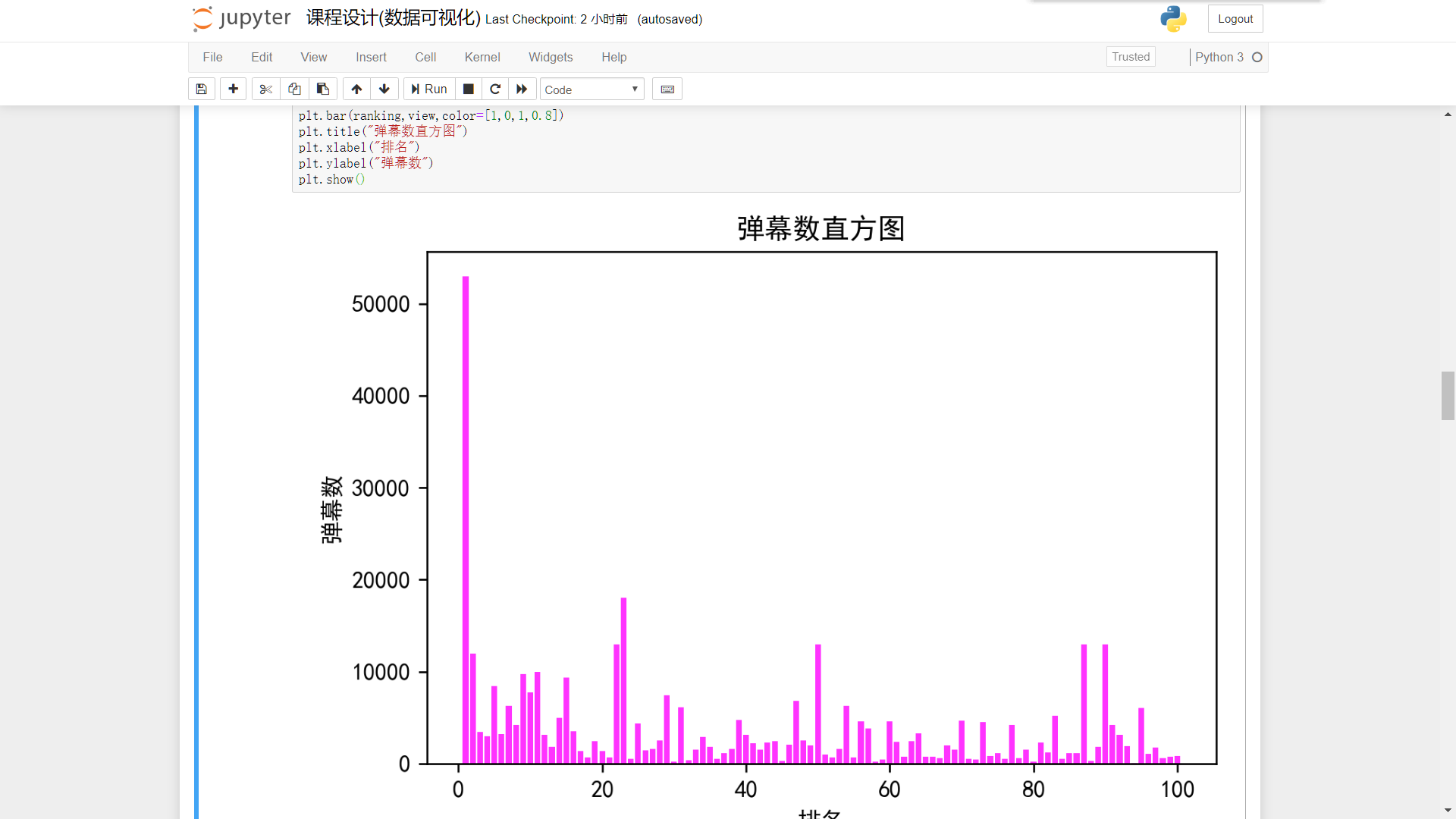
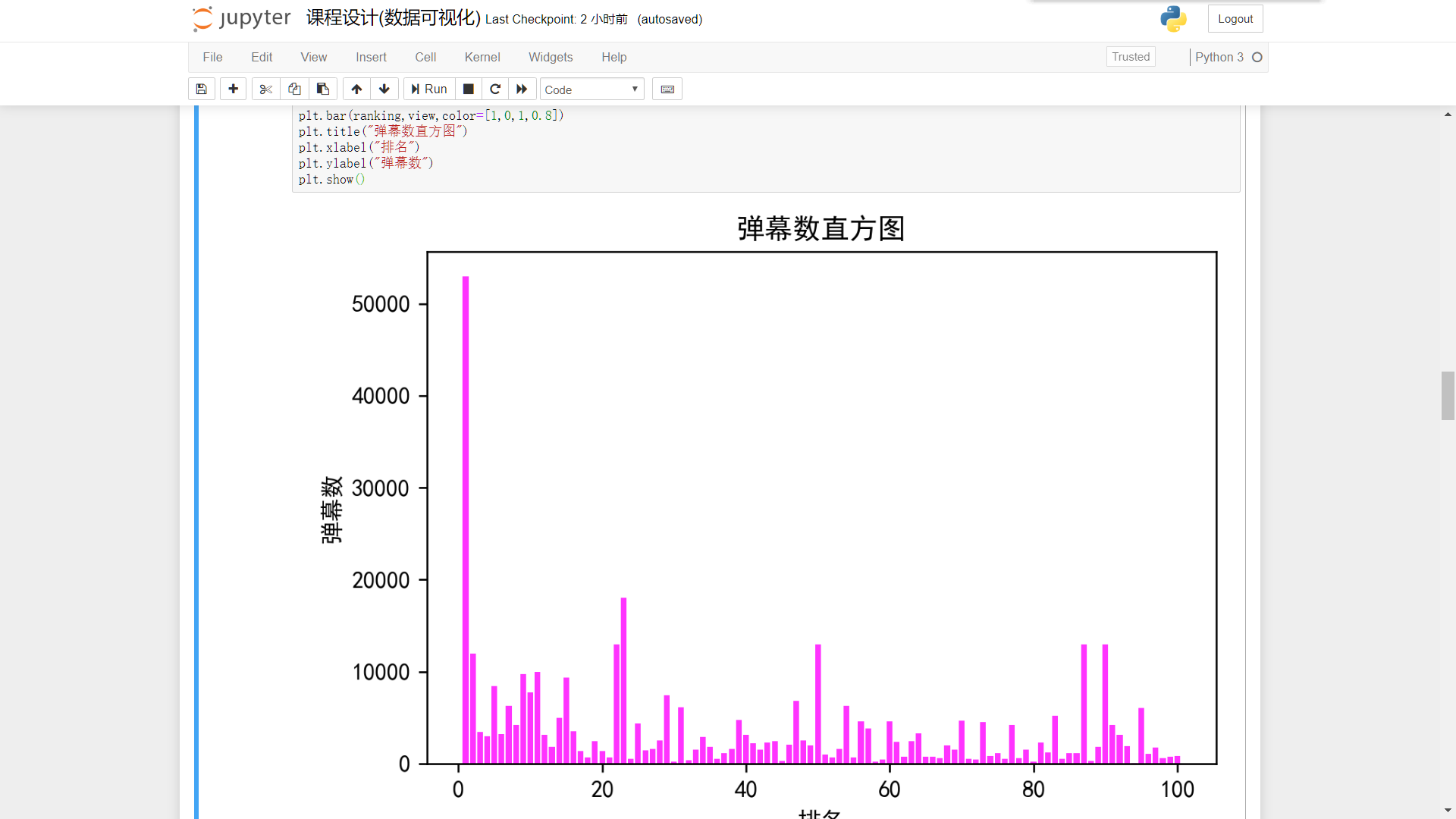
首先使用直方图对综合得分,播放量和弹幕数进行统计
综合得分
plt.figure(dpi=240) ranking = data.ranking score = data.pts plt.bar(ranking,score,color=[0,0,0.8,0.6]) plt.title("综合得分直方图") plt.xlabel("排名") plt.ylabel("综合得分") plt.show()

播放量:
plt.figure(dpi=240) plt.bar(ranking,play,color=[1,1,0]) plt.title("播放量直方图") plt.xlabel("排名") plt.ylabel("播放量") plt.show()

弹幕数:
plt.figure(dpi=240) plt.bar(ranking,view,color=[1,0,1,0.8]) plt.title("弹幕数直方图") plt.xlabel("排名") plt.ylabel("弹幕数") plt.show()
排名与播放量,弹幕数,综合得分的散点图和拟合直线
在此之前,先定义好回归方程函数以及将各列表转换为numpy数组
def ft(p,x): a,b,c=p return a*(x**2)+(b*x)+c def er_ft(p,x,y): return ft(p,x)-y play_np = np.array(play) score_np = np.array(score) view_np = np.array(view) ranking_np = np.array(ranking) p0=[2,3,4]
做好这个就可以开始了,首先是排名与综合得分
plt.figure(dpi=240) plt.scatter(ranking,score,label=u'样本数据',color=[0,0.6,0,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,score_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('综合得分散点图&拟合直线') plt.xlabel("排名") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show()
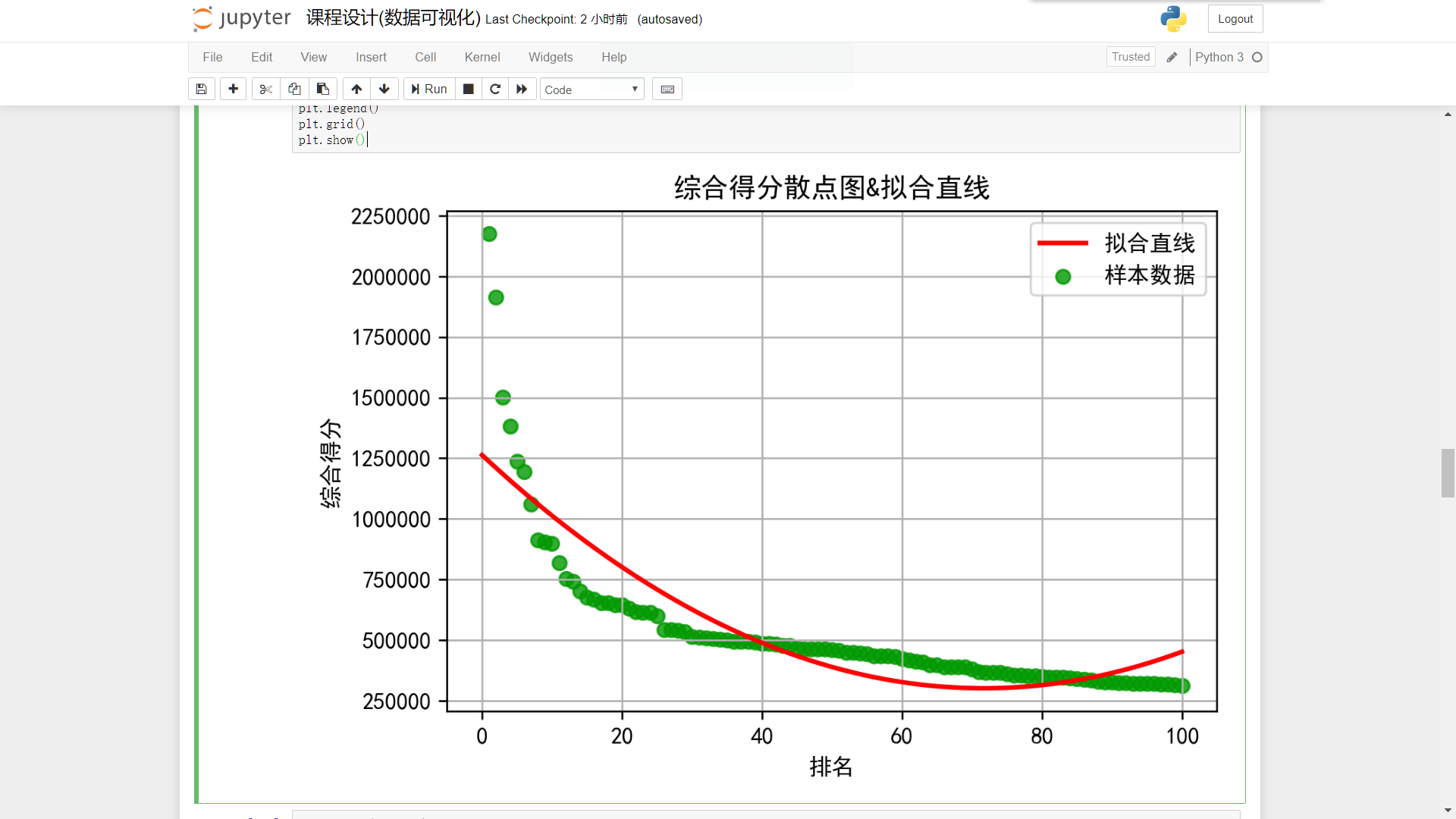
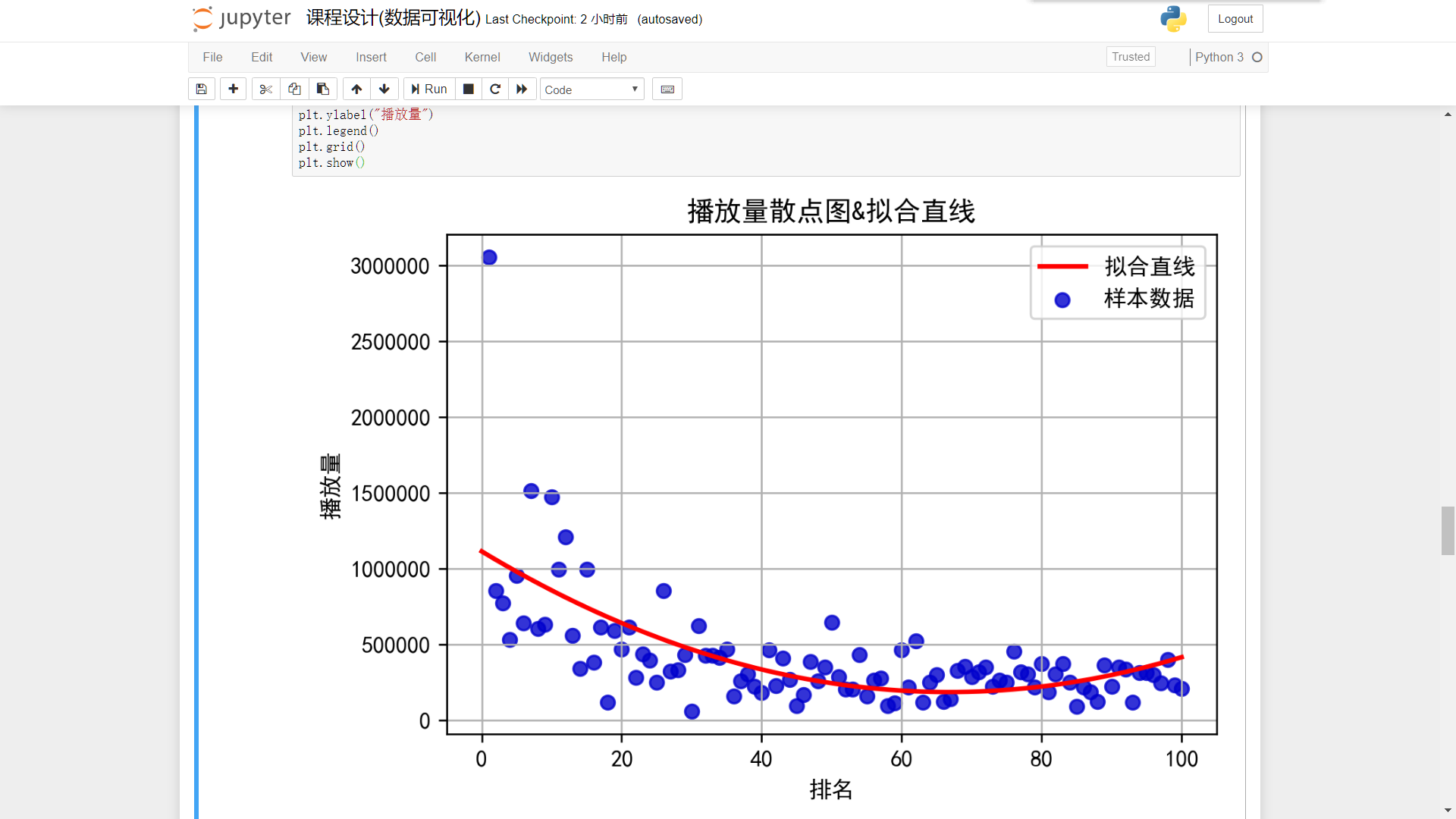
排名/播放量
plt.figure(dpi=240) plt.scatter(ranking,play,label=u'样本数据',color=[0,0,0.8,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,play_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('播放量散点图&拟合直线') plt.xlabel("排名") plt.ylabel("播放量") plt.legend() plt.grid() plt.show()
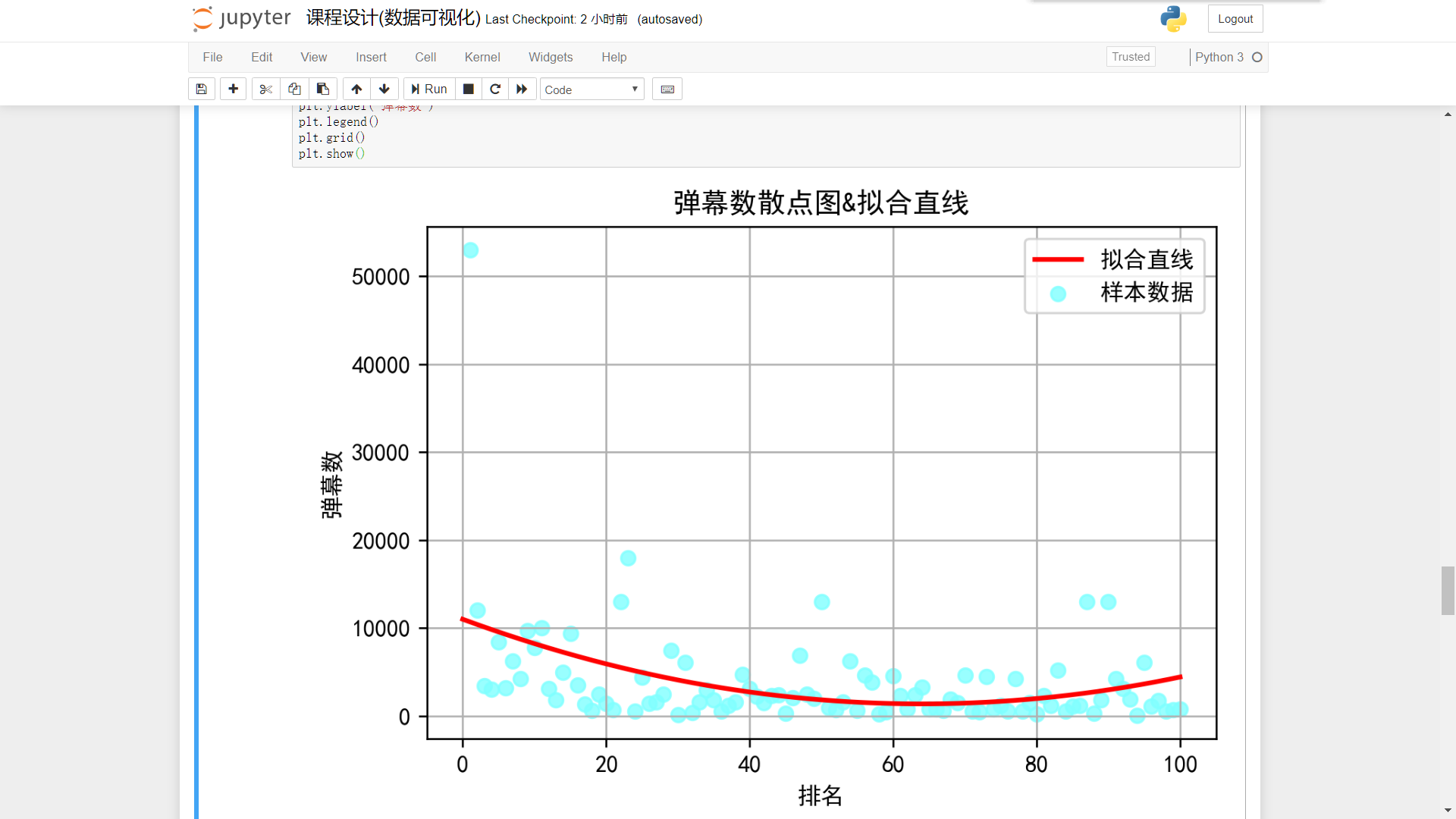
排名/弹幕数:
plt.figure(dpi=240) plt.scatter(ranking,view,label=u'样本数据',color=[0.5,1,1,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,view_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('弹幕数散点图&拟合直线') plt.xlabel("排名") plt.ylabel("弹幕数") plt.legend() plt.grid() plt.show()
接下来是综合得分,播放量,弹幕数三者直接的散点图和回归方程
弹幕数/播放量:
plt.figure(dpi=240) plt.scatter(play,view,label=u'样本数据',color=[0,0,0,0.6]) plt.title('弹幕数/播放量散点图&拟合直线') P=leastsq(er_ft,p0,args=(play_np,view_np)) a,b,c=P[0] x=np.linspace(0,3500000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("播放量") plt.ylabel("弹幕数") plt.legend() plt.grid() plt.show()

综合得分/播放量
plt.figure(dpi=240) plt.scatter(play,score,label=u'样本数据',color=[1,0.5,0,0.6]) plt.title('综合得分/播放量散点图&拟合直线') P=leastsq(er_ft,p0,args=(play_np,score_np)) a,b,c=P[0] x=np.linspace(0,3500000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("播放量") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show()
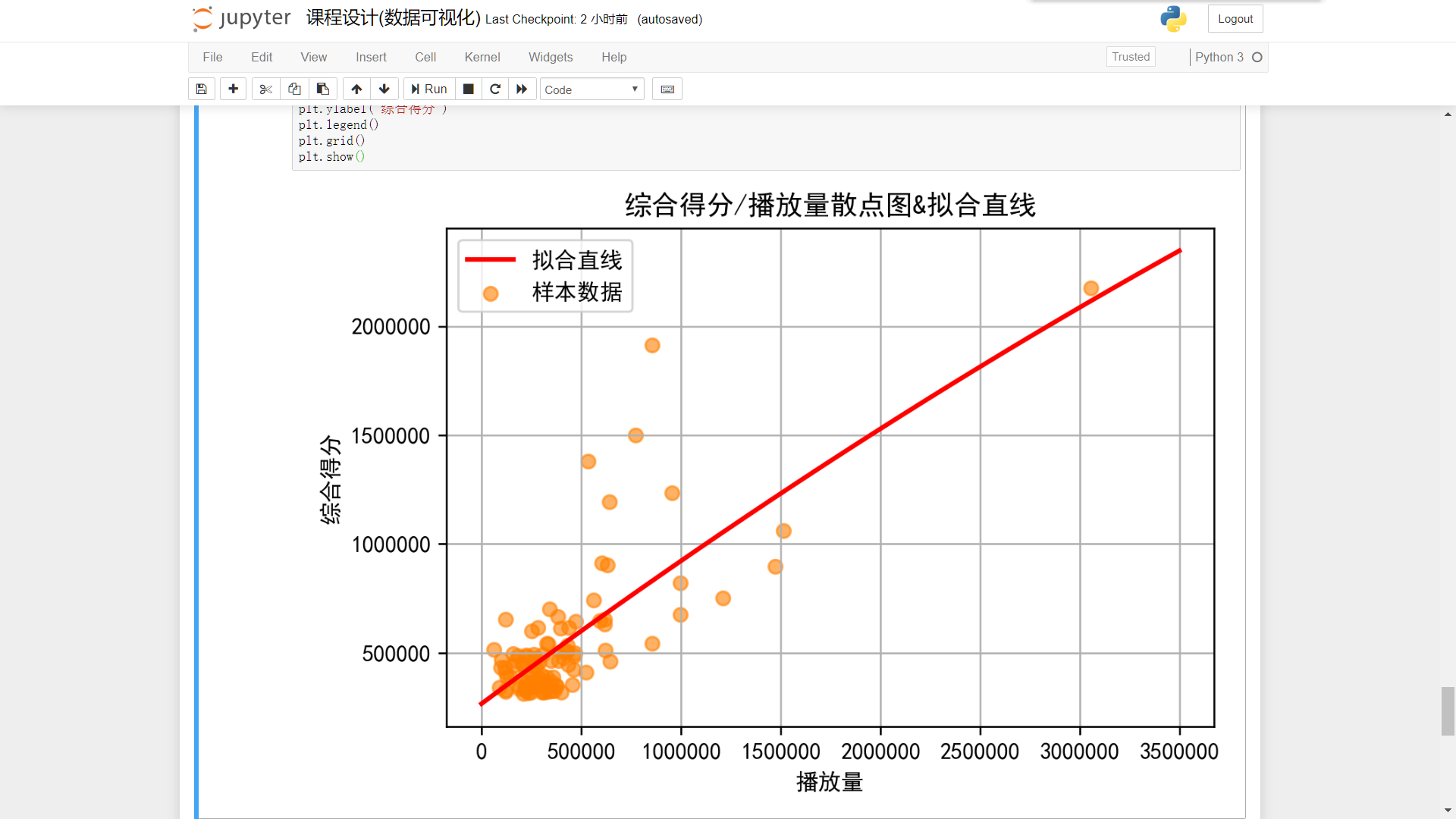
综合得分/弹幕数
plt.figure(dpi=240) plt.scatter(view,score,label=u'样本数据',color=[1,1,0,0.6]) plt.title('综合得分/弹幕数散点图&拟合直线') P=leastsq(er_ft,p0,args=(view_np,score_np)) a,b,c=P[0] x=np.linspace(0,55000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("弹幕数") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show()
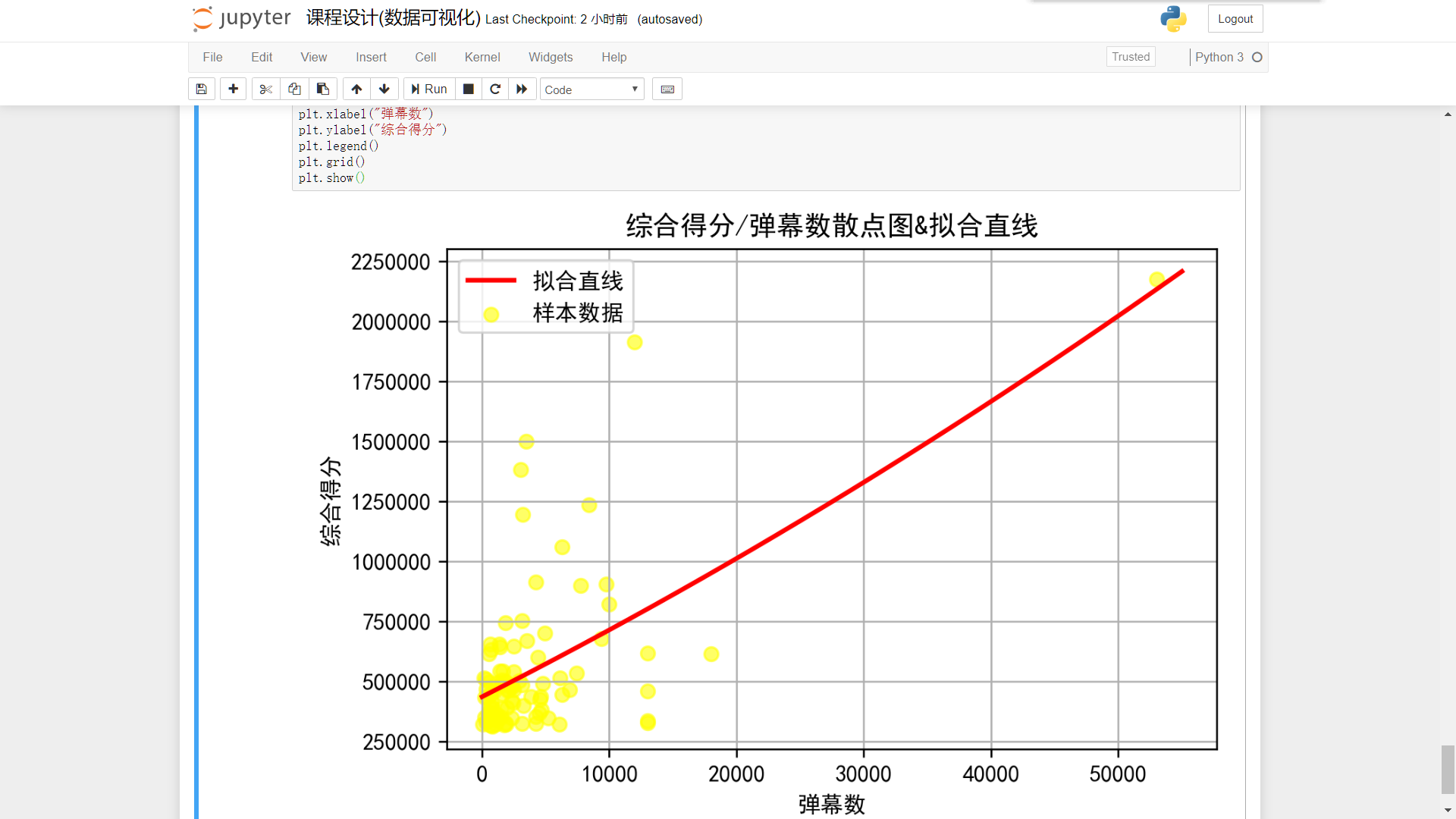
数据可视化基本完成
数据爬取提取部分代码汇总
import requests as rq from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt url = "https://www.bilibili.com/ranking/all/0/0/1" header = {"User-Agent":"Mozilla/5.0"} res = rq.get(url,headers=header,timeout=15) res.raise_for_status() res.encoding=res.apparent_encoding soup = BeautifulSoup(res.text) #获取视频标题 title = [] for dtitle in soup.find_all('img'): title.append(dtitle.get('alt')) #获取视频的播放量,弹幕数和UP主 cl_soup=soup.find_all(attrs={'class':'data-box'}) play_view_author = [] for cl_soup in cl_soup: play_view_author.append(cl_soup.text) play = play_view_author[0:300:3] #播放量 view = play_view_author[1:300:3] #弹幕数 author = play_view_author[2:300:3] #UP主 #获取视频的BV号 dBV = soup.find_all(attrs={'class':'title'}) link = [] for dBV in dBV: link.append(dBV.get('href')) for i in range(link.count(None)): link.remove(None) BV = [] for k in range(len(link)): BV.append(link[k][-12:]) #获取视频的综合得分 soup_pts=soup.find_all(attrs={'class':'pts'}) pts = [] for soup_pts in soup_pts: pts.append(eval(soup_pts.text[:-15])) dt = {'排名':range(1,101),'标题':title,'播放量':play,'弹幕数':view,'综合得分':pts,'UP主':author,'BV号':BV} #创建字典 data = pd.DataFrame(dt) #以字典形式创建DataFrame import datetime date = datetime.datetime.now().strftime('%Y-%m-%d') #获取当前日期方便保存 data.to_csv('{}.csv'.format(date),index=False,header=True,encoding="utf-8-sig",mode="a") #保存为csv
数据清洗以及可视化分析部分代码汇总
import pandas as pd import matplotlib.pyplot as plt from scipy.optimize import leastsq import numpy as np import datetime date = datetime.datetime.now().strftime('%Y-%m-%d') #获取当前日期 filename = '{}.csv'.format(date) colnames=["ranking","title","play","view","pts","author","BV"] data=pd.read_csv(filename,skiprows=1,names=colnames) plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文 plt.rcParams['axes.unicode_minus']=False #正常显示负号 play = [] pl = list(data.play) for pl in pl: play.append(eval(pl[:-1])*10000) #将播放量转化为数字 view = [] vw = list(data.view) for i in vw: if i[-1]=="万": view.append(eval(i[:-1])*10000) else: view.append(eval(i)) #将弹幕数转化为数字 del data["title"] del data["author"] del data["BV"] #删除无用列 play_s = pd.Series(play) view_s = pd.Series(view) data["play"] = play_s data["view"] = view_s #将转换好的弹幕数和播放量重新写入DataFrame中 data.duplicated() #重复值处理 #空值已在HTML处理时删除了,此处不再进行空值检测 data.corr() #此处可以看出播放量与综合得分得相关性最高 data.describe() #获取统计信息 plt.figure(dpi=240) ranking = data.ranking score = data.pts plt.bar(ranking,score,color=[0,0,0.8,0.6]) plt.title("综合得分直方图") plt.xlabel("排名") plt.ylabel("综合得分") plt.show() plt.figure(dpi=240) plt.bar(ranking,play,color=[1,1,0]) plt.title("播放量直方图") plt.xlabel("排名") plt.ylabel("播放量") plt.show() plt.figure(dpi=240) plt.bar(ranking,view,color=[1,0,1,0.8]) plt.title("弹幕数直方图") plt.xlabel("排名") plt.ylabel("弹幕数") plt.show() def ft(p,x): a,b,c=p return a*(x**2)+(b*x)+c def er_ft(p,x,y): return ft(p,x)-y play_np = np.array(play) score_np = np.array(score) view_np = np.array(view) ranking_np = np.array(ranking) p0=[2,3,4] plt.figure(dpi=240) plt.scatter(ranking,score,label=u'样本数据',color=[0,0.6,0,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,score_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('综合得分散点图&拟合直线') plt.xlabel("排名") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show() plt.figure(dpi=240) plt.scatter(ranking,play,label=u'样本数据',color=[0,0,0.8,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,play_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('播放量散点图&拟合直线') plt.xlabel("排名") plt.ylabel("播放量") plt.legend() plt.grid() plt.show() plt.figure(dpi=240) plt.scatter(ranking,view,label=u'样本数据',color=[0.5,1,1,0.8]) P=leastsq(er_ft,p0,args=(ranking_np,view_np)) a,b,c=P[0] x=np.linspace(0,100,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.title('弹幕数散点图&拟合直线') plt.xlabel("排名") plt.ylabel("弹幕数") plt.legend() plt.grid() plt.show() plt.figure(dpi=240) plt.scatter(play,view,label=u'样本数据',color=[0,0,0,0.6]) plt.title('弹幕数/播放量散点图&拟合直线') P=leastsq(er_ft,p0,args=(play_np,view_np)) a,b,c=P[0] x=np.linspace(0,3500000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("播放量") plt.ylabel("弹幕数") plt.legend() plt.grid() plt.show() plt.figure(dpi=240) plt.scatter(play,score,label=u'样本数据',color=[1,0.5,0,0.6]) plt.title('综合得分/播放量散点图&拟合直线') P=leastsq(er_ft,p0,args=(play_np,score_np)) a,b,c=P[0] x=np.linspace(0,3500000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("播放量") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show() plt.figure(dpi=240) plt.scatter(view,score,label=u'样本数据',color=[1,1,0,0.6]) plt.title('综合得分/弹幕数散点图&拟合直线') P=leastsq(er_ft,p0,args=(view_np,score_np)) a,b,c=P[0] x=np.linspace(0,55000,1000) y=a*(x**2)+(b*x)+c plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2) plt.xlabel("弹幕数") plt.ylabel("综合得分") plt.legend() plt.grid() plt.show()
结论:数据可视化分析可以得知,弹幕数与播放量相关性并不高,但是综合得分是由播放量和弹幕数共同影响的
程序设计小结:此次程序设计重难点在于对html的数据提取,以前看到一大片密密麻麻的html就感到头疼,而通过此次程序设计,我能更加敢于面对庞大杂乱的数据;而在程序设计过程中出现的各种问题得到解决都给我带来一定的成就感,也让我对Python这门编程语言有了更深层的了解.