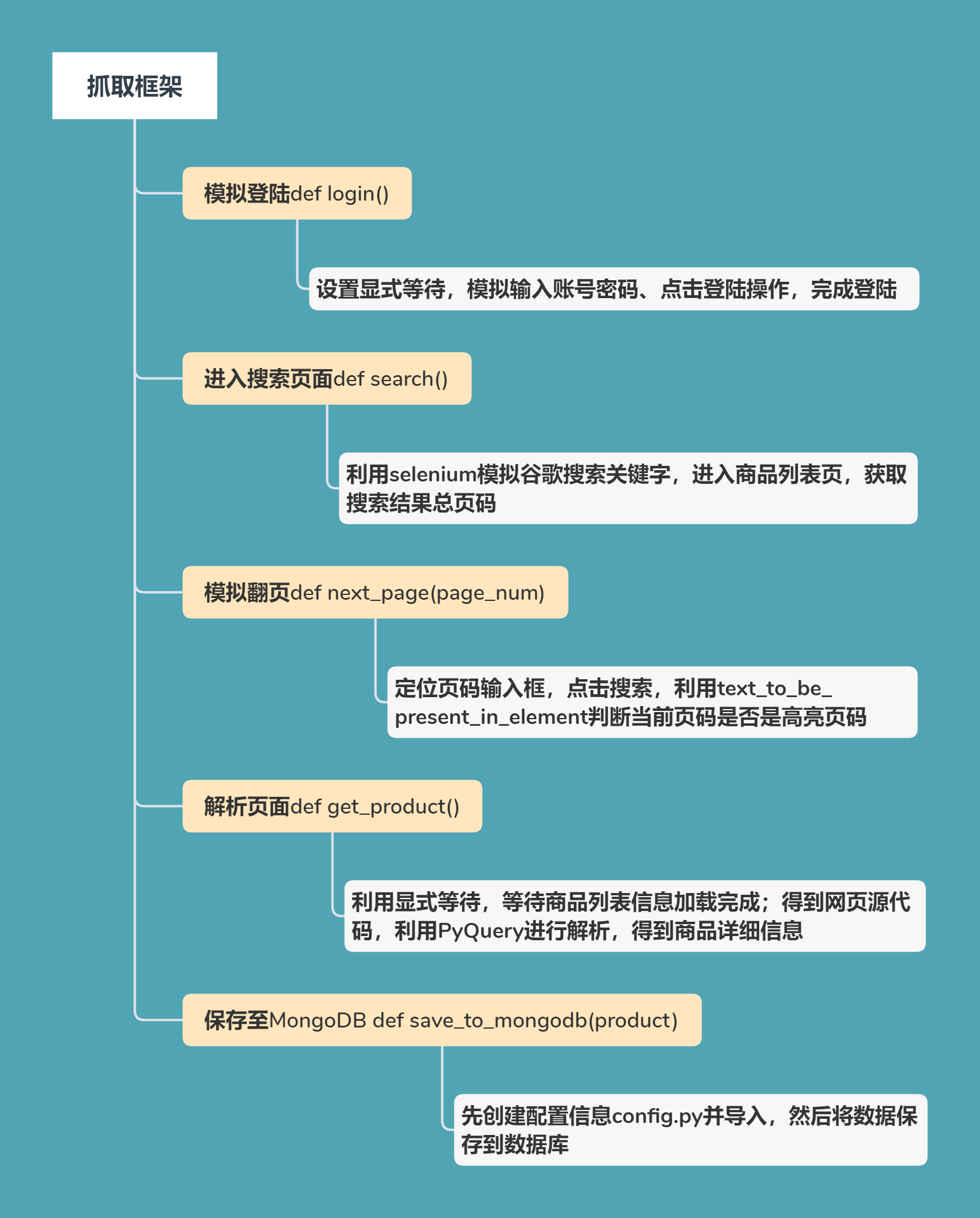
在崔庆才老师的视频讲解基础上,添加了模拟登陆步骤:
1 from selenium import webdriver
2 from selenium.webdriver.common.by import By
3 from selenium.webdriver.support.wait import WebDriverWait
4 from selenium.webdriver.support import expected_conditions as EC
5 from pyquery import PyQuery as pq
6 import re
7 import pymongo
8 from config import *
9
10 # 连接数据库,并申明数据库
11 client = pymongo.MongoClient(MONGO_URL)
12 db = client[MONGO_DB]
13
14 browser = webdriver.Chrome()
15 wait = WebDriverWait(browser, 10) # 设置explicily wait
16
17
18 # 模拟登陆淘宝
19 def login():
20 browser.get('https://login.taobao.com/member/login.jhtml?spm=a21bo.2017.754894437.1.5af911d9lO6yRD&f=top&redirectURL=https%3A%2F%2Fwww.taobao.com%2F')
21 input1 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-id')))
22 input1.send_keys('淘宝网账号')
23 input2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-password')))
24 input2.send_keys('淘宝网密码')
25 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#login-form > div.fm-btn > button')))
26 submit.click()
27
28
29 # 模拟进入搜索页
30 def search():
31 try:
32 # 定位搜索输入框,并模拟输入搜索关键字
33 input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#q')))
34 input.send_keys('美食')
35 # 定位搜索按钮,并模拟点击
36 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')))
37 submit.click()
38 # 定位搜索页底部“共100页”
39 total_page = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')))
40 # 获取第一页商品信息
41 get_products()
42 return total_page.text
43 except TimeoutError:
44 # 若超时,就重新搜索
45 return search()
46
47 # 模拟翻页
48 def next_page(page_num):
49 try:
50 # 定位底部的页码输入框
51 input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))
52 input.clear()
53 input.send_keys(page_num)
54 # 定位底部的页码确定按钮
55 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
56 submit.click()
57 # 判断page_num是否是目前高亮的页码按钮文本
58 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_num)))
59 # 获取第二页以后的商品信息
60 get_products()
61 except TimeoutError:
62 next_page(page_num)
63
64
65 # 获取商品信息
66 def get_products():
67 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
68 # 获取网页源代码
69 html = browser.page_source
70 doc = pq(html)
71 items = doc('#mainsrp-itemlist .items .item').items() # 返回通过CSS选择器过滤的生成器对象
72 for item in items: # item为单个商品的PyQuery对象
73 product = {
74 'image': item.find('.pic .img').attr('src'),
75 'price': item.find('.price').text(),
76 'deal_num': item.find('.deal-cnt').text()[:-3],
77 'title': item.find('.title').text(),
78 'shop': item.find('.shop').text(),
'location': item.find('.location').text()
79 }
80 save_to_mongodb(product)
81
82 # 保存到mongodb数据库
83 def save_to_mongodb(result):
84 try:
85 if db[MONGO_TABLE].insert_one(result):
86 print('存储成功', result)
87 except Exception:
88 print('存储失败', result)
89
90
91 def main():
92 login()
93 total_page = search()
94 total_page = int(re.compile('(d+)').search(total_page).group(1))
95 for i in range(2, total_page+1):
96 next_page(i)
97 browser.close()
98
99
100 if __name__ == '__main__':
101 main()
顺利抓取到4365条商品信息:
