目标url:https://book.douban.com/tag/?view=type&icn=index-sorttags-all
目的:抓取所有标签名称(tag_name),标签链接(tag_url),标签下的书籍数量(tag_book_num)

先创建一个config.py文件,设置mongpdb的一些配置信息:

抓取代码如下:
1 import requests
2 from requests.exceptions import RequestException
3 from bs4 import BeautifulSoup
4 import pymongo
5 from config import *
6
7 client = pymongo.MongoClient(MONGO_URL) # 申明连接对象
8 db = client[MONGO_DB] # 申明数据库
9
10 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
11
12
13 def get_tag_url():
14 response = requests.get('https://book.douban.com/tag/?view=type&icn=index-sorttags-all', headers=headers)
15 soup = BeautifulSoup(response.text, 'lxml')
16 results = soup.find_all('table', {'class': 'tagCol'})
17 for result in results:
18 pattern = re.compile('<td><a href="(.*?)">(.*?)</a><b>(.*?)</b></td>')
19 tag_name_list = re.findall(pattern, str(result))
20 for tag_name in tag_name_list:
21 yield {
22 'tagname': tag_name[1], # 返回标签名称
23 'tag_url': 'https://book.douban.com/' + tag_name[0], # 返回标签对应链接
24 'tag_book_num': tag_name[2] # 返回标签中对应的书籍数量
25 }
26
27
28 # 将所有tagname、tag_url、tag_book_num存到mongodb中
29 def save_to_mongo(result):
30 if db[MONGO_TABLE].insert_one(result):
31 print('存储到mongodb成功', result)
32 return True
33 return False
34
35
36 def main():
37 results = get_tag_url()
38 for result in results:
39 save_to_mongo(result)
40
41
42 if __name__ == '__main__':
43 main()
顺利将145个标签保存到数据库啦!
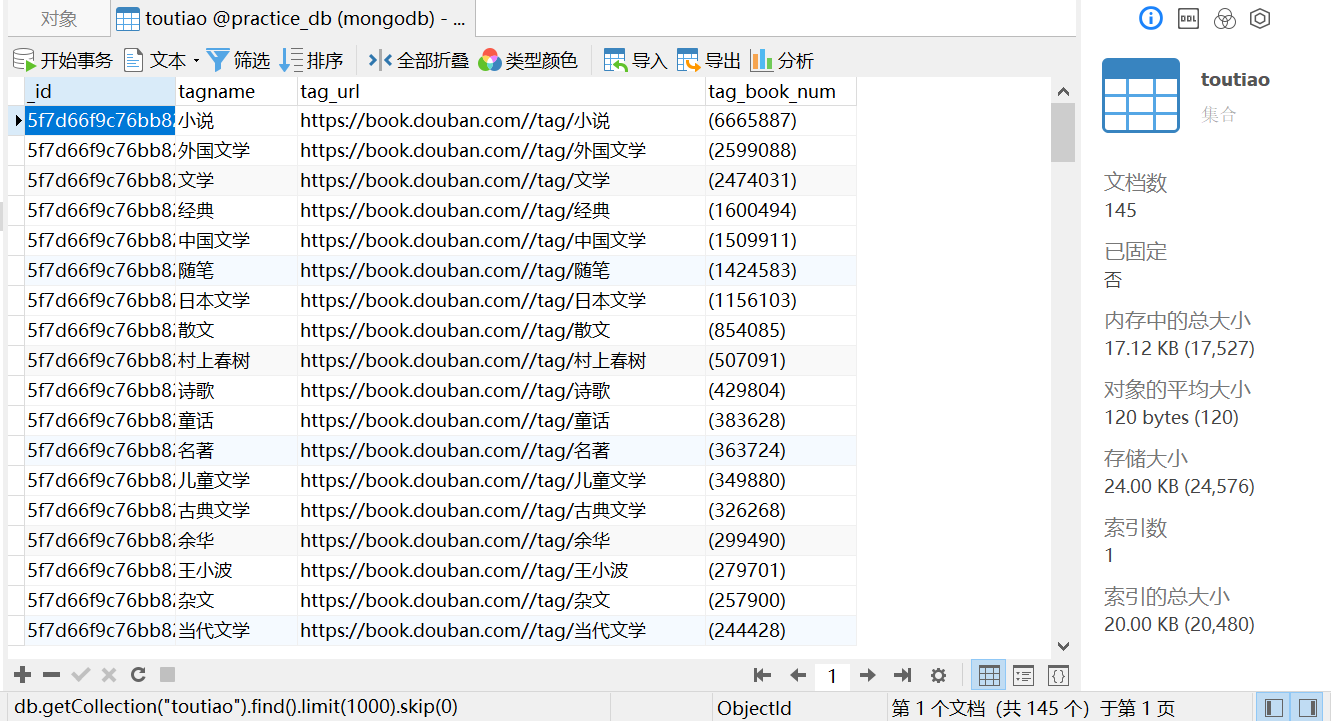
下一步计划就是抓取每个标签下的书籍信息(书名,作者,出版社,出版日期,价格,评价人数,评分)