hashcode() 与 equals() 应一起重写,在HashMap 会先调用hash(key.hashcode()) 找到对应的entry数组位置 (一般初始是16,2^x,rehash后会翻倍),再在这个entry链表上equals判断是否存在相同元素。
所以当重写equals时没保证hashcode出的值的一致性,会导致hash到不同的数组位置 插入重复的元素。
※String类的hashcode是通过各个位置的char的ascii码计算Σx*31^(len-i)得到的※
HashSet通过HashMap实现,其中每次插入的value值都是一个Object的常量。iterator()返回map的hashmap的keyiterator。
HashMap成员变量
1 //默认初始化map的容量:16 2 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 3 //map的最大容量:2^30 4 static final int MAXIMUM_CAPACITY = 1 << 30; 5 //默认的填充因子:0.75,能较好的平衡时间与空间的消耗 6 static final float DEFAULT_LOAD_FACTOR = 0.75f; 7 //将链表(桶)转化成红黑树的临界值 8 static final int TREEIFY_THRESHOLD = 8; 9 //将红黑树转成链表(桶)的临界值 10 static final int UNTREEIFY_THRESHOLD = 6; 11 //转变成树的table的最小容量,小于该值则不会进行树化 12 static final int MIN_TREEIFY_CAPACITY = 64; 13 //上图所示的数组,长度总是2的幂次 14 transient Node<K,V>[] table; 15 //map中的键值对集合 16 transient Set<Map.Entry<K,V>> entrySet; 17 //map中键值对的数量 18 transient int size; 19 //用于统计map修改次数的计数器,用于fail-fast抛出ConcurrentModificationException 20 transient int modCount; 21 //大于该阈值,则重新进行扩容,threshold = capacity(table.length) * load factor 22 int threshold; 23 //填充因子 24 final float loadFactor;
长度为2^n是取模运算快,只需要&(size-1)即可
jdk1.8中 桶中 如果链表长度超过8 会重拍成红黑树,依照hashcode值排序
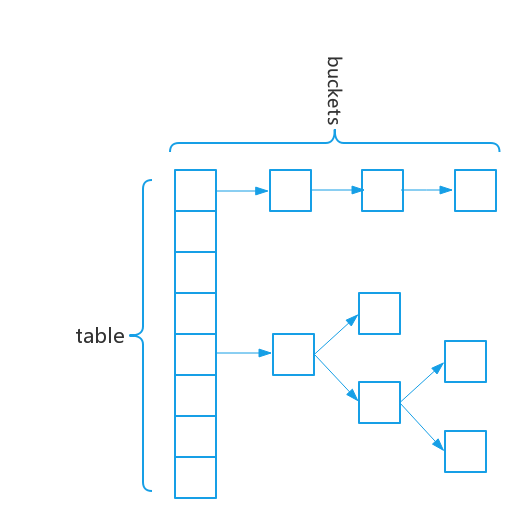
总数量超过threshold = capacity * loadfactor 会进行resize重拍。需要遍历整个table[],性能较低,如果提前知道map大小,最好在初始化的时候提前设置。
在使用iterator迭代器遍历(for each)的时候如果在遍历途中删除map中元素,会抛出ConcurrentModificationException(!!删除倒数第二个不会报错),最好使用iterator内部的删除方法iterator.remove()
hashmap允许key和value为null,线程不安全