我偶然听说sqlsugar的性能比dapper强。对此我表示怀疑(由于我一直使用的dapper存在偏见吧),于是自己测试了sqlsugar、freesql、dapper发现他们的给我的结果是
sqlsugar>dapper>freesql(这里并不是黑那个orm,毕竟不同orm功能不同,底层实现不同,适用场景不同性能当然不同)。这让我很吃惊,dapper(号称orm king)一个执行sql的映射器,比不了基于linq语法的sqlsugar。同时也让我感到高兴,我高兴的是:orm的性能肯定还有提升的空间。
于是我便开始研究它们并着手编写。最终以一千行左右的代码量实现了dapper的基本映射功能,性能真正意义接近ado.net
对比于dapper的底层存在拆装箱操作(我的没有,请看IL),强制类型转换,dapper内置各种缓存(缓存就要考虑并发安全,就要用lock),许多功能并不是我们所需要的,一些功能又是我们迫切需要的,dapper有些定制化功能我们要查阅很多资料才能实现。浪费我们宝贵的时间,dapper对匿名类型支持并不好,这阻碍的我的另一个框架dapper.common(dapper的linq实现方案,将来要移植到sqlcommon),我让作者改一下,支持一下,作者认为linq映射也不是dapper所需要的功能,不予支持。
自己动手丰衣足食,那么我们完全可以自己编写一套。
性能测试

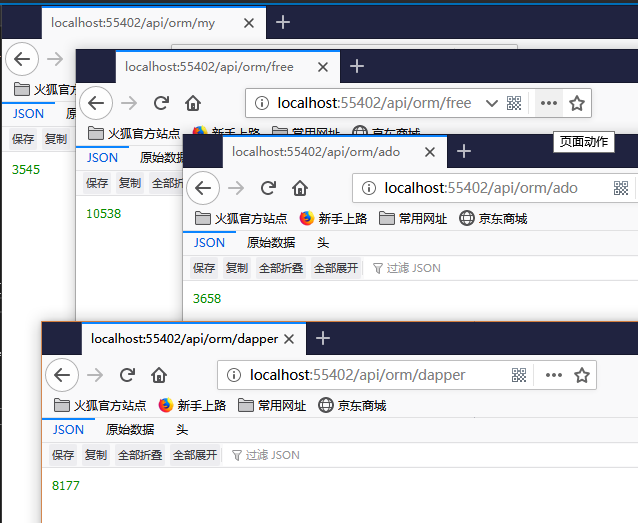
下面进行简要实现:
完整源码地址:https://github.com/1448376744/SqlCommon
nuget也发布了v1.0.0
我们要如何实现?我们只需要实现DataReader对象转实体类。我们需要用IL来动态创建下面的函数
public T TypeConvert<T>(IDataReader reader) { var entity = new T(); var index1 = reader.GetOrdinal("FieldName1"); entity.FieldName1 = reader.GetString(index1); var index2 = reader.GetOrdinal("FieldName2"); entity.FieldName2 = reader.GetString(index2); return entity; }
我们可以创建这样的函数,通过IL来动态创建,大致的过程
创建实体类型->判断实体类型中的属性在reader中是否存在->如果存在则对该字段赋值
我们定义一个接口,这个接口规范属性和字段的映射规则,类型转换规则,构造器规则,构造参数映射规则(可以有不同实现)
public interface ITypeMapper { //根据字段信息,返回C#属性 MemberInfo FindMember(MemberInfo[] properties, DbDataInfo dataInfo); //根据C#字段属性返回转换函数 MethodInfo FindConvertMethod(Type csharpType); //处理匿名类型 DbDataInfo FindConstructorParameter(DbDataInfo[] dataInfos, ParameterInfo parameterInfo); //根据目标类型返回构造器 ConstructorInfo FindConstructor(Type csharpType); }
我们编写一个默认实现规则
public class TypeMapper : ITypeMapper { //查找构造器 public ConstructorInfo FindConstructor(Type csharpType) { var constructor = csharpType.GetConstructor(Type.EmptyTypes); if (constructor == null) { var constructors = csharpType.GetConstructors(); constructor = constructors.Where(a => a.GetParameters().Length == constructors.Max(s => s.GetParameters().Length)).FirstOrDefault(); } return constructor; }
//构造参数映射规则 public DbDataInfo FindConstructorParameter(DbDataInfo[] dataInfos, ParameterInfo parameterInfo) { foreach (var item in dataInfos) { if (item.DataName.Equals(parameterInfo.Name, StringComparison.OrdinalIgnoreCase)) { return item; } else if (SqlMapper.MatchNamesWithUnderscores && item.DataName.Replace("_", "").Equals(parameterInfo.Name, StringComparison.OrdinalIgnoreCase)) { return item; } } return null; }
//查找属性 public MemberInfo FindMember(MemberInfo[] properties, DbDataInfo dataInfo) { foreach (var item in properties) { if (item.Name.Equals(dataInfo.DataName, StringComparison.OrdinalIgnoreCase)) { return item;//忽略大小写 } else if (SqlMapper.MatchNamesWithUnderscores && item.Name.Equals(dataInfo.DataName.Replace("_", ""), StringComparison.OrdinalIgnoreCase)) { return item;//忽略下划线 } } return null; }
//查找类型转换规则 public MethodInfo FindConvertMethod(Type csharpType) { if (csharpType == typeof(int) || Nullable.GetUnderlyingType(csharpType) == typeof(int)) { return csharpType == typeof(int) ? DataConvertMethod.ToIn32Method : DataConvertMethod.ToIn32NullableMethod; } } }
然后实现一下DataConvertMethod(FindConvertMethod需要)这里是缩减版
//你可以在这里编写json类型的转换策略,如果你的属性中有JObject类型的话
public static class DataConvertMethod { /// <summary> /// int转换方法 /// </summary> public static MethodInfo ToIn32Method = typeof(DataConvertMethod).GetMethod(nameof(DataConvertMethod.ConvertToInt32)); /// <summary> /// int?转换方法 /// </summary> public static MethodInfo ToIn32NullableMethod = typeof(DataConvertMethod).GetMethod(nameof(DataConvertMethod.ConvertToInt32Nullable)); public static int ConvertToInt32(this IDataRecord dr, int i) { if (dr.IsDBNull(i)) { return default; } var result = dr.GetInt32(i); return result; } public static int? ConvertToInt32Nullable(this IDataRecord dr, int i) { if (dr.IsDBNull(i)) { return default; } var result = dr.GetInt32(i); return result; } }
然后我们编写IL来创建动态函数,并使用用上面的接口作为参数
private static Func<IDataRecord, T> CreateTypeSerializerHandler<T>(ITypeMapper mapper, IDataRecord record) { var type = typeof(T); var dynamicMethod = new DynamicMethod($"{type.Name}Deserializer{Guid.NewGuid().ToString("N")}", type, new Type[] { typeof(IDataRecord) }, type, true); var generator = dynamicMethod.GetILGenerator(); LocalBuilder local = generator.DeclareLocal(type); //获取到这个record中的所有字段信息 var dataInfos = new DbDataInfo[record.FieldCount]; for (int i = 0; i < record.FieldCount; i++) { var dataname = record.GetName(i); var datatype = record.GetFieldType(i); var typename = record.GetDataTypeName(i); dataInfos[i] = new DbDataInfo(i, typename, datatype, dataname); } //查找构造器 var constructor = mapper.FindConstructor(type); //获取所有属性 var properties = type.GetProperties(); //var entity = new T(); generator.Emit(OpCodes.Newobj, constructor); generator.Emit(OpCodes.Stloc, local); //绑定属性 foreach (var item in dataInfos) { //根据属性查找规则查找属性,如果不存在则不绑定 var property = mapper.FindMember(properties, item) as PropertyInfo; if (property == null) { continue; } //获取转换成该字段类型的转换函数 var convertMethod = mapper.FindConvertMethod(property.PropertyType); if (convertMethod == null) { continue; } //获取该C#字段,在本次查询的索引位 int i = record.GetOrdinal(item.DataName); //下面这几行IL的意思是 //entity.FieldName1 = reader.ConvertToInt32(i); generator.Emit(OpCodes.Ldloc, local); generator.Emit(OpCodes.Ldarg_0); generator.Emit(OpCodes.Ldc_I4, i); if (convertMethod.IsVirtual) generator.Emit(OpCodes.Callvirt, convertMethod); else generator.Emit(OpCodes.Call, convertMethod); generator.Emit(OpCodes.Callvirt, property.GetSetMethod()); } // return entity; generator.Emit(OpCodes.Ldloc, local); generator.Emit(OpCodes.Ret); //创建成委托,参数IDataReader,返回T, return dynamicMethod.CreateDelegate(typeof(Func<IDataRecord, T>)) as Func<IDataRecord, T>; }
动态创建的IL绑定函数我们需要编写一个缓存策略(我们使用hash结构进行存储),一个目标类型可能生成多个绑定函数,这根据你sql返回的字段个数和顺序有关
定义hash结构的key
private struct SerializerKey : IEquatable<SerializerKey> { private string[] Names { get; set; } private Type Type { get; set; } public override bool Equals(object obj) { return obj is SerializerKey && Equals((SerializerKey)obj); }
//由于我们会查询不同个数的列,而使用同一个实体,个数不同生成的绑定IL函数也不同
//所以同一个类型可能会生成多个绑定,因此重写equals public bool Equals(SerializerKey other) {
//先判断目标类型 if (Type != other.Type) { return false; }
//判断字段个数 else if (Names.Length != other.Names.Length) { return false; }
//判断顺序 else { for (int i = 0; i < Names.Length; i++) { if (Names[i] != other.Names[i]) { return false; } } return true; } } //根据类型进行hash存储。 public override int GetHashCode() { return Type.GetHashCode(); } public SerializerKey(Type type, string[] names) { Type = type; Names = names; } }
编写一个缓存策略
/// <summary> /// 从缓存中读取类型转换器 /// </summary> public static Func<IDataRecord, T> GetSerializer<T>(ITypeMapper mapper, IDataRecord record) { string[] names = new string[record.FieldCount]; for (int i = 0; i < record.FieldCount; i++) { names[i] = record.GetName(i); }
//从缓存中读取 var key = new SerializerKey(typeof(T), names); _serializers.TryGetValue(key, out object handler); if (handler == null) {
//这里在写的时候才开始lock,而dapper是在读的时候,我认为那样对并发有影响,不能因为你的框架要做缓存,就影响到我并发
//而我在写的时候才锁,只影响你第一次 lock (_serializers) { handler = CreateTypeSerializerHandler<T>(mapper, record); if (!_serializers.ContainsKey(key)) { _serializers.Add(key, handler); } } } return handler as Func<IDataRecord, T>; }
好了大部分工作都完成了,我们编一个sql执行器(简化版)
public static IEnumerable<T> ExecuteQuery<T>(this IDbConnection connection, string sql) { if (connection.State == ConnectionState.Closed) connection.Open(); using (var cmd = connection.CreateCommand()) { cmd.CommandText = sql; using (var reader = cmd.ExecuteReader()) { var handler = TypeConvert.GetSerializer<T>(reader); while (reader.Read()) { yield return handler(reader); } } } }
至此我们已经完成了整个流程。
我们可以发现没有拆装箱,没有强制类型转换,
对比于使用ado.net的性能差距,由于我们的动态生成绑定函数,在下次使用的时候我们需要从hash表中去查询这个函数指针。
这便是性能的差距点,而我们首先绑定函数,下次时候的时候显示的调用你定义的绑定函数。
也就是说,你只要能优化这个缓存策略,就能无限接近手写ado.net。