Kubernetes基本概念
一、Label selector在kubernetes中的应用场景
1.kube-controller-manager的replicaSet通过定义的label 来筛选要监控的副本数量,使pod副本数量始终符合预期设定
2.kube-proxy进程通过service的label来选择对应的Pod.自动建立每个service到对应Pod的请求转发路由表,从而实现service的智能负载均衡机制
二、kube-controller-manager之replicaSet控制器
- 通过label selector机制实现对Pod副本的自动控制
- 通过改变Pod副本的数量,可以实现Pod的扩容或缩容
- 可以改变Pod模板中的镜像版本,可以实现Pod的滚动升级
三、kube-controller-manager之statefulSet控制器
3.1作用
部署有状态的服务(数据库之类的),deployment是部署无状态的服务(nginx tomcat等),如果用deployment部署有状态的话,Pod名称是随机产生的,Pod的IP地址也是在运行时才确定且可能是有变动的,我们事先无法为每个Pod都确定唯一不变的ID
3.2有状态应用的特性
例如:MySQL集群、mongo集群、zookeeper集群
1、每个节点都有固定的身份ID,通过这个ID集群中的成员可以互相发现并通信
2、集群中的每个节点都是有状态的,通常会持久化数据到永久存储中
3、集群规模是比较固定的,集群规模不能随意变动
Kube-ApiServer原理解析
一、作用
kubernetes Api server作为集群的核心,负载集群各个模块之前的通信,集群内各个模块通过Api-server将信息存入ETCD,当需要获取和操作这些数据时,则通过Api-server提供的Rest接口(用Get,List,Watch方法)来实现,从而实现各个模块之间的信息交互

二、跟各组件的交互场景
2.1kubelet进程与Api-server的交互
1、每个Node上的kubelet每隔一个时间周期,就会调用一次API,的REST接口报告自身状态,Api-server在接收到这些信息后,会将节点状态更新到ETCD中
2、kubelet也通过API-Server的Watch接口监听Pod信息,如果监听到新Pod副本都调度绑定到本节点,则执行Pod对应的容器创建和启动操作;如果监听到Pod对象被删除,则删除本节点的相应的Pod;如果监听到修改,就修改本节点对应的Pod容器
2.2 kube-controller-manager进程与API-Server的交互
kube-controller-manager中的Node-Controller模块通过API-Server提供的Watch接口实时监控Node信息,并做相应处理
2.3 kube-scheduler与API-Server的交互
scheduler通过API-Server的Watch接口监听到新建Pod副本的信息后,会检索所有符合该Pod要求的Node节点,开始执行Pod调度逻辑,在调度成功后将Pod绑定到目标节点
kube-controller-manager原理解析
一、kube-controller-manager的8种controller
1.1replicaSet Controller
- 确保预定设置pod副本数量.
- 通过调整spec.replicas属性值来实现系统扩容和缩容(弹性伸缩)
- 通过改变Pod模板(主要是镜像版本)来实现滚动升级
1.2Node Controller
- kubelet进程在启动时通过API-Server注册自身的节点信息,并定时想API-Server汇报状态信息,API-Server在接收到这些信息之后,会将这些信息更新到ETCD
- Node Controller通过API-Server实时获取Node相关信息,实现管理和监控集群中各个Node节点(比如kubeget get cs的结果)
1.3ResourceQuota Controller
资源配额管理器
1.3.1可以对哪些资源进行限制
1)容器级别,可以对CPU和Memory进行限制
2)Pod级别,可以对一个Pod内所有容器的可用资源进行限制
3)Namespace级别,为namespace级别的资源限制
- Pod数量
- replication controller数量
- service数量
- resourceQuota数量
- secret数量
- 可持有PV数量
1.3.2配额管理是通过admission Control(准入控制)来控制的
admission Control提供了两种配合约束
1)LimitRanger:作用于Pod和Container
2)ResourceQuota:作用于NameSpace,限定NameSpace里各类资源使用总额
如果在Pod定义时声名了LimitRanger,如果用户通过api-server创建资源时,admission control会计算当前配额使用情况,如果不符合就会创建失败
如果namespace定义了ResourceQuota,ResourceQuota组件定期统计该namespace下的各类资源使用总量,包括:Pod、service、RC、secret、PV等实例个数,还有该namespace下所有container的CPU、内存使用量写入到ETCD中,admission control根据对比这些信息,确保不会超过ResourceQuota定义的值
1.4NameSpace Controller
用户通过API-Server创建Namespace,Namespace Controller通过API-Server定时读取Namespace信息,如果namespace被API表示为优雅删除,NamespaceController就将该namespace状态标识为terminating并保存到ETCD,同时删除该namespace下的资源对象
1.5ServiceAccount Controller
1.6Token Controller
1.7Service Controller
1.8EndPoints Controller
1.8.1作用
- Endpoint就是一个service对应的所有pod副本的访问地址(通过kubectl get ep查看),EndPoints Controller就负责生成和维护所有endpoint对象
- 它负责监听service和对应的Pod副本变化,如果service被删除,就删除该service同名的endpoints,如果监听到新的service被创建,就根据该service信息获取相关的pod列表,生成endpoint
- endpoint是被Node节点的kube-proxy使用,kube-proxy获取每个service的endpoints,然后实现service的负载均衡功能(kube-proxy原理章节重点讲解怎么实现的)
Scheduler原理
一、作用简要
把controller-manager创建的pod(API-Server创建Pod,controller-manager的replicaSet为补足副本数而创建的Pod)根据算法调度到合适的Node节点让Node节点的kubelet负责管理Pod的生命周期
二、作用之详细说
scheduler将等待调度的Pod(API-Server新创建的pod,Controller-Manager的ReplicaSet为补足副本数而创建的Pod)按照调度算法绑定到集群中合适的Node上,并将绑定信息写入ETCD;随后目标Node节点的kubelet通过API-Server监听到scheduler产生的Pod绑定事件,获取对应的Pod列表,下载image并启动容器
注意:所有组件只能通过API-Server获取到ETCD的信息
kubelet运行机制和原理
一、作用
- 用于处理master下发到本节点的任务,管理Pod及Pod中的容器
- kubelet定时调用livenessProbe探针对容器做健减健康检查
- kubelet调用readinessProbe探针检测容器是否启动完成,如果检测启动失败,Pod的状态将被修改,endpoint controller将从service的endpoint中删除包含该容器的endpoint条目
- kubelet会在API-Server中注册节点自身的信息,定期向master汇报节点资源使用情况,并通过cadvisor监控容器和节点资源
kube-proxy运行机制和原理
一、作用
每个Node节点都运行一个kube-proxy,它监听API-Server中service和endpoint的变化情况,并通过在Node上创建ipvs规则来配置负载均衡
通过NodeIP外部可以访问到Pod提供的服务
通过ClusterIP+端口,集群内部可以访问到Pod提供的服务
二、通过NodeIP访问到后端Pod原理
ipvs模式下是基于NAT模式做的,因为只有NAT模式支持端口转发的负载均衡,比如30656端口转发到Pod容器中nginx的80端口做LB
NodeIP访问还是service的ClusterIP访问请看这个文档
https://blog.csdn.net/u011563903/article/details/87904873
http://www.mamicode.com/info-detail-2611680.html
1.创建完service之后,对外暴露的端口是30656,对内是80
通过NodeIP+30656端口,外部可以访问到Pod提供的服务

2.kube-proxy通过API-Server监听到service和endpoint信息,就在node机器上监听30656端口.然后获取service对应的enpoint信息,通过ipvs创建负载均衡,将30656的请求转发到endpoint查询出来的IP和端口上


三、通过ClusterIP访问到后端Pod原理
1.可以看到给service分配了一个clusterIP,根据这个IP+80端口访问

2.在每个Node节点ip addr查看到一个kube-ipvs0的虚拟设备
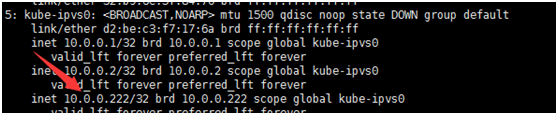
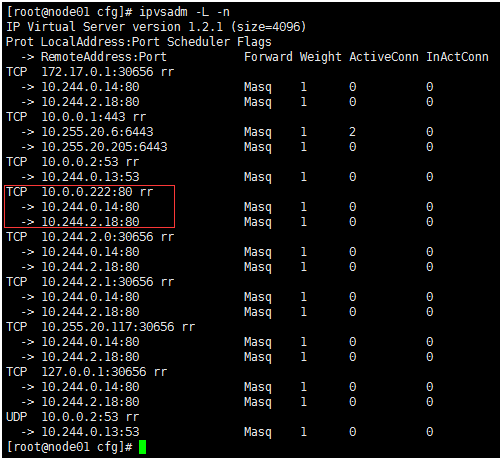
3.在通过ipvs转发到具体的Pod
kubernetes的网络模型
- k8s网络模型是ip-per-pod,就是每个Pod都拥有一个独立的IP地址,所有的Pod的都可以直接连通,不管是不是在同一台Node上
- k8s里,ip是以Pod为单位进行分配的,一个Pod内所有容器共享一个网络堆栈(相当于一个网络命名空间,它们的IP、网络设备、配置都是共享的)
kubernetes网络实现
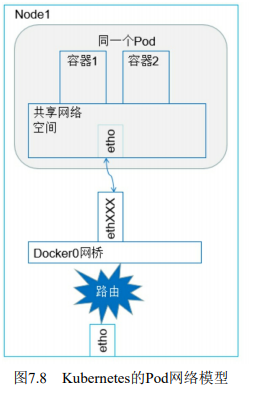
一、同一个Pod容器到容器之间的通信
同一个Pod内的容器不会垮宿主机,它们共享同一个网络命名空间,共享同一个Linux协议栈,所以对于各类网络操作,就相当于在同一台机器,可以用localhost访问彼此端口
二、Pod到Pod之间的通信
每一个Pod都有一个全局的IP地址,同一个Node中Pod之间可以直接用IP通信,不需要服务发现
1.同一个Node内Pod之间的通信
1)同一个Node内两个Pod之间的关系,如下图

2)可以看出Pod1和Pod2都是通过veth连接到同一个docker0网桥上,它们的IP都是docker0网桥上动态获取的,它们和docker0网桥在同一个IP段
3)另外在Pod1和Pod2的Linux协议栈上,默认路由都是docker0的地址,所有非本地地址网络数据都被默认发送到docker0网桥上,由docker0网桥中转
4)综上所述,由于它们都关联到同一个docker0网桥上,IP段相同,所以它们之间是能直接通信的
2.不同Node上Pod之间的通信实现方法
1)必须满足2个条件
- 在整个kubernetes集群中对Pod的IP分配进行规划,不能用冲突
- 将Pod的IP和所在Node的IP关联起来,通过这个关联个Pod可以互相访问
2)具体实现原理
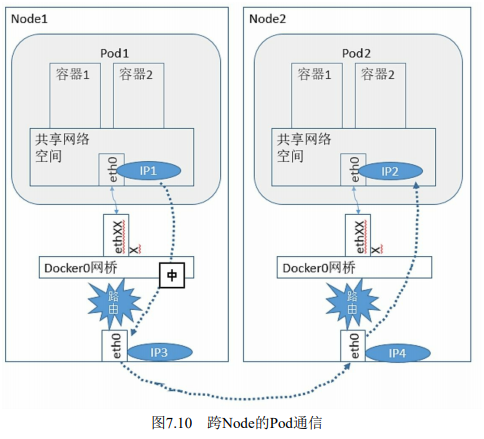
- ①Pod1通过veth将数据发送到docker0网桥
- ②docker0网桥发送到宿主机网卡
- ③宿主机网卡将数据发送到Pod的宿主机网卡
- ④Pod2宿主机网卡将数据发送到docker0网桥
- ⑤docker0网桥发送给Pod2
以上具体实现需要通过k8s的网络插件实现,比如flannel或者calico,看flannel或者calico的原理就行,后面讲
三、Pod到Service之间的通信
四、集群外部与内部组件之间的通信
CNI插件之flannel原理
一、flannel原理
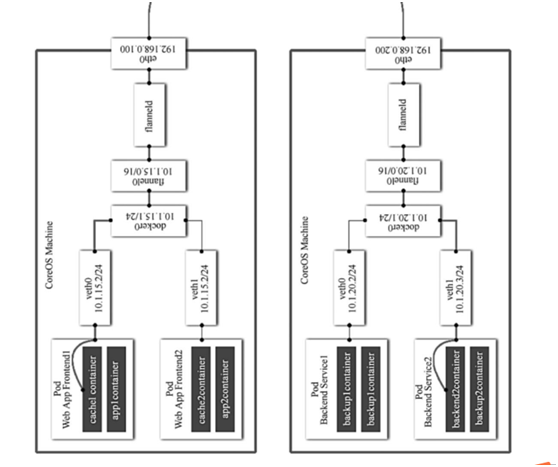
- 容器内通过veth找到docker0网桥
- docker0网桥转发给flannel的网桥
- flannel网桥转发给flanneld的进程
- flanneld进程转发给宿主机网络
宿主机网络到对端Pod宿主机网络--》flanneld进程--》flannel0网桥-->docker0网桥--veth到容器