本章节主要说的迁移学习的事情,迁移学习简单来说:举个例子,新产品上线,建模使用其他产品和少量新产品的数据建模,不码字,具体百度吧。
全部代码:


# -*- coding: utf-8 -*- """ Created on Tue Dec 24 15:25:58 2019 @author: zixing.mei """ import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression from sklearn.svm import LinearSVC import numpy as np import random import math from sklearn.calibration import CalibratedClassifierCV #概率矫正方法 data = pd.read_excel('D:/陈桂梅/学习资料/64353 智能风控_源码及数据_2010/智能风控(数据集)/tra_sample.xlsx') data.head() feature_lst = ['zx_score','msg_cnt','phone_num_cnt','register_days'] train = data[data.type == 'target'].reset_index().copy() #目标域 diff = data[data.type == 'origin'].reset_index().copy() #源域 val = data[data.type == 'offtime'].reset_index().copy() #oot ''' TrainS 目标域样本 TrainA 源域样本 LabelS 目标域标签 LabelA 源域标签 ''' train = train.loc[:1200] #取前面1200行 trans_S = train[feature_lst].copy() label_S = train['bad_ind'].copy() trans_A = diff[feature_lst].copy() label_A = diff['bad_ind'].copy() val_x = val[feature_lst].copy() val_y = val['bad_ind'].copy() test = val_x.copy() #%% 使用目标域数据建模 ,ks相差10%,roc曲线不平滑,说明模型泛化能力差 lr_model = LogisticRegression(C=0.1,class_weight = 'balanced',solver = 'liblinear') lr_model.fit(trans_S,label_S) y_pred = lr_model.predict_proba(trans_S)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.48500238435860754 y_pred = lr_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #val_ks : 0.3887057754389137 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show() trans_data = np.concatenate((trans_A, trans_S), axis=0) trans_label = np.concatenate((label_A, label_S), axis=0) #%%使用源域数据建模 ,ks不稳定,roc不稳定,泛化能力非常差 lr_model = LogisticRegression(C=0.3,class_weight = 'balanced',solver = 'liblinear') lr_model.fit(trans_A,label_A) y_pred = lr_model.predict_proba(trans_data)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(trans_label,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.4910909493184976 y_pred = lr_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #val_ks : 0.33077621830414 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show() #%%将源域和目标域的数据整合在一起 import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve def Tr_lr_boost(trans_A,trans_S,label_A,label_S,test,label_test, N=500,early_stopping_rounds =100): """ 逻辑回归的学习率、权重的大小,影响整体收敛的快慢 H 测试样本分类结果 TrainS 目标域样本 TrainA 源域样本 LabelS 目标域标签 LabelA 源域标签 Test 测试样本 N 迭代次数 early_stopping_rounds 提前停止轮次 """ #计算weight def calculate_P(weights, label): total = np.sum(weights) return np.asarray(weights / total, order='C') #用逻辑回归作为基分类器,输出概率 def train_classify(trans_data, trans_label, test_data, P): clf = LogisticRegression(C=0.3,class_weight = 'balanced',solver='liblinear') clf.fit(trans_data, trans_label, sample_weight=P[:, 0]) return clf.predict_proba(test_data)[:,1],clf #计算在目标域上面的错误率 def calculate_error_rate(label_R, label_H, weight): total = np.sum(weight) return np.sum(weight[:, 0] / total * np.abs(label_R - label_H)) #根据逻辑回归输出的score的得到标签,注意这里不能用predict直接输出标签 def put_label(score_H,thred): new_label_H = [] for i in score_H: if i <= thred: new_label_H.append(0) else: new_label_H.append(1) return new_label_H #指定迭代次数,相当于集成模型中基模型的数量 #拼接数据集 trans_data = np.concatenate((trans_A, trans_S), axis=0) trans_label = np.concatenate((label_A, label_S), axis=0) #三个数据集样本数 row_A = trans_A.shape[0] row_S = trans_S.shape[0] row_T = test.shape[0] #三个数据集合并为打分数据集 test_data = np.concatenate((trans_data, test), axis=0) # 初始化权重 weights_A = np.ones([row_A, 1])/row_A weights_S = np.ones([row_S, 1])/row_S*2 # 目标域的权重会比源域的权重高一些 weights = np.concatenate((weights_A, weights_S), axis=0) #按照公式初始化beta值 bata = 1 / (1 + np.sqrt(2 * np.log(row_A / N))) #N是多少,N是迭代次数 # 存每一次迭代的bata值=error_rate / (1 - error_rate) bata_T = np.zeros([1, N]) # 存储每次迭代的标签 result_label = np.ones([row_A + row_S + row_T, N]) trans_data = np.asarray(trans_data, order='C') trans_label = np.asarray(trans_label, order='C') test_data = np.asarray(test_data, order='C') #最优KS best_ks = -1 #最优基模型数量 best_round = -1 #最优模型 best_model = -1 """ 初始化结束 正式开始训练 """ for i in range(N): P = calculate_P(weights, trans_label) result_label[:, i],model = train_classify(trans_data, trans_label, test_data, P) score_H = result_label[row_A:row_A + row_S, i] pctg = np.sum(trans_label)/len(trans_label) thred = pd.DataFrame(score_H).quantile(1-pctg)[0] label_H = put_label(score_H,thred) #计算在目标域上的错误率 error_rate = calculate_error_rate(label_S, label_H, weights[row_A:row_A + row_S, :]) # 防止过拟合 if error_rate > 0.5: error_rate = 0.5 if error_rate == 0: N = i break bata_T[0, i] = error_rate / (1 - error_rate) # 调整目标域样本权重 for j in range(row_S): weights[row_A + j] = weights[row_A + j] * np.power(bata_T[0, i], (-np.abs(result_label[row_A + j, i] - label_S[j]))) # 调整源域样本权重 for j in range(row_A): weights[j] = weights[j] * np.power(bata, np.abs(result_label[j, i] - label_A[j])) y_pred = result_label[(row_A + row_S):,i] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_test,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('test_ks : ',train_ks,'当前第',i+1,'轮') # 不再使用后一半学习器投票,而是只保留效果最好的逻辑回归模型 if train_ks > best_ks : best_ks = train_ks best_round = i best_model = model # 当超过eadrly_stopping_rounds轮KS不再提升后,停止训练 if best_round < i - early_stopping_rounds: break return best_ks,best_round,best_model # 训练并得到最优模型best_model best_ks,best_round,best_model = Tr_lr_boost(trans_A,trans_S,label_A,label_S, test,label_test=val_y,N=300, early_stopping_rounds=20) y_pred = best_model.predict_proba(trans_S)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.4629947544110634 y_pred = best_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) # val_ks : 0.39846160021324123 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show()
感觉迁移学习,很多公司不采用,比较难办
一、数据准备
主要是划分目标域,源域,oot样本
import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression from sklearn.svm import LinearSVC import numpy as np import random import math from sklearn.calibration import CalibratedClassifierCV #概率矫正方法 data = pd.read_excel('xxx/tra_sample.xlsx') data.head() feature_lst = ['zx_score','msg_cnt','phone_num_cnt','register_days'] train = data[data.type == 'target'].reset_index().copy() #目标域 diff = data[data.type == 'origin'].reset_index().copy() #源域 val = data[data.type == 'offtime'].reset_index().copy() #oot ''' TrainS 目标域样本 TrainA 源域样本 LabelS 目标域标签 LabelA 源域标签 ''' train = train.loc[:1200] #取前面1200行 trans_S = train[feature_lst].copy() label_S = train['bad_ind'].copy() trans_A = diff[feature_lst].copy() label_A = diff['bad_ind'].copy() val_x = val[feature_lst].copy() val_y = val['bad_ind'].copy() test = val_x.copy()
二、目标域建模
使用目标域建模,然后使用oot测试
#%% 使用目标域数据建模 ,ks相差10%,roc曲线不平滑,说明模型泛化能力差 lr_model = LogisticRegression(C=0.1,class_weight = 'balanced',solver = 'liblinear') lr_model.fit(trans_S,label_S) y_pred = lr_model.predict_proba(trans_S)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.48500238435860754 y_pred = lr_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #val_ks : 0.3887057754389137 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show() trans_data = np.concatenate((trans_A, trans_S), axis=0) trans_label = np.concatenate((label_A, label_S), axis=0)
ks相差10%,roc曲线不平滑,说明模型泛化能力差
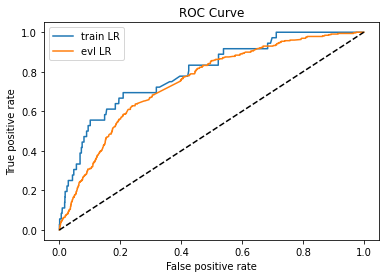
三、使用源域建模
使用源域建模,然后使用oot测试
#%%使用源域数据建模 ,ks不稳定,roc不稳定,泛化能力非常差 lr_model = LogisticRegression(C=0.3,class_weight = 'balanced',solver = 'liblinear') lr_model.fit(trans_A,label_A) y_pred = lr_model.predict_proba(trans_data)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(trans_label,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.4910909493184976 y_pred = lr_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #val_ks : 0.33077621830414 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show()
ks不稳定,roc不稳定,泛化能力非常差
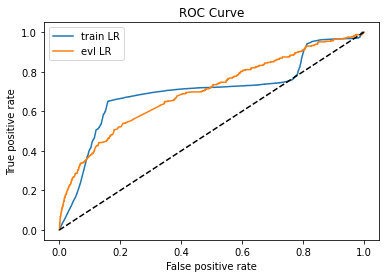
四、使用源域+目标域根据不同权重建模
使用源域+目标域,不断调整错分的样本的权重,使用目标域、oot测试
#%%将源域和目标域的数据整合在一起 import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve def Tr_lr_boost(trans_A,trans_S,label_A,label_S,test,label_test, N=500,early_stopping_rounds =100): """ 逻辑回归的学习率、权重的大小,影响整体收敛的快慢 H 测试样本分类结果 TrainS 目标域样本 TrainA 源域样本 LabelS 目标域标签 LabelA 源域标签 Test 测试样本 N 迭代次数 early_stopping_rounds 提前停止轮次 """ #计算weight def calculate_P(weights, label): total = np.sum(weights) return np.asarray(weights / total, order='C') #用逻辑回归作为基分类器,输出概率 def train_classify(trans_data, trans_label, test_data, P): clf = LogisticRegression(C=0.3,class_weight = 'balanced',solver='liblinear') clf.fit(trans_data, trans_label, sample_weight=P[:, 0]) return clf.predict_proba(test_data)[:,1],clf #计算在目标域上面的错误率 def calculate_error_rate(label_R, label_H, weight): total = np.sum(weight) return np.sum(weight[:, 0] / total * np.abs(label_R - label_H)) #根据逻辑回归输出的score的得到标签,注意这里不能用predict直接输出标签 def put_label(score_H,thred): new_label_H = [] for i in score_H: if i <= thred: new_label_H.append(0) else: new_label_H.append(1) return new_label_H #指定迭代次数,相当于集成模型中基模型的数量 #拼接数据集 trans_data = np.concatenate((trans_A, trans_S), axis=0) trans_label = np.concatenate((label_A, label_S), axis=0) #三个数据集样本数 row_A = trans_A.shape[0] row_S = trans_S.shape[0] row_T = test.shape[0] #三个数据集合并为打分数据集 test_data = np.concatenate((trans_data, test), axis=0) # 初始化权重 weights_A = np.ones([row_A, 1])/row_A weights_S = np.ones([row_S, 1])/row_S*2 # 目标域的权重会比源域的权重高一些 weights = np.concatenate((weights_A, weights_S), axis=0) #按照公式初始化beta值 bata = 1 / (1 + np.sqrt(2 * np.log(row_A / N))) #N是多少,N是迭代次数 # 存每一次迭代的bata值=error_rate / (1 - error_rate) bata_T = np.zeros([1, N]) # 存储每次迭代的标签 result_label = np.ones([row_A + row_S + row_T, N]) trans_data = np.asarray(trans_data, order='C') trans_label = np.asarray(trans_label, order='C') test_data = np.asarray(test_data, order='C') #最优KS best_ks = -1 #最优基模型数量 best_round = -1 #最优模型 best_model = -1 """ 初始化结束 正式开始训练 """ for i in range(N): P = calculate_P(weights, trans_label) result_label[:, i],model = train_classify(trans_data, trans_label, test_data, P) score_H = result_label[row_A:row_A + row_S, i] pctg = np.sum(trans_label)/len(trans_label) thred = pd.DataFrame(score_H).quantile(1-pctg)[0] label_H = put_label(score_H,thred) #计算在目标域上的错误率 error_rate = calculate_error_rate(label_S, label_H, weights[row_A:row_A + row_S, :]) # 防止过拟合 if error_rate > 0.5: error_rate = 0.5 if error_rate == 0: N = i break bata_T[0, i] = error_rate / (1 - error_rate) # 调整目标域样本权重 for j in range(row_S): weights[row_A + j] = weights[row_A + j] * np.power(bata_T[0, i], (-np.abs(result_label[row_A + j, i] - label_S[j]))) # 调整源域样本权重 for j in range(row_A): weights[j] = weights[j] * np.power(bata, np.abs(result_label[j, i] - label_A[j])) y_pred = result_label[(row_A + row_S):,i] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_test,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('test_ks : ',train_ks,'当前第',i+1,'轮') # 不再使用后一半学习器投票,而是只保留效果最好的逻辑回归模型 if train_ks > best_ks : best_ks = train_ks best_round = i best_model = model # 当超过eadrly_stopping_rounds轮KS不再提升后,停止训练 if best_round < i - early_stopping_rounds: break return best_ks,best_round,best_model # 训练并得到最优模型best_model best_ks,best_round,best_model = Tr_lr_boost(trans_A,trans_S,label_A,label_S, test,label_test=val_y,N=300, early_stopping_rounds=20) y_pred = best_model.predict_proba(trans_S)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(label_S,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #train_ks : 0.4629947544110634 y_pred = best_model.predict_proba(test)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) # val_ks : 0.39846160021324123 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show()

至于结果为什么和梅老师的结果不太一样,可能是数据的原因