本次章节的2个疑点:
1.决策树是不需要处理缺失值得,梅老师也乜有处理缺失值,tree.DecisionTreeRegressor在梅老师那里是运行成功的,但是我的报错ValueError: Input contains NaN, infinity or a value too large for dtype('float32').
可能是版本问题,现版本确实不能接受缺失值,于是我用均值填补了缺失值,最后得到的结果也和梅老师不一样,仔细看了一下,数据量和梅老师的也不一样
2.GraphViz的安装问题,InvocationException: GraphViz's executables not found,我们可以参看这个https://blog.csdn.net/lizzy05/article/details/88529483,直接下载msi文件,后面就迎刃而解了。
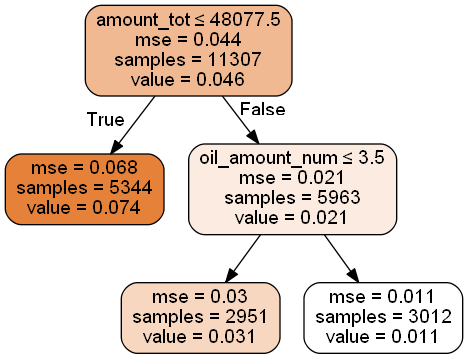
3.该章节最主要的是使用CART回归树做组合规则:

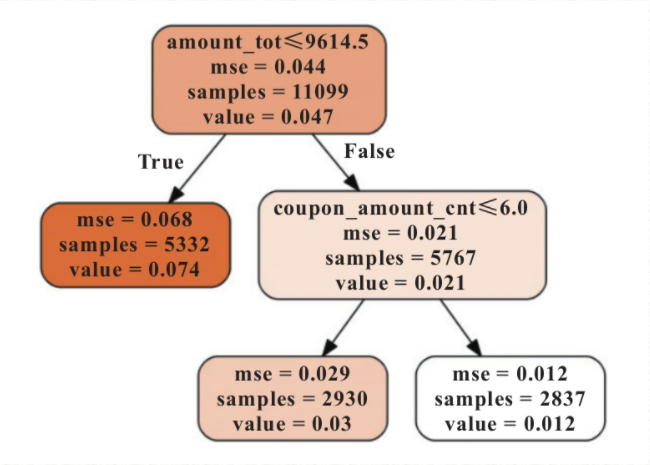

下面布上代码
# -*- coding: utf-8 -*- """ Created on Tue Dec 24 14:31:54 2019 @author: zixing.mei """ import pandas as pd import numpy as np import os #为画图指定路径 os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' #读取数据 data = pd.read_excel( 'xxx/data_for_tree.xlsx') data.head() org_lst = ['uid','create_dt','oil_actv_dt','class_new','bad_ind'] agg_lst = ['oil_amount','discount_amount','sale_amount','amount','pay_amount','coupon_amount','payment_coupon_amount'] dstc_lst = ['channel_code','oil_code','scene','source_app','call_source'] df = data[org_lst].copy() df[agg_lst] = data[agg_lst].copy() df[dstc_lst] = data[dstc_lst].copy() base = df[org_lst].copy() base = base.drop_duplicates(['uid'],keep = 'first') #%% gn = pd.DataFrame() for i in agg_lst: #计算个数 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:len(df[i])).reset_index()) tp.columns = ['uid',i + '_cnt'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #求历史特征值大于零的个数 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.where(df[i]>0,1,0).sum()).reset_index()) tp.columns = ['uid',i + '_num'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求和 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nansum(df[i])).reset_index()) tp.columns = ['uid',i + '_tot'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求均值 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nanmean(df[i])).reset_index()) tp.columns = ['uid',i + '_avg'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求最大值 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nanmax(df[i])).reset_index()) tp.columns = ['uid',i + '_max'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求最小值 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nanmin(df[i])).reset_index()) tp.columns = ['uid',i + '_min'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求方差 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nanvar(df[i])).reset_index()) tp.columns = ['uid',i + '_var'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求极差 tp = pd.DataFrame(df.groupby('uid').apply( lambda df:np.nanmax(df[i])-np.nanmin(df[i]) ).reset_index()) tp.columns = ['uid',i + '_ran'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') #对历史数据求变异系数,为防止除数为0,利用0.01进行平滑 tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nanmean(df[i])/(np.nanvar(df[i])+0.01))).reset_index() tp.columns = ['uid',i + '_cva'] if gn.empty == True: gn = tp else: gn = pd.merge(gn,tp,on = 'uid',how = 'left') gc = pd.DataFrame() for i in dstc_lst: tp = pd.DataFrame(df.groupby('uid').apply( lambda df: len(set(df[i]))).reset_index()) tp.columns = ['uid',i + '_dstc'] if gc.empty == True: gc = tp else: gc = pd.merge(gc,tp,on = 'uid',how = 'left') fn = base.merge(gn,on='uid').merge(gc,on='uid') fn = pd.merge(fn,gc,on= 'uid') fn.shape #%% x = fn.drop(['uid','oil_actv_dt','create_dt','bad_ind','class_new'],axis = 1) for i in x.columns: x[i].fillna(x[i].mean(),inplace=True) y = fn.bad_ind.copy() from sklearn import tree dtree = tree.DecisionTreeRegressor(max_depth = 2,min_samples_leaf = 500,min_samples_split = 5000) dtree = dtree.fit(x,y) import pydotplus from IPython.display import Image from six import StringIO import os os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' dot_data = StringIO() tree.export_graphviz(dtree, out_file=dot_data, feature_names=x.columns, class_names=['bad_ind'], filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png()) ''' dff1 = fn.loc[(fn.amount_tot>9614.5)&(fn.coupon_amount_cnt>6)].copy() dff1['level'] = 'past_A' dff2 = fn.loc[(fn.amount_tot>9614.5)&(fn.coupon_amount_cnt<=6)].copy() dff2['level'] = 'past_B' dff3 = fn.loc[fn.amount_tot<=9614.5].copy() dff3['level'] = 'past_C' '''