主要修改点有2处:
1.xgboost的参数,有些参数现版本的xgboost是没有的,需要注释掉或者使用现在的替换
2.xgboost版评分映射的问题,由于预测的是逾期的概率,因此我们需要使用基础分-后面的,而不是+
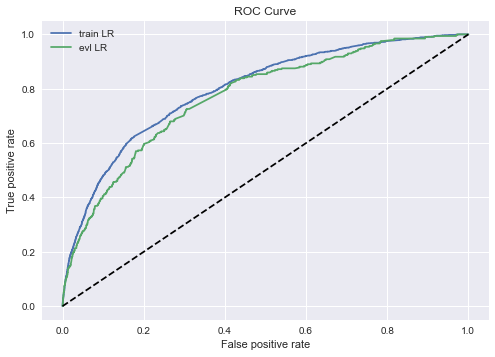
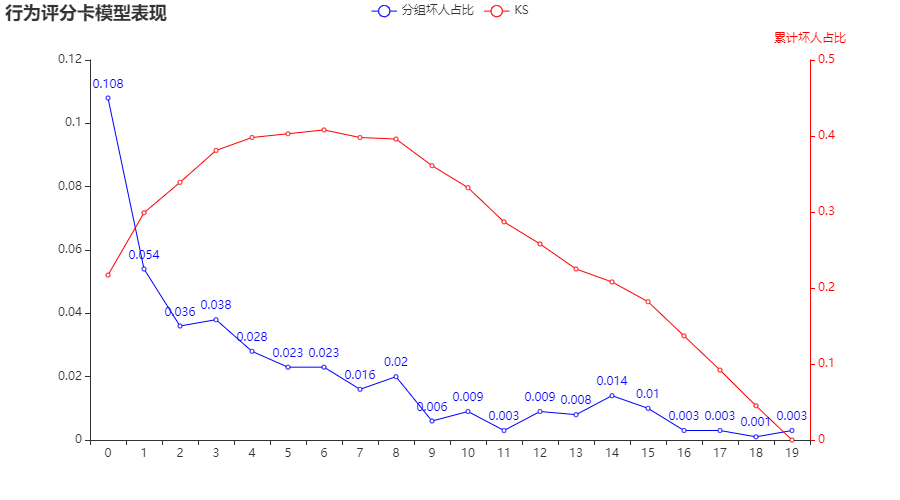
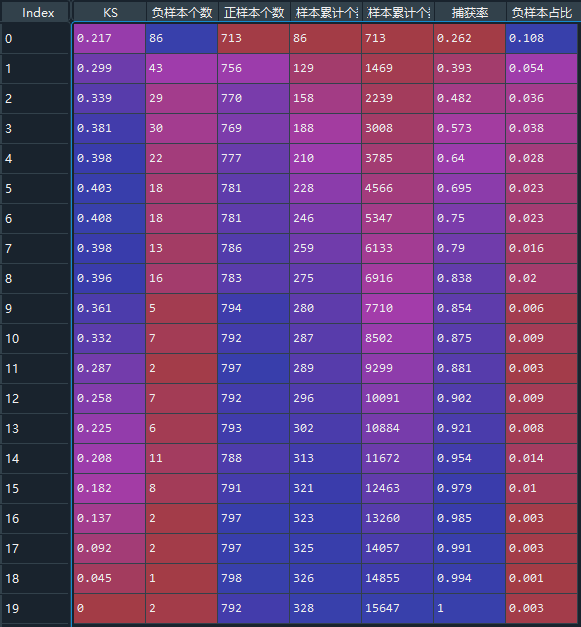
#%% import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc from sklearn import metrics from sklearn.linear_model import LogisticRegression import numpy as np data = pd.read_csv('xxx/Acard.txt') data.head() data.obs_mth.unique() ''' array(['2018-10-31', '2018-07-31', '2018-09-30', '2018-06-30', '2018-11-30'], dtype=object) ''' #每个月的数据量 data.obs_mth.value_counts() ''' Out[233]: 2018-07-31 34030 2018-06-30 20565 2018-11-30 15975 2018-10-31 14527 2018-09-30 10709 Name: obs_mth, dtype: int64 ''' train = data[data.obs_mth != '2018-11-30'].reset_index().copy() #训练集 val = data[data.obs_mth == '2018-11-30'].reset_index().copy() #测试集 feature_lst = ['person_info','finance_info','credit_info','act_info'] x = train[feature_lst] y = train['bad_ind'] val_x = val[feature_lst] val_y = val['bad_ind'] #0.0205320813771518 #%% lr_model = LogisticRegression(C=0.1,class_weight='balanced') lr_model.fit(x,y) #训练集 y_pred = lr_model.predict_proba(x)[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) train_ks = abs(fpr_lr_train - tpr_lr_train).max() print('train_ks : ',train_ks) #0.4482325608488951 #测试集 y_pred = lr_model.predict_proba(val_x)[:,1] fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #0.4198642457760936 from matplotlib import pyplot as plt plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR') plt.plot(fpr_lr,tpr_lr,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show() #%% ks import math model = lr_model row_num, col_num = 0, 0 bins = 20 Y_predict = [s[1] for s in model.predict_proba(val_x)] Y = val_y nrows = Y.shape[0] lis = [(Y_predict[i], Y[i]) for i in range(nrows)] ks_lis = sorted(lis, key=lambda x: x[0], reverse=True) bin_num = int(nrows/bins+1) bad = sum([1 for (p, y) in ks_lis if y > 0.5]) good = sum([1 for (p, y) in ks_lis if y <= 0.5]) bad_cnt, good_cnt = 0, 0 KS = [] BAD = [] GOOD = [] BAD_CNT = [] GOOD_CNT = [] BAD_PCTG = [] BADRATE = [] dct_report = {} for j in range(bins): ds = ks_lis[j*bin_num: min((j+1)*bin_num, nrows)] bad1 = sum([1 for (p, y) in ds if y > 0.5]) good1 = sum([1 for (p, y) in ds if y <= 0.5]) bad_cnt += bad1 good_cnt += good1 bad_pctg = round(bad_cnt/sum(val_y),3) badrate = round(bad1/(bad1+good1),3) ks = round(math.fabs((bad_cnt / bad) - (good_cnt / good)),3) KS.append(ks) BAD.append(bad1) GOOD.append(good1) BAD_CNT.append(bad_cnt) GOOD_CNT.append(good_cnt) BAD_PCTG.append(bad_pctg) BADRATE.append(badrate) dct_report['KS'] = KS dct_report['负样本个数'] = BAD dct_report['正样本个数'] = GOOD dct_report['负样本累计个数'] = BAD_CNT dct_report['正样本累计个数'] = GOOD_CNT dct_report['捕获率'] = BAD_PCTG dct_report['负样本占比'] = BADRATE val_repot = pd.DataFrame(dct_report) print(val_repot) #%% 利用pyecharts来画图 #其实就每个分区逾期率和ks的曲线图 from pyecharts.charts import * from pyecharts import options as opts from pylab import * mpl.rcParams['font.sans-serif'] = ['SimHei'] np.set_printoptions(suppress=True) pd.set_option('display.unicode.ambiguous_as_wide', True) pd.set_option('display.unicode.east_asian_width', True) line = ( Line() .add_xaxis(list(val_repot.index)) .add_yaxis( "分组坏人占比", list(val_repot.负样本占比), yaxis_index=0, color="red", ) .set_global_opts( title_opts=opts.TitleOpts(title="行为评分卡模型表现"), ) .extend_axis( yaxis=opts.AxisOpts( name="累计坏人占比", type_="value", min_=0, max_=0.5, position="right", axisline_opts=opts.AxisLineOpts( linestyle_opts=opts.LineStyleOpts(color="red") ), axislabel_opts=opts.LabelOpts(formatter="{value}"), ) ) .add_xaxis(list(val_repot.index)) .add_yaxis( "KS", list(val_repot['KS']), yaxis_index=1, color="blue", label_opts=opts.LabelOpts(is_show=False), ) ) line.render_notebook() #还有最好在jupyter 上面跑,Spyder不展示该图 #%% print('变量名单:',feature_lst) print('系数:',lr_model.coef_) print('截距:',lr_model.intercept_) ''' 变量名单: ['person_info', 'finance_info', 'credit_info', 'act_info'] 系数: [[ 3.4946237 11.40440098 2.45601882 -1.6844742 ]] 截距: [-0.34578469] ''' import math #算分数onekey def score(person_info,finance_info,credit_info,act_info): xbeta = person_info * ( 3.49460978) + finance_info * ( 11.40051582 ) + credit_info * (2.45541981) + act_info * ( -1.68676079) -0.34484897 score = 650-34* (xbeta)/math.log(2) return score val['score'] = val.apply(lambda x : score(x.person_info,x.finance_info,x. credit_info,x.act_info) ,axis=1) fpr_lr,tpr_lr,_ = roc_curve(val_y,val['score']) val_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',val_ks) #%% #对应评级区间 def level(score): level = 0 if score <= 600: level = "D" elif score <= 640 and score > 600 : level = "C" elif score <= 680 and score > 640: level = "B" elif score > 680 : level = "A" return level val['level'] = val.score.map(lambda x : level(x) ) print(val.level.groupby(val.level).count()/len(val)) #%% xgb import xgboost as xgb data = pd.read_csv('xxx/Acard.txt') df_train = data[data.obs_mth != '2018-11-30'].reset_index().copy() val = data[data.obs_mth == '2018-11-30'].reset_index().copy() lst = ['person_info','finance_info','credit_info','act_info'] train = data[data.obs_mth != '2018-11-30'].reset_index().copy() evl = data[data.obs_mth == '2018-11-30'].reset_index().copy() x = train[lst] y = train['bad_ind'] evl_x = evl[lst] evl_y = evl['bad_ind'] #%% #定义XGB函数 def XGB_test(train_x,train_y,test_x,test_y): from multiprocessing import cpu_count clf = xgb.XGBClassifier( boosting_type='gbdt', num_leaves=31, reg_Ap=0.0, reg_lambda=1, max_depth=2, n_estimators=800, max_features = 140, objective='binary:logistic', subsample=0.7, colsample_bytree=0.7, subsample_freq=1, learning_rate=0.05, min_child_weight=50, random_state=None,n_jobs=cpu_count()-1, num_iterations = 800 #迭代次数 ) clf.fit(train_x, train_y,eval_set=[(train_x, train_y),(test_x,test_y)], eval_metric='auc',early_stopping_rounds=100) #print(clf.n_features_) 现在乜有这个参数了 return clf #,clf.best_score_[ 'valid_1']['auc'] #模型训练 model = XGB_test(x,y,evl_x,evl_y) #训练集预测 y_pred = model.predict_proba(x)[:,1] fpr_xgb_train,tpr_xgb_train,_ = roc_curve(y,y_pred) train_ks = abs(fpr_xgb_train - tpr_xgb_train).max() print('train_ks : ',train_ks) #train_ks : 0.45953542070724995 #跨时间验证集预测 y_pred = model.predict_proba(evl_x)[:,1] fpr_xgb,tpr_xgb,_ = roc_curve(evl_y,y_pred) evl_ks = abs(fpr_xgb - tpr_xgb).max() print('evl_ks : ',evl_ks) #evl_ks : 0.4368715190475225 #画出ROC曲线并计算KS值 from matplotlib import pyplot as plt plt.plot(fpr_xgb_train,tpr_xgb_train,label = 'train LR') plt.plot(fpr_xgb,tpr_xgb,label = 'evl LR') plt.plot([0,1],[0,1],'k--') plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('ROC Curve') plt.legend(loc = 'best') plt.show() #计算分数,评分映射,原来梅老师这里是600-50*(math.log2((1- pred)/ pred)),但是由于预测的是坏用户,因此设置为减 def score(pred): score = 600-50*(math.log2((1- pred)/ pred)) return score evl['xbeta'] = model.predict_proba(evl_x)[:,1] evl['score'] = evl.apply(lambda x : score(x.xbeta) ,axis=1) fpr_lr,tpr_lr,_ = roc_curve(evl_y,evl['score']) evl_ks = abs(fpr_lr - tpr_lr).max() print('val_ks : ',evl_ks) #val_ks : 0.4368715190475225 #%%生成模型报告 row_num, col_num = 0, 0 bins = 20 Y_predict = evl['score'] Y = evl_y nrows = Y.shape[0] lis = [(Y_predict[i], Y[i]) for i in range(nrows)] ks_lis = sorted(lis, key=lambda x: x[0], reverse=True) bin_num = int(nrows/bins+1) bad = sum([1 for (p, y) in ks_lis if y > 0.5]) good = sum([1 for (p, y) in ks_lis if y <= 0.5]) bad_cnt, good_cnt = 0, 0 KS = [] BAD = [] GOOD = [] BAD_CNT = [] GOOD_CNT = [] BAD_PCTG = [] BADRATE = [] dct_report = {} for j in range(bins): ds = ks_lis[j*bin_num: min((j+1)*bin_num, nrows)] bad1 = sum([1 for (p, y) in ds if y > 0.5]) good1 = sum([1 for (p, y) in ds if y <= 0.5]) bad_cnt += bad1 good_cnt += good1 bad_pctg = round(bad_cnt/sum(evl_y),3) badrate = round(bad1/(bad1+good1),3) ks = round(math.fabs((bad_cnt / bad) - (good_cnt / good)),3) KS.append(ks) BAD.append(bad1) GOOD.append(good1) BAD_CNT.append(bad_cnt) GOOD_CNT.append(good_cnt) BAD_PCTG.append(bad_pctg) BADRATE.append(badrate) dct_report['KS'] = KS dct_report['BAD'] = BAD dct_report['GOOD'] = GOOD dct_report['BAD_CNT'] = BAD_CNT dct_report['GOOD_CNT'] = GOOD_CNT dct_report['BAD_PCTG'] = BAD_PCTG dct_report['BADRATE'] = BADRATE val_repot = pd.DataFrame(dct_report) print(val_repot) #%% 自定义损失函数,需要提供损失函数的一阶导和二阶导 def loglikelood(preds, dtrain): labels = dtrain.get_label() preds = 1.0 / (1.0 + np.exp(-preds)) grad = preds - labels hess = preds * (1.0-preds) return grad, hess # 自定义前20%正样本占比最大化评价函数 def binary_error(preds, train_data): labels = train_data.get_label() dct = pd.DataFrame({'pred':preds,'percent':preds,'labels':labels}) #取百分位点对应的阈值 key = dct['percent'].quantile(0.2) #按照阈值处理成二分类任务 dct['percent']= dct['percent'].map(lambda x :1 if x <= key else 0) #计算评价函数,权重默认0.5,可以根据情况调整 result = np.mean(dct[dct.percent== 1]['labels'] == 1)*0.5 + np.mean((dct.labels - dct.pred)**2)*0.5 return 'error',result watchlist = [(dtest,'eval'), (dtrain,'train')] param = {'max_depth':3, 'eta':0.1, 'silent':1} num_round = 100 # 自定义损失函数训练 bst = xgb.train(param, dtrain, num_round, watchlist, loglikelood, binary_error)
展示一些过程图片