网上看到一个做EDA非常方便的模块pandas_profiling,使用该函数可以快速了解我们的数据构成以及分布,下面看看具体的实现
import seaborn as sns import pandas as pd import pandas_profiling import matplotlib.pyplot as plt #波士顿房价数据集 from sklearn.datasets import load_boston import pandas as pd boston=load_boston() boston.data boston.target boston.feature_names df=pd.DataFrame(boston.data,columns=boston.feature_names) pandas_profiling.ProfileReport(df)
但是要注意最后一行代码运行时间可能有点久,需要耐心等待
报告的一共有6点,如下图

第一点,总概述,包括shape,missing,内存,类别型变量和数值型变量的个数,重复行列
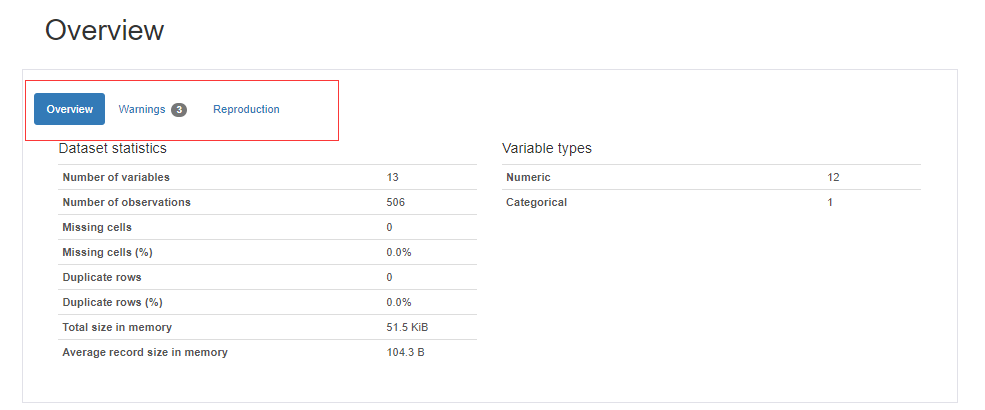
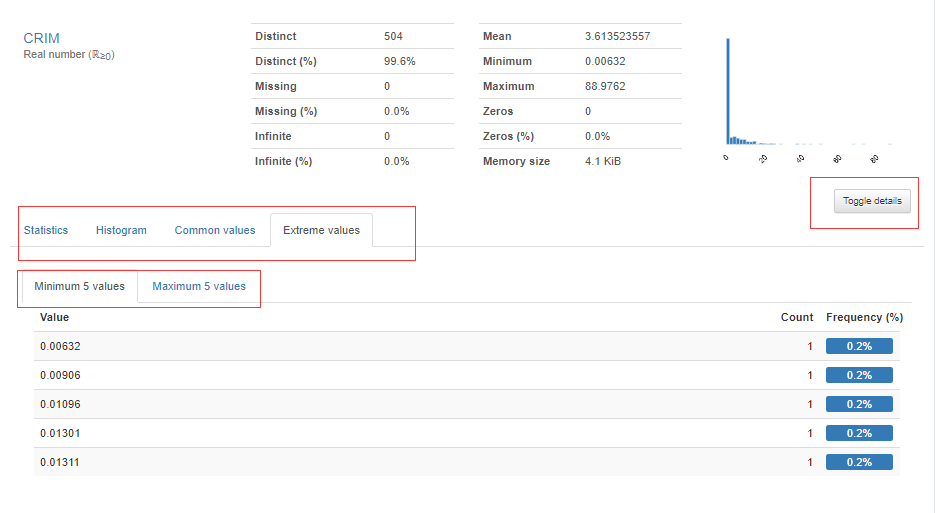
第二点,对每个变量进行描述性统计,可视化展示,这次只截图一个变量,其他的就不放上来了
第三点,双变量分析,通过画图,可看出两个变量之间的关系

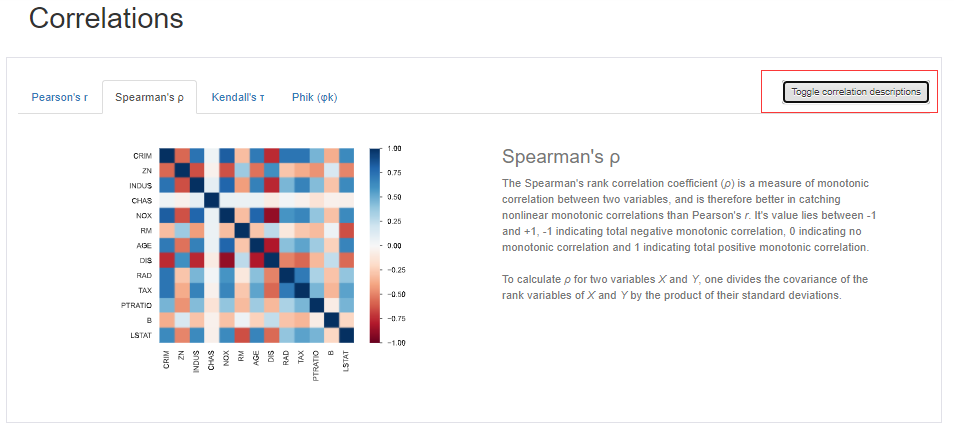
第四点,相关性地热图,有几种相关性的统计量可以选择,皮尔逊和斯皮尔逊等等,点击有上方的还可以出现每个统计量指标的说明,很贴心了

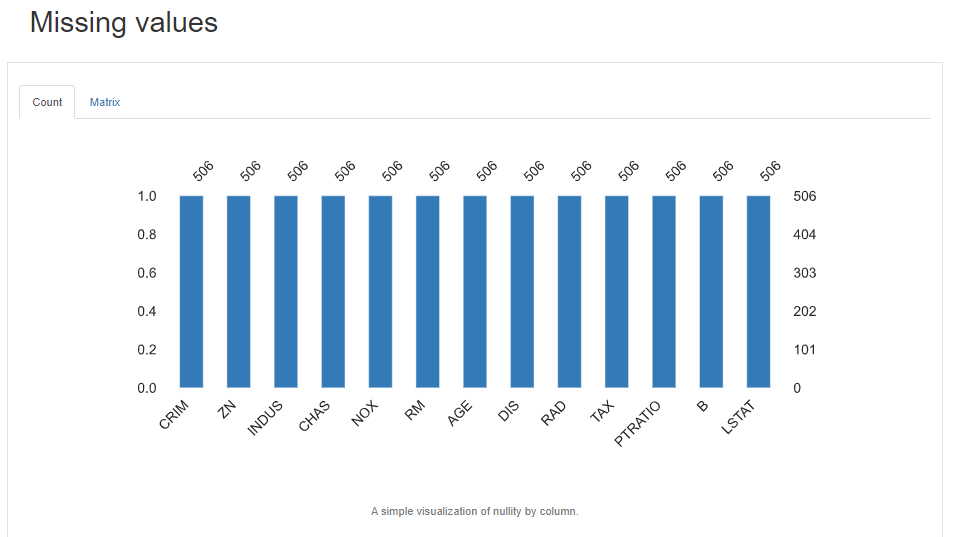
第五点,变量的缺失值,这个就没有啥好解释的了
第六点,样本前面几行和后面几行的展示
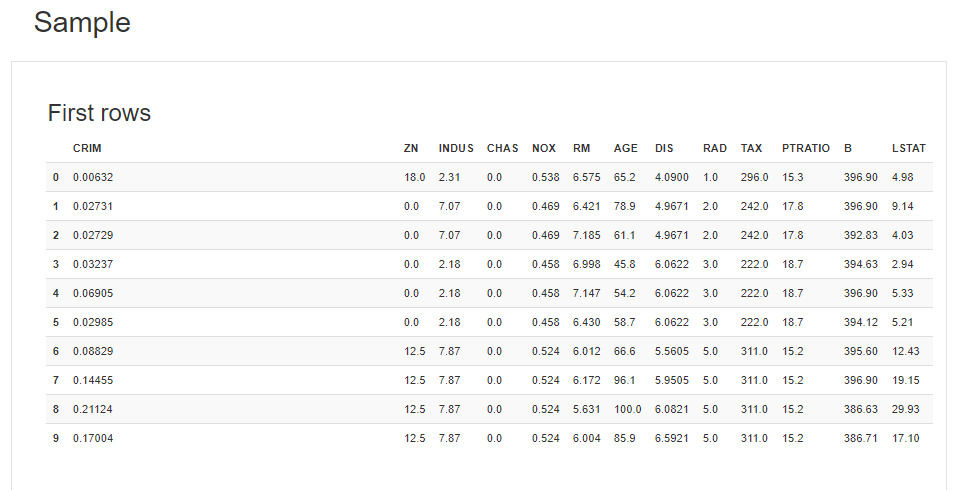
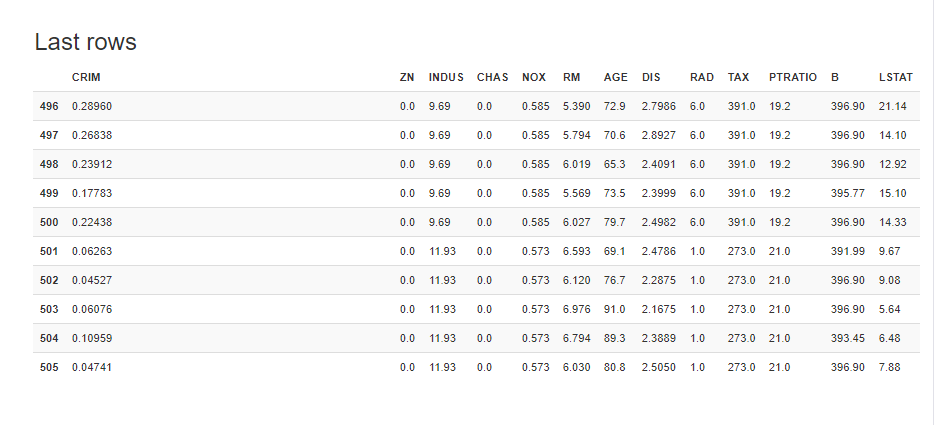
总结一下:
该工具方便我们快速了解数据构成,我们主要注意前面5点即可,但是并不是说使用该工具就完成了EDA步骤,我们想要挖掘更多信息,害得深入去研究数据