20191206 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1912
姓名: 陈发强
学号:20191206
实验教师:王志强
实验日期:2020年6月14日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
2. 实验过程及结果
爬取网站
-
初步选取[东方资讯:全球电影票房排行榜](https://mini.eastday.com/a/190505123024855.html)作为要获取的信息,和爬取对象。进去之后发现需要翻页,也就是说信息分布在好几个网页上。
-
发现,所搜结果的第n个的url 的特征参数 就是最后一位的数字,我们尝试令其依次等于1到n,发现东方咨询的所搜结果,除了首页都可以通过此url访问,至此所有所搜结果的url可以统一成一个形式,第n页的url = https://mini.eastday.com/a/190505123024855-n.html 至于第一页只好作为例外采用原本的网址
-
实现翻页操作:改变上面url的n值即可。
-
看一下robots协议 ,惊喜的发现没有限制
-
然后开始代码部分
import requests import re -
首先定义一个函数,实现对目标网页信息的获取,由于要不断的进行翻页,所以此函数会被不断调用,进而要引入异常处理保证程序不会中途停止或退出。我们用raise_for_status 方法来主动判断网页信息是否获取成功并如果不成功则产生异常
def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" -
再定义一个函数,对得到的网页信息进行解析,获取截取对我们来说有用的信息。我们通过查看网页的源代码,通过搜索找到有用的信息的字段,然后使用正则表达式对其进行截取

def parsePage(ilt, html): plt = re.findall(r'全球票房:[d.]{2,7}',html) tlt = re.findall(r'第[d]*名:《.{1,15}》',html) '''print(plt) print(len(plt)) print(tlt) print(len(tlt)) ''' for i in range(len(tlt)): price = eval(plt[i].split(':')[1]) title = tlt[i].split(':')[1] ilt.append([price , title]) -
再定义一个把商品信息输出到屏幕上的函数
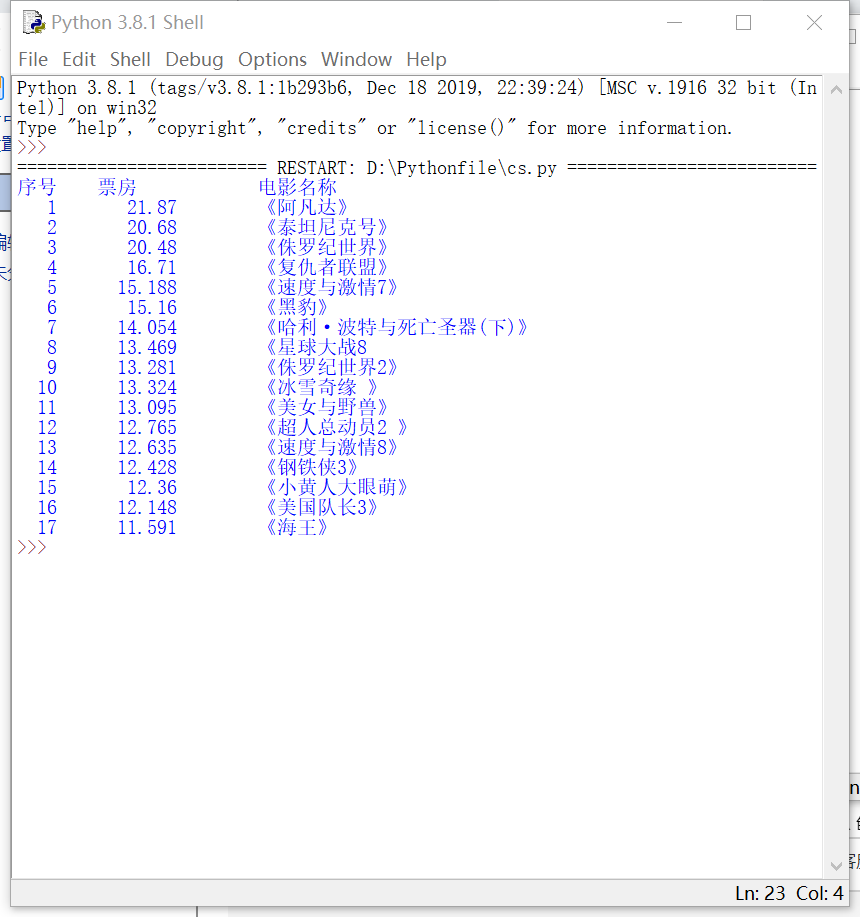
def printGoodsList(ilt): tplt = "{:4} {:8} {:16}" print(tplt.format("序号", "票房", "电影名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1])) -
最后定义一个主函数并运行主函数。使用循环实现翻页操作,属于例外的首页信息先手动将其存储进变量html中即可
def main(): start_url = '''https://mini.eastday.com/a/190505123024855-''' infoList = [] url = '''https://mini.eastday.com/a/190505123024855.html?qid=02263''' html = getHTMLText(url) for i in range(2,7): url = start_url+str(i)+'.html' html += getHTMLText(url) parsePage(infoList, html) printGoodsList(infoList) main()
实验结果
3. 实验过程中遇到的问题和解决过程
- 问题1:不会翻页操作,如果信息只是分布在一个网页上,还会处理,如果分布在多个网页上就不会了
- 问题1解决方案:百度了下,通过学习别人的经验并仔细观察各个页面之间的url的区别与联系,发现同一个系列的网页的url通常不会是完全不一样的,大多情况下存在着或多或少的联系,即url之间是相似的,这一系列url中很可能存在一个或几个特征值来进行彼此间的区分,我们只要抓住特征值的变化规律,就能通过规律构造函数,进而通过循环实现这一系列网站间的自动跳转访问、信息爬取。
- 问题2:网页上的信息拿到后不会截取有用的信息
- 问题2解决方案:由于之前的云班课里看过有关正则表达式的课程,有点印象,所以就想着能不能应用正则表达式来解决,因为我从网页上爬取下来的信息也是字符串的形式,如果能用正则表达式对其进行匹配,就有可能做到信息的截取。所以我上网搜了搜正则表达式和爬虫,并通过仔细观察要爬取的一系列网页,发现有用的信息的格式都是规范的,也就是说,可以通多多个正则表达式,实现对多种有用信息的截取。接下来就是重新学习和运用正则表达式了。
全课总结(感悟、思考等)
- 现在回想,本学期的收获还是很大的,由于C语言开课比python晚了那么一点点,python成了我第一门接触到的编程语言。回想几个月前连基本数据类型和输入输出都搞不明白的我,真是感触良多。
- 本学期我们首先初识了python,了解了python的发展历程、未来前景和优势 。超级语言是指粘性整合已有程序,具有庞大的计算生态,可以很容易利用已有代码的功能,编程思维不再是刀耕火种而是集成开发,不重复制造轮子,python是目前唯一的超级语言,其前进的步伐不可阻挡。
- 接着在学习了输入输出后,我们学习了基本数据类型:整数类型,四种进制表示形式、浮点类型,浮点数间运算存在不确定的尾数,不是bug,例如:0.1+0.2=0.3000000004,原因:二进制与十进制不是严格的对等关系,python用53位二进制表示小数,是无限接近而不是完全对等。0.1+0.2==0.3,输出false,科学计数法表示,使用e或E作为幂的符号,底为10 复数类型,只有python语言提供了复数类型,Z == 1.23e-4+5.6e+89j 字母j表示虚数单位,Z.real 获取实部 z代表某一数据,Z.imag 获取虚部
- 字符串类型,单引号,双引号,都只能表示一行字符串,三单引号,形成的是多行字符串,但也可以当多行注释来使用。正向递增序号、反向递减序号,索引和切片[ : ],字符串的操作符,字符串处理函数,字符串处理”方法”字符串类型格式化等等。
- 接着我们学习了python的分支语句(分支结构)if elif else 和循环语句(循环结构)while for continue break,
- 接着我们学习了组合数据类型 首先是列表组合数据类型—序列。序列基本处理方法,六个操作符:(1)X in s(2)X not in s(3)S + t(4)S * n(5)S[ ](6)S [ : : ] 5个函数或方法(1)Len( )返回长度(2)Min(s)返回最小元素,前提是:这组数据中的所有元素可以比较大小
(3)Max(s)返回最大元素(4)S.index( x, (i,j) ) 找到x(从i,到,j)第一次出现的位置(5)S.count(x) 元组类型 特点:元组一旦被创建,就不能被修改应用场景:保护数据 列表类型 特殊操作:(1)Ls [ i ] = x :赋值(2)Ls [i :j :k]= lt :对切片赋值(3)Del ls[i] :删除(4)Del ls[i: j: k] :删除切片(5)Ls.insert(i,x):在i处插入x(6)Ls.pop(i):取出i位置的元素(7)Ls .remove(x):只删除第一个x(8)Ls.revers() :反转列表(9)Ls.sort():从小到大排序(10)Ls.sort(reverse = True):从大到小排序。 - 之后我们又学习了集合与字典 集合间的运算 S|T 并集 S-T 减去T中元素 S&T 交集S^T 返回不同时在S、T中的元素 关系操作符 s<T 即s包含于T 集合的应用场景 包含关系的比较。即,判断一组数据与另一组数据的关系。例如,数据a中,与数据b,有多少元素相同,不同... 最重要的应用是数据去重。只要set(A),把其他的数据类型变成集合,就实现了数据去重。字典是数据组织 与表达的一种新形态。新:用户可以自定义 键值对。字典类型 真的就像创建一本字典一样,用的时候,也真的像查字典一样字典的创建:{ } or dict( )键值对 用冒号表示。键值对之间用逗号隔开 字典的索引 [ 键 ] ,操作中,键值对通常作为一个操作整体对象 操作中,参数一般是“键”,因为键是用户已知的,而值一般是未知的。增加或修改 元素 dictionary[ key ] = value Del dictionary[ k ] 删除k键对应的键值对 K in dictionary k键是否在字典里 value in dictionary 是不可行的Dictionart.keys( ) 返回字典中的所有“键” Dictionary.values( ) 返回字典中所有“值” Dictionary.items( ) 返回字典中所有“键值对” 注意:返回的 dict_keys ( [ ] ) 可以做遍历,但不能做列表类型的操作 D.get( k (,default)) 如果k键存在,返回对应值,如果不存在,返回参数default D.pop(k, (default)) 同上,取出k对应的值 D.popitem( ) 随机从字典中取出一个键值对,并以元组形式返回 D.clear Len(d) 返回键值对的个数。
- 之后我们学习了函数,def return 初步体会了代码复用和封装的感觉。体验了递归算法,汉诺塔问题令人印象深刻。接着我们学习了文件操作,一、文件的打开和关闭A = open(文件路径和名称,打开模式)文件路径。由于是转义符,所以路径中的用/替换。绝对路径。从硬盘开始 ,例如”D:/pythonfile/三国演义.txt” 相对路径。我理解为,当程序与文件在同一目录,或文件在程序子目录下时使用。例如 程序在D盘根目录 “./pythonfile/三国演义.txt” 打开模式 ‘r’ :只读模式 ‘w’ :覆盖写模式。相当于先清空文件,再向文件中写入。如果文件不存在,将创建一个文件。 ‘a’ :追加写模式。在原文件的后面,继续写入内容。如果文件不存在将创建一个文件。 ‘b’ :二进制形式打开文件 与r,w,a, 组合 例如,wb 默认参数 ‘t’ : 以文本形式打开文件。 与r,w,a 组合 + :组合功能,使具备同时读写的能力。W+ r+ a+ ...读文件:a.read() a .readline() a .readlines() 写文件 a .write(str) a .writelines(list)a .seek(offset)a .close()
- 之后我们介绍了面向对象程序设计 三要素:封装、继承、多态 介绍了对象、类,class 如果类是盖楼的图纸,那么对象就是盖好的大楼__init__()方法,创建数据成员和方法并访问,访问限制。接下来我们学习python的模块,Modules 模块,提高代码重用性和可维护性,if name == 'main':的作用,Python包以及python的异常处理,try except else finally 。接着我们学习了socket套接字,自己感受了对服务器和客户端的模拟,其中还有一些密码学的知识,像国密算法什么的,令人心潮澎湃、印象深刻。最后就是网络爬虫,当初真的没想到python选修会讲到网络爬虫,虽然现在还不是很会,但我决定真的是太酷了。十分感谢老师领我并提供契机让我初识了网络爬虫,乃至计算机网络,web编程。
- 首先我感觉我们的课程的进度安排的非常好,不仅讲解了python的基本语法,还学习了python的实践应用,让我深刻感受到python的重大优势就在于庞大的第三方库。云班课的资料也非常丰富,但也同时考虑到了同学的水平差距和时间精力问题,没有做硬性要求,我觉得这也是很明智的。王老师上课也比较风趣幽默,课堂的内容也比较比较吸引人,我觉的这是区别的其他编程课程的优势。王老师全天答疑,我觉得只是非常难能可贵的,让我肃然起敬。而且在答疑的过程中,老师还指点我让我学会提问,让我受益匪浅。让我提建议的话,很真没什么改革性的建议,一些小小的建议就是,异常处理的介绍,也许可以再提前一点,和分支循环放在一起,而不是和模块放在一起。讲网络爬虫的时候可以再多一些,对网页源代码,超文本标记语言,JavaScript的介绍,至少带我们和源代码混个脸熟。