了解srcapy、Mongodb、pycharm
打开知乎官网——点开某个用户——点开该用户所关注的人——爬取他所有关注的用户
首先win+R打开cmd终端——到某个盘下(例子中是在D盘下)建立项目文件步骤如下:
1.在cmd中输入(D盘某个文件下)scrapy startproject zhihuuser 回车
继续输入 cd zhihuuser 回车——scrapy genspider zhihu zhihu.com 回车

2.到所建的那个盘下找到zhihuuser并用Pycharm打开——spider——zhihu.py
3.打开settings.py 文件将此处的True改为False,并将知乎中的User—Agent添加到此处。(User—Agent是在用户界面——右键—检查—network—Header)


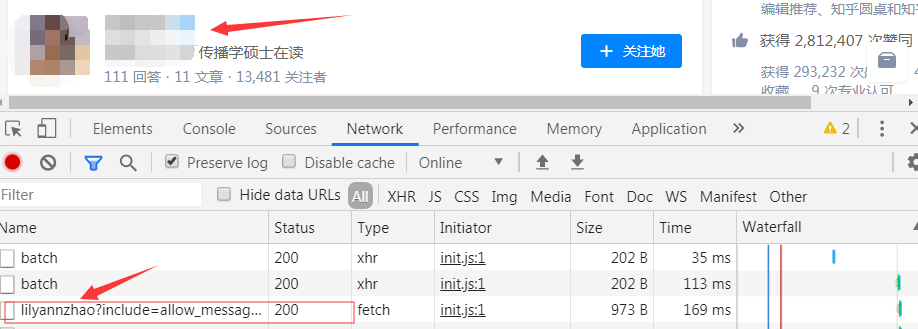
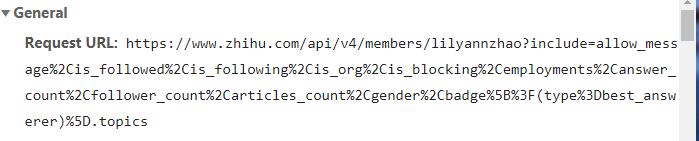
4.在此用户下的关注用户的列表下——随机点他所关注的一个用户——查看network——****(你点的那个用户的)?include=allow_m.......——Headers复制Request Url中链接和尾页中的include的链接

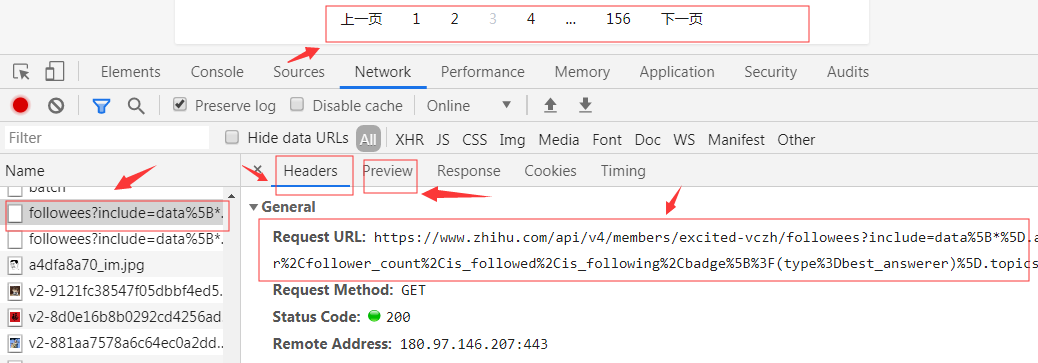
5.打开items.py文件 点开网页中的preview按键 将图中的及以下的所有红色字符添加到items文件中 代码如下所示:
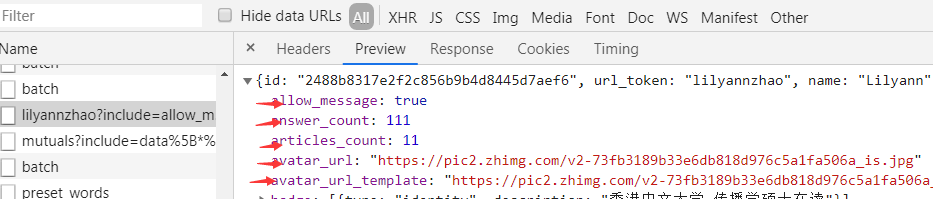
from scrapy import Item, Field class UserItem(Item): # define the fields for your item here like: # name = scrapy.Field() id = Field() name = Field() avatar_url = Field() headline = Field() type =Field() uid = Field() url =Field() url_token = Field() user_type =Field() rename_days = Field() avatar_url_template =Field() ad_type = Field() gender = Field() default_notifications_count = Field() messages_count = Field() vote_thank_notifications_count = Field() follow_notifications_count = Field()
6.打开pipelines.py文件 将所爬取到的数据放在Mongodb中 代码如下所示:
import pymongo class MongoPipeline(object): collection_name = 'scrapy_items' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE', 'items') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): self.db['user'].update({'url_token':item['url_token']},{'$set':item},True) return item
7.打开zhihu.py文件 写下代码
1 # -*- coding: utf-8 -*- 2 from scrapy import Spider,Request 3 4 from zhihuuser.items import UserItem 5 import json 6 7 8 class ZhihuSpider(Spider): 9 name = 'zhihu' 10 allowed_domains = ['zhihu.com'] 11 start_urls = ['http://zhihu.com/'] 12 13 start_user = 'excited-vczh' 14 15 user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}' 16 user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' 17 follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' 18 follows_query ='data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' 19 20 followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' 21 followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' 22 23 def start_requests(self): 24 yield Request(self.user_url.format(user = self.start_user,include = self.user_query),self.parse_user) 25 26 yield Request(self.follows_url.format(user = self.start_user,include = self.follows_query,offset = 0,limit = 20),callback=self.parse_follows) 27 28 yield Request(self.followers_url.format(user = self.start_user,include = self.followers_query,offset = 0,limit = 20),callback=self.parse_followers) 29 30 def parse_user(self, response): 31 result = json.loads(response.text) 32 item = UserItem() 33 for field in item.fields: 34 if field in result.keys(): 35 item[field] = result.get(field) 36 yield item 37 38 yield Request(self.follows_url.format(user = result.get('url_token'),include = self.follows_query,limit =20,offset = 0 ),self.parse_follows) 39 yield Request(self.followers_url.format(user = result.get('url_token'),include = self.followers_query,limit =20,offset = 0 ),self.parse_followers) 40 41 42 def parse_follows(self, response): 43 results = json.loads(response.text) 44 45 if 'data' in results.keys() : 46 for result in results.get('data') : 47 yield Request(self.user_url.format(user = result.get('url_token'),include = self.user_query),self.parse_user) 48 if 'paging' in results.keys() and results.get('paging').get('is_end') == False : 49 next_page = results.get('paging').get('next') 50 yield Request(next_page,self.parse_follows) 51 52 53 def parse_followers(self, response): 54 results = json.loads(response.text) 55 56 if 'data' in results.keys() : 57 for result in results.get('data') : 58 yield Request(self.user_url.format(user = result.get('url_token'),include = self.user_query),self.parse_user) 59 if 'paging' in results.keys() and results.get('paging').get('is_end') == False : 60 next_page = results.get('paging').get('next') 61 yield Request(next_page,self.parse_followers)
8.打开Robo 可以查看数据