Hive用于对数据进行ETL(extract/tranform/load)
1.load file data to database E
2.使用select / python 进行转换 T
3.数据转换后在sub表中 L
Hive官方网站
Gettingstarted
![]()
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hiva 数据仓库软件便于使用SQL语句读,写,和管理分布式存储大型数据集。该结构可以投射到已经存在的仓库中。提供了一个命令行工具和JDBC驱动程序将用户连接到Hive。
(重点)通俗地说:Hive是Hadoop三大原始框架的上层封装,将结构化的数据文件映射成一张表,并通过HiveQL(HQL)查询功能
处理的数据存储在HDFS中
分析数据的底层实现MapReduce
执行程序运行在YARN上
Hive架构(重点)
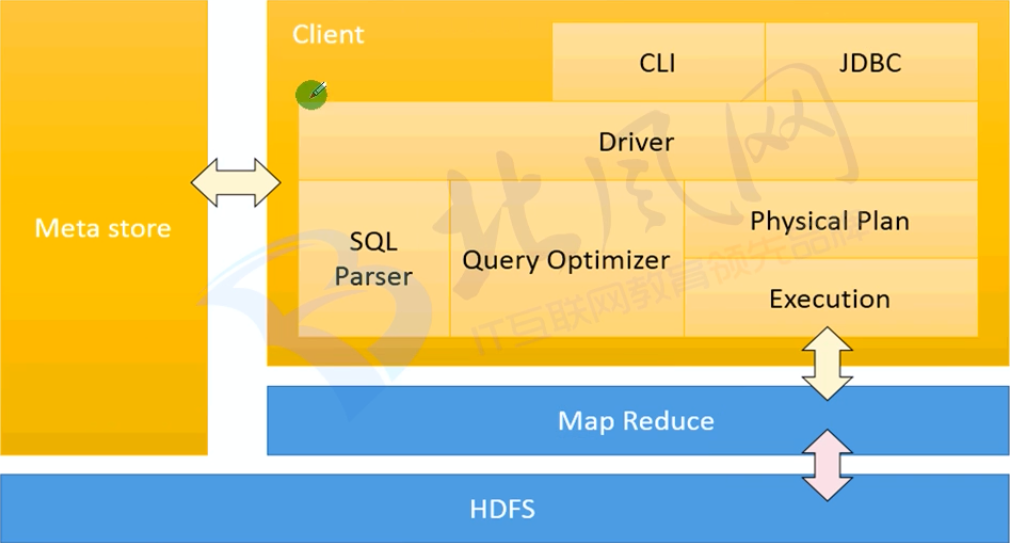
Client:用户接口
1.CLI:Hive shell
2.JDBC/ODBC
3.WebUI:浏览器访问
Meta store:存储元数据信息,默认存储在自带的DerBy数据库中, 推荐使用MySQL存储Metastore
1.表名
2.所属数据库,默认是Default
3.拥有者
4.字段
5.表的类型
6.数据所在目录
Dirver:驱动,包含以下三个部分,将SQL语句转换成MapReduce程序
1.SQL Parser:SQL语句解析
2.Query Optimizer:查询优化
3.Physical Plan:物理计划
4.Execution:执行物理计划