题目大概就是利用企业发票的信息分析出企业是否为异常企业,其中企业一共有3万多家,
发票数大约有400多万条信息,发票明细信息有1000多万条信息
因为之前已经采用一些分析的方法找到了321家异常企业,所以对发票表进行分析,
利用sklearn建立决策树模型,并利用训练集对其进行训练,最后对测试数据进行预测。
一、环境准备
python
sklearn
panda
二、数据准备
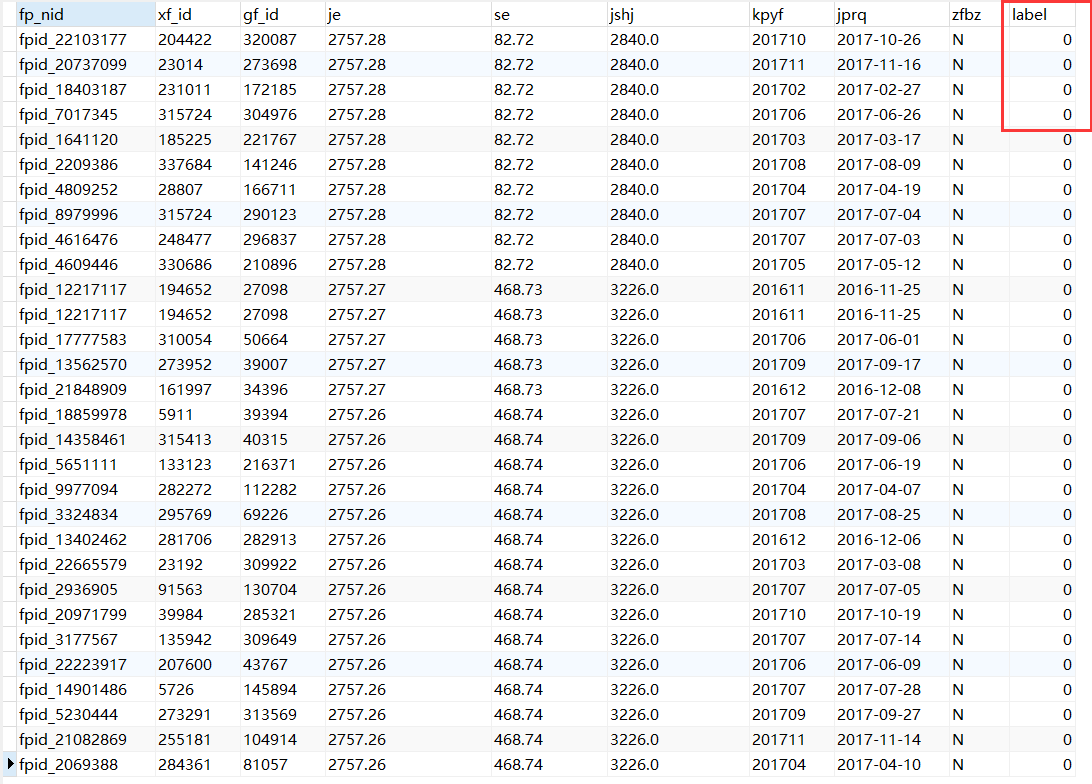
首先将原数据表拆分为两个表分别作为训练数据集和测试数据集
在训练数据集中增加一个字段label表示该条信息是否为问题数据,0为正常,1为有问题
三、读入文件(利用panda读入文件)
将训练数据集以及测试数据集读入到程序中
#读取CSV 文件 train_data=pd.read_csv(r'. rain1.csv') test_data=pd.read_csv(r'. est1.csv')
四、特征选择
对训练数据集进行特征属性的选择
# 3特征选择 features=['xf_id', 'gf_id', 'je', 'se', 'jshj', 'zfbz']#表内数据特征 train_features=train_data[features] train_labels=train_data['label'] test_features=test_data[features]
五、创建ID3决策树
利用sklearn创建决策树模型
#4 创建ID3决策树 clf=DecisionTreeClassifier(criterion='entropy') test_features=dvec.fit_transform(test_features.to_dict(orient='record')) clf.fit(train_features,train_labels)
六、优化模型
利用k折交叉验证,统计决策树准确率,提高正确率
#k折交叉验证,统计决策树准确率,提高正确率 from sklearn.model_selection import cross_val_score import numpy as np print(u'cross_val_score 准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
七、测试数据预测并存储结果
#预测测试数据
test_predict1=clf.predict(test_features)
print(test_predict1)
#存储预测结果
temp = pd.DataFrame(test_predict1)
temp.to_csv('D:\test\3\3.csv')
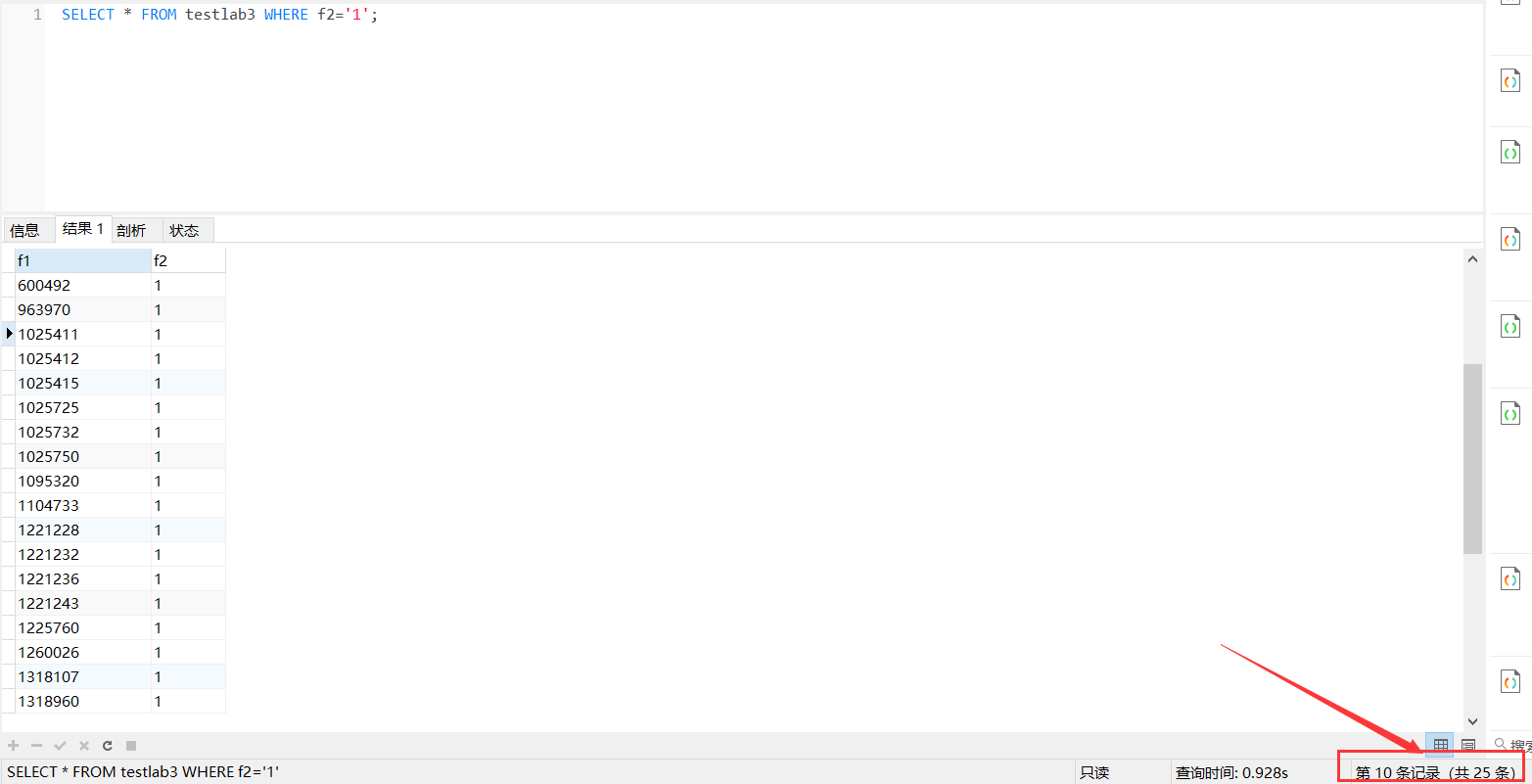
最后对预测结果进行分析,发现测试数据中有25条数据,加上训练数据集中的278条数据,一共是303条记录,结果还算是比较不错的啊
最后的最后,整个的源代码是参考一个泰坦尼克预测生存率的代码,