1.最晚入职的时间
select * from employees order by hire_date desc limit 1
limit应放在最后
order by默认升序asc。降序是desc
最晚入职的时间应该使用降序,这样年份偏大 ,时间最晚。
2.倒数第三入职
select * from employees order by hire_date desc limit 2,1
limit用法 后面1个参数 表示 几行
后面2个参数 表示 偏移量,几行(limit 5,2)的意思就是展示6-7行数据
因为mysql初始偏移量是从0开始的。limit 5 相当于 limit 0,5
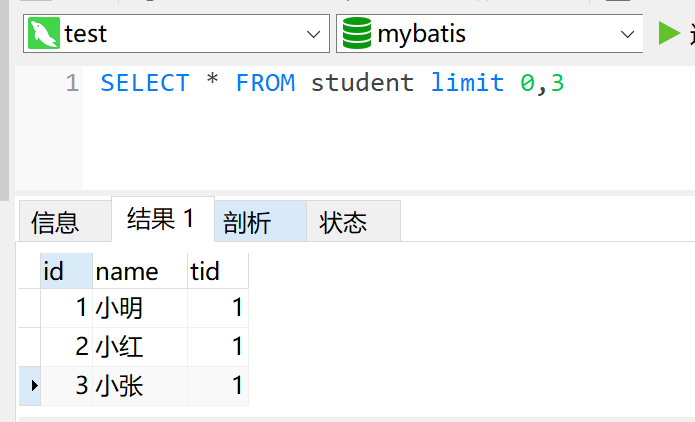
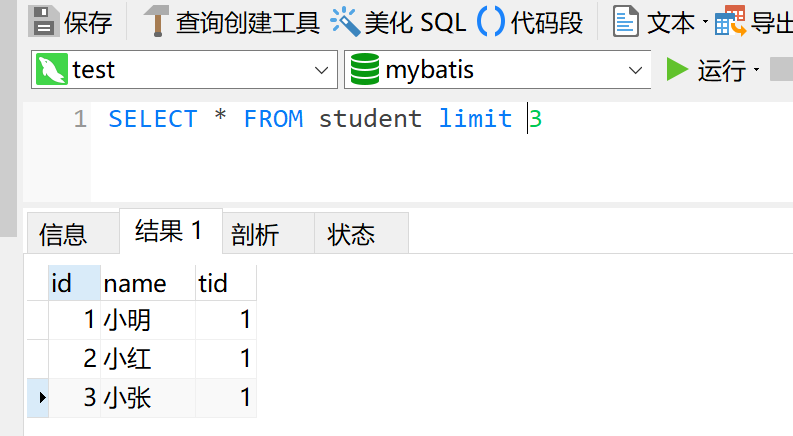
倒数第三入职就是从第二个开始的第一行数据。
3.领导薪水
select s.*,d.dept_no from salaries s,dept_manager d
where s.to_date="9999-01-01"
and d.to_date="9999-01-01"
and s.emp_no=d.emp_no
两表进行笛卡尔积。其中硬性规定todate是因为当有员工辞职,todate会更新为离职时间。
只有9999-01-01才是在职的人。
笛卡尔乘积是类似全排列。
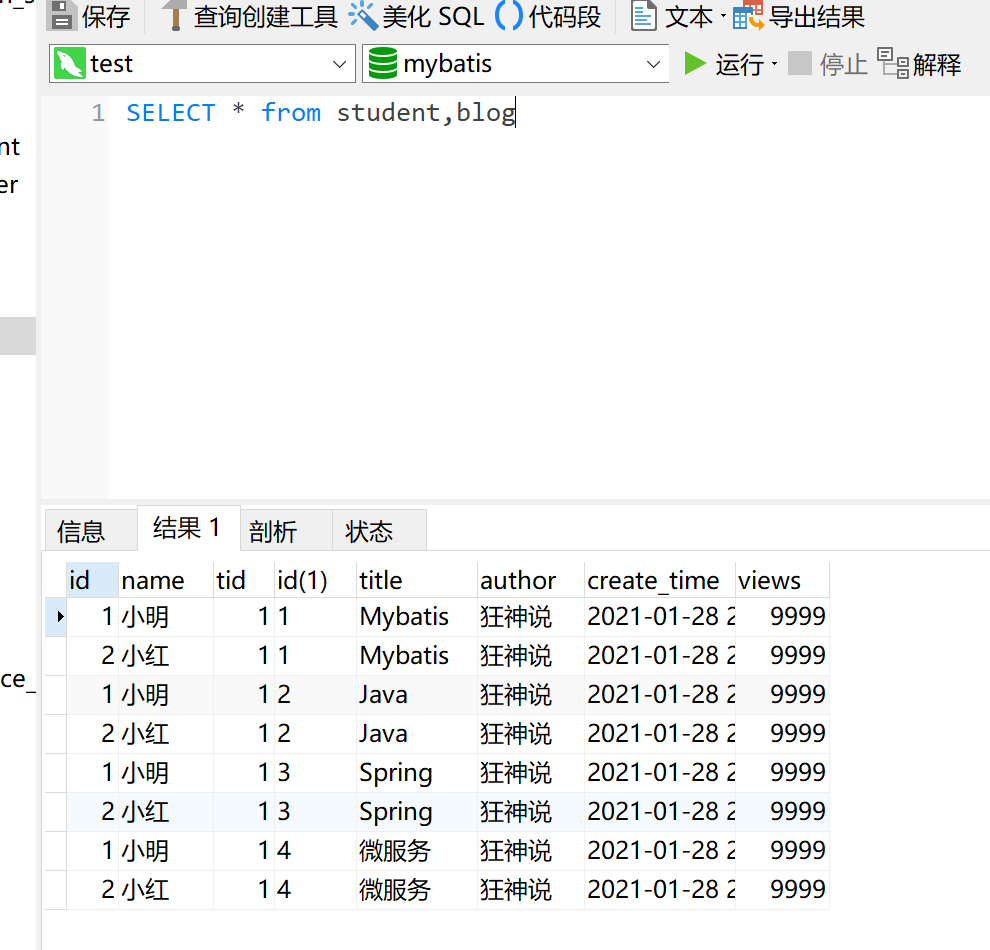

普通的多表查询,内部还是笛卡尔积的逐行的搜索机制,如果查询的几张表数据量大的话会降低性能;
第二种是内连接。两种方式得到的结果是一致的。
两者没什么区别,在执行方式和效率上都是一样的,只是书写的方式不同,
基本上inner join 是为了区别 left join ,right join等的一个写法,而另外那种不是join的写法,只能等同于inner join
4.已分配部门的人
select e.last_name,e.first_name,d.dept_no
from employees e, dept_emp d
where d.to_date="9999-01-01"
and e.emp_no=d.emp_no
5.已分配的人 没分配用null
select e.last_name,e.first_name,d.dept_no
from employees e left join dept_emp d
on e.emp_no=d.emp_no
左连接典型题目。

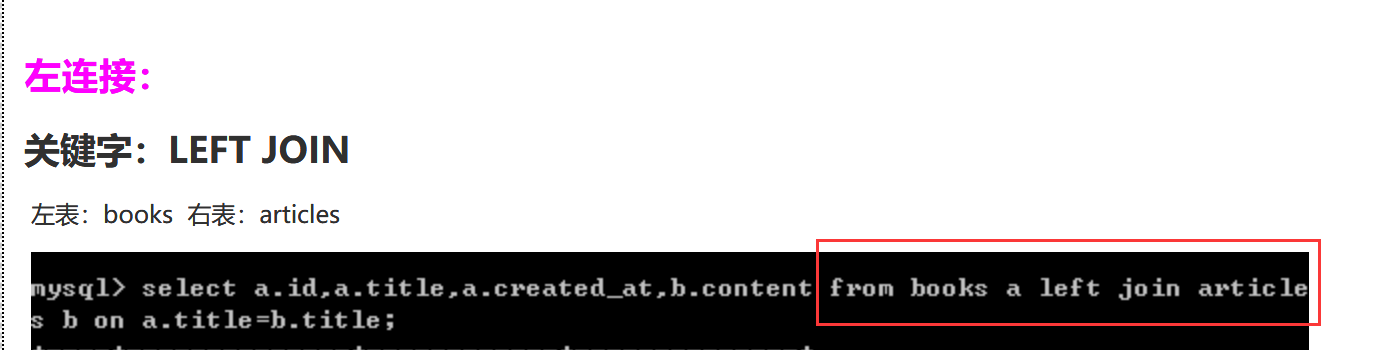
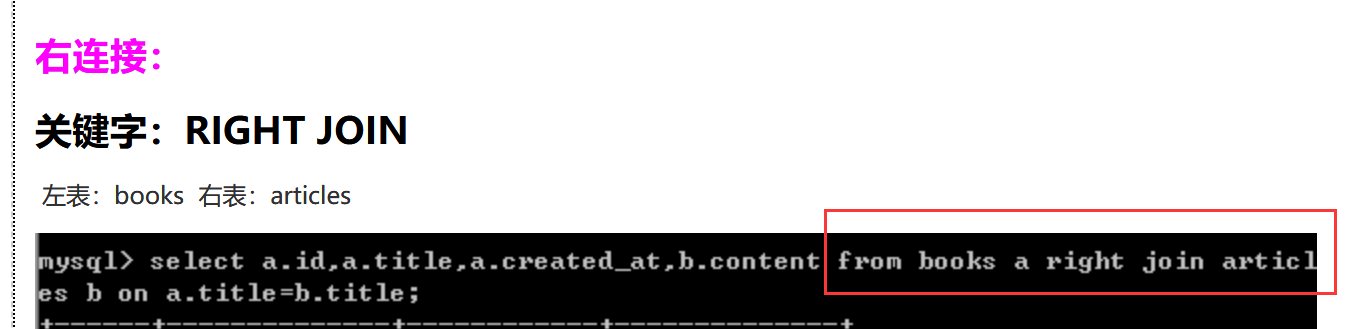
7.薪资变动
select emp_no, count(*)t
from salaries
group by emp_no
having t>15
计算行数count函数。其中利用group by进行分组 having进行分组的筛选。
如何计算涨薪变化
select a.emp_no,count(*) t
from salaries a inner join salaries b
on a.emp_no=b.emp_no and a.to_date = b.from_date
where a.salary<b.salary
group by a.emp_no
having t>15
使用一个内连接。这样在同一个编号下 且离职时间和入职时间相同。新入职时间薪水大于离职时的。
8.查询不同的薪水 且按降序排列
select distinct salary
from salaries
order by salary desc
考察distinct关键字以及降序desc
10.非部门领导
select e.emp_no
from employees e left join dept_manager d
on e.emp_no=d.emp_no
where d.dept_no is null
考虑左连接后 无法对上的是null
11.职工与其对应的部门领导(非自己)
select de.emp_no,dm.emp_no as manager
from dept_emp de inner join dept_manager dm
on de.dept_no = dm.dept_no
where de.emp_no<>dm.emp_no
12
13.请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
select emp_no,birth_date,first_name,last_name,gender,hire_date
from employees
where emp_no % 2=1 and last_name <> "Mary"
order by hire_date desc
在这道题可以看出 在where条件里面可以用 计算符号。
12.请你统计出各个title类型对应的员工薪水对应的平均工资avg。结果给出title以及平均工资avg,并且以avg升序排序,
select t.title ,avg(s.salary)
from titles t inner join salaries s
where t.emp_no=s.emp_no AND s.to_date = '9999-01-01' AND t.to_date = '9999-01-01'
group by t.title
因为select后面没写逗号 导致提交了12次也是没谁了
13.请你获取薪水第二多的员工的emp_no以及其对应的薪水salary
select emp_no,salary
from salaries
order by salary desc
limit 1,1
取正数第二名 需要降序排列+隔一个取
14.请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成
15.将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
select concat(last_name," ",first_name) as Name
from employees
concat函数的考察 如果指定的是列 不需要+双引号。加了双引号就是字符串的意思了。
16.
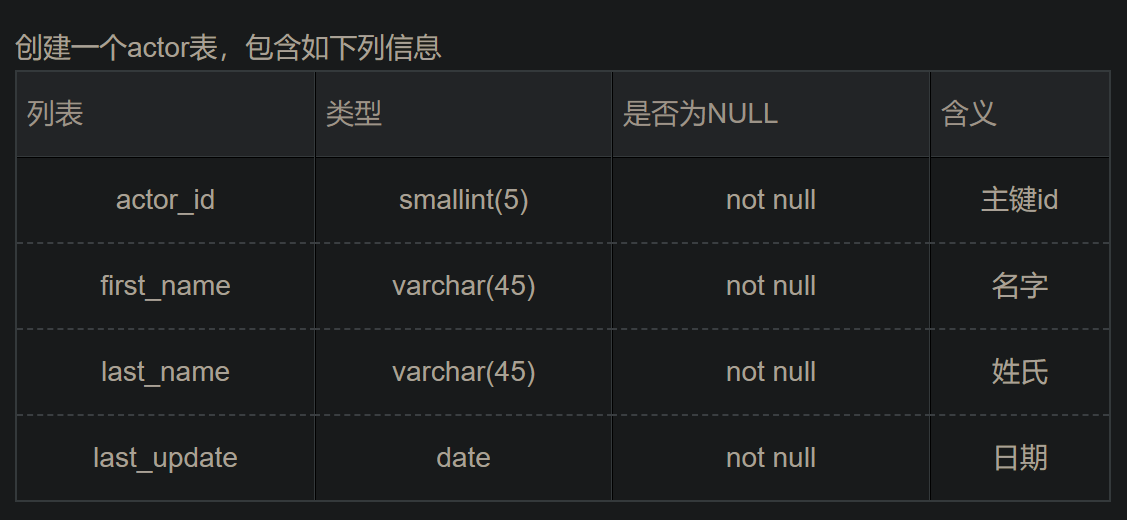
create table if not exists `actor`(
actor_id smallint(5) primary key not null comment '主键id',
first_name varchar(45) not null comment '名字',
last_name varchar(45) not null comment '姓氏',
last_update date not null comment '日期'
)engine=innodb default charset=utf8;
注意if not exists要放在表名前面。
comment是含义的意思
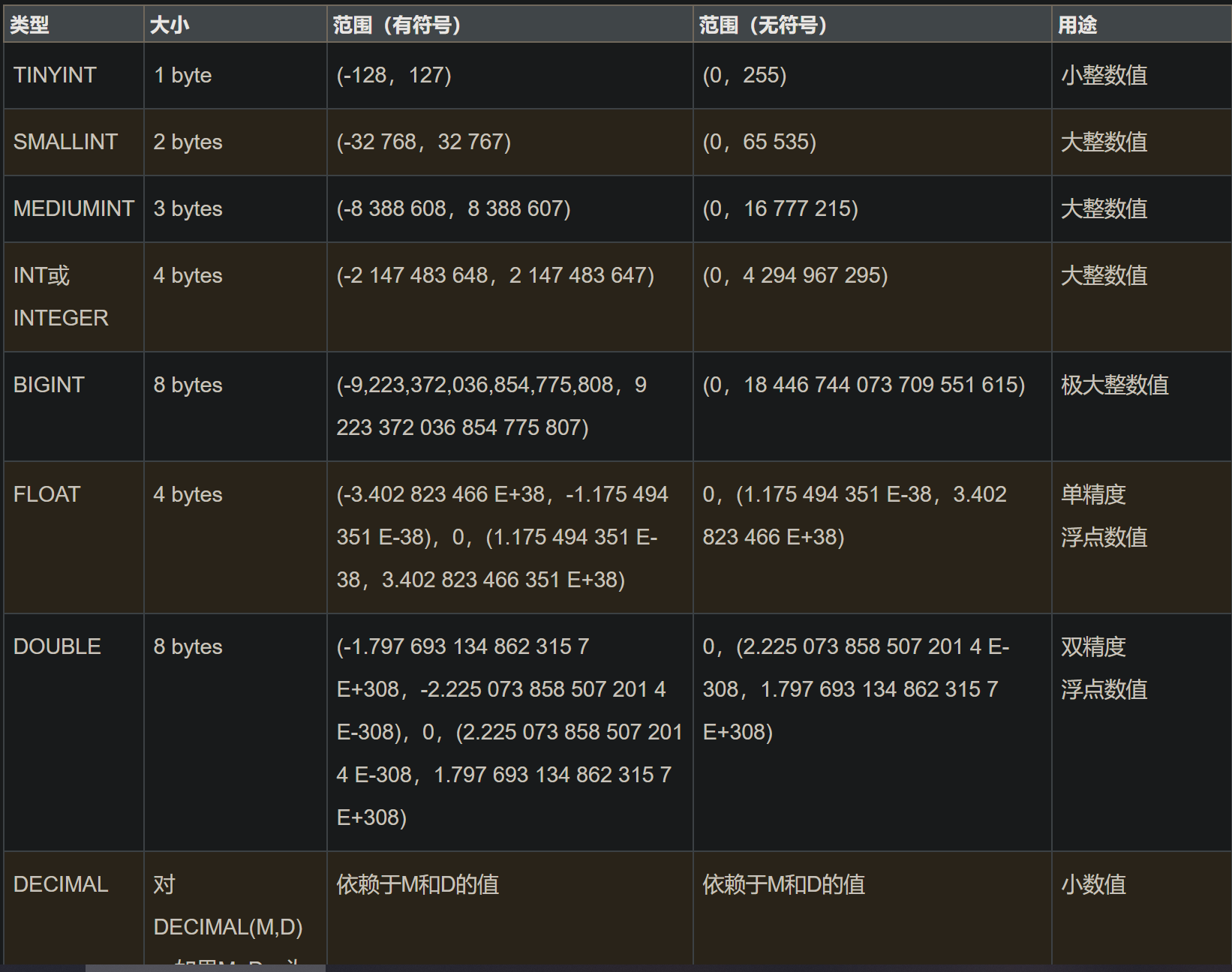
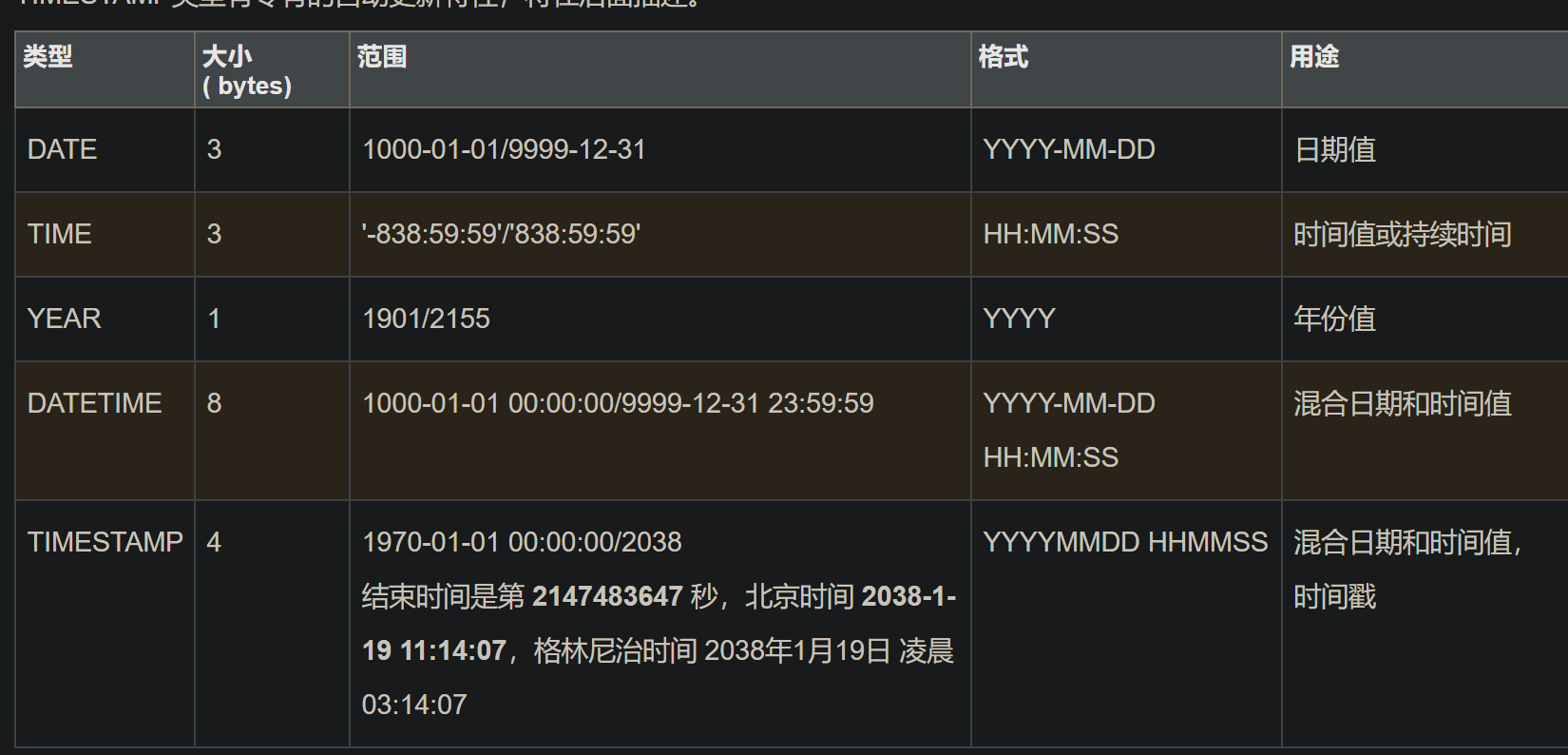
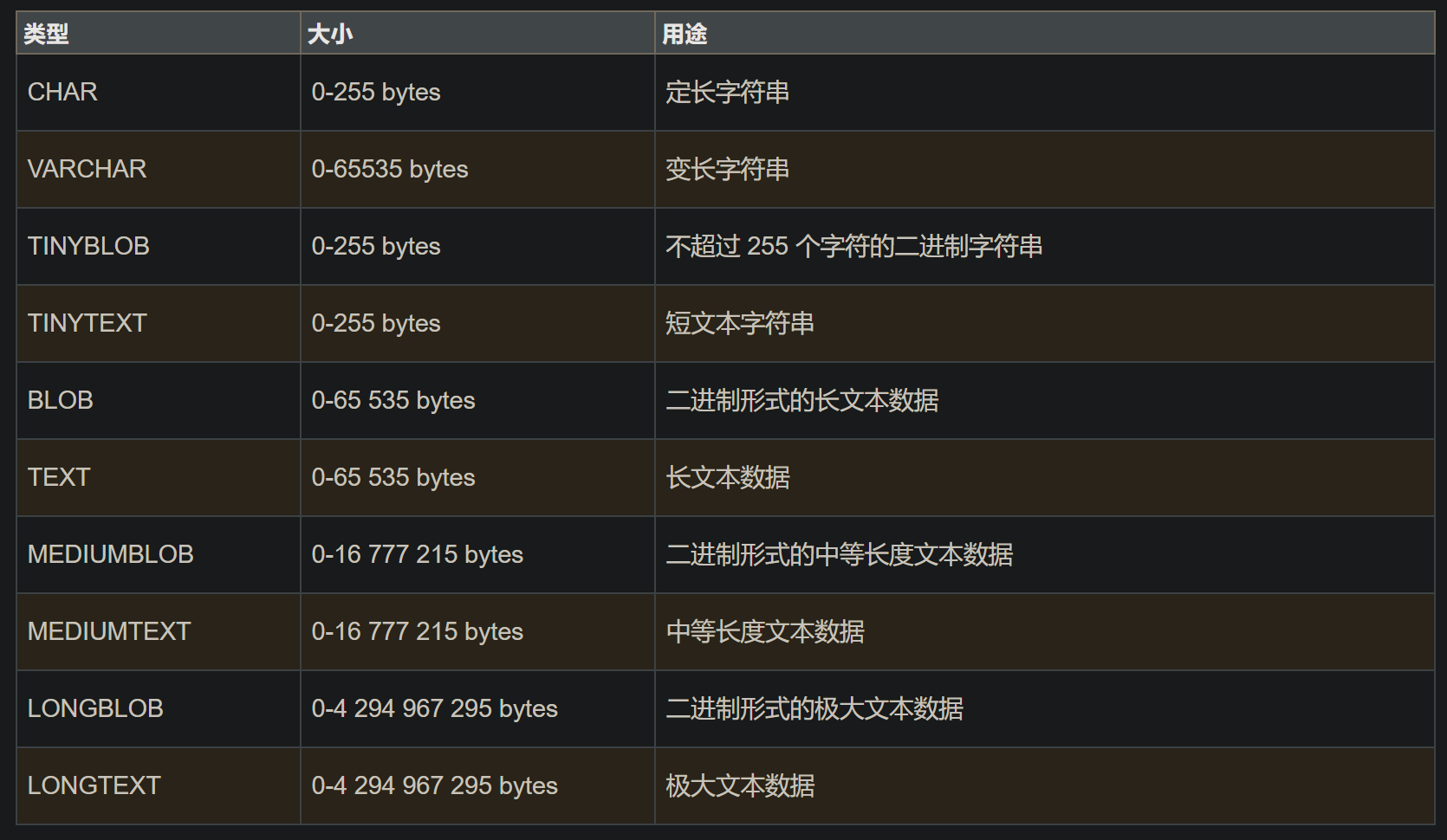
MySQL的数据类型
17.插入2条数据 只用1个insert
insert into actor
values(1, 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'),
(2, 'NICK', 'WAHLBERG', '2006-02-15 12:34:33')
或者
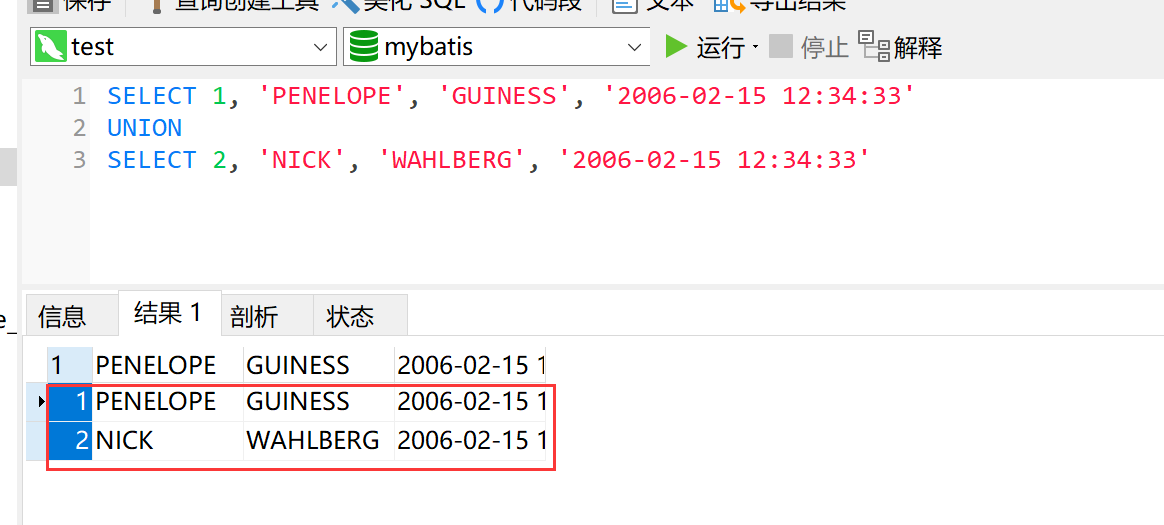
insert into actor
select 1, 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'
union
select 2, 'NICK', 'WAHLBERG', '2006-02-15 12:34:33'
18.插入数据 如果已经存在则忽略
insert IGNORE into actor
values(3,'ED','CHASE','2006-02-15 12:34:33');
考验ignore的用法
19。创建表 并插入别表数据(两条sql不要忘记加分号啊啊啊啊)
create table actor_name(
first_name varchar(45) not null comment '名字',
last_name varchar(45) not null comment'姓氏'
);
insert into actor_name select first_name , last_name from actor
20.mysql创建索引
alter table actor add unique uniq_idx_firstname (first_name);
alter table actor add index idx_lastname (last_name);
