例如下图,sn为s002有三个重复数据,要求查询时,s002只拿Id=4的那条
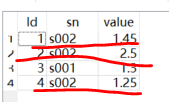
方法是利用group by ,利用Id为唯一标示符(自增长),对按sn进行排列,然后取重复项最大Id(非重复项直接取唯一Id),从而滤除重复的数据。
sql代码是
select * from test where Id in (select max(Id) from test group by sn)
得到的结果为:

例如下图,sn为s002有三个重复数据,要求查询时,s002只拿Id=4的那条
方法是利用group by ,利用Id为唯一标示符(自增长),对按sn进行排列,然后取重复项最大Id(非重复项直接取唯一Id),从而滤除重复的数据。
sql代码是
select * from test where Id in (select max(Id) from test group by sn)
得到的结果为: