上周去参加了2016 DTCC(数据库技术大会),会议总共持续3天,议题非常多,我这里搜集了最新的公开的PPT内容,有兴趣的同学可以下载看看,PPT合集下载链接为:http://pan.baidu.com/s/1i4XDESX。以下内容是我对听的几个议题的一点总结,并欢迎讨论。
《时间序列存储引擎》
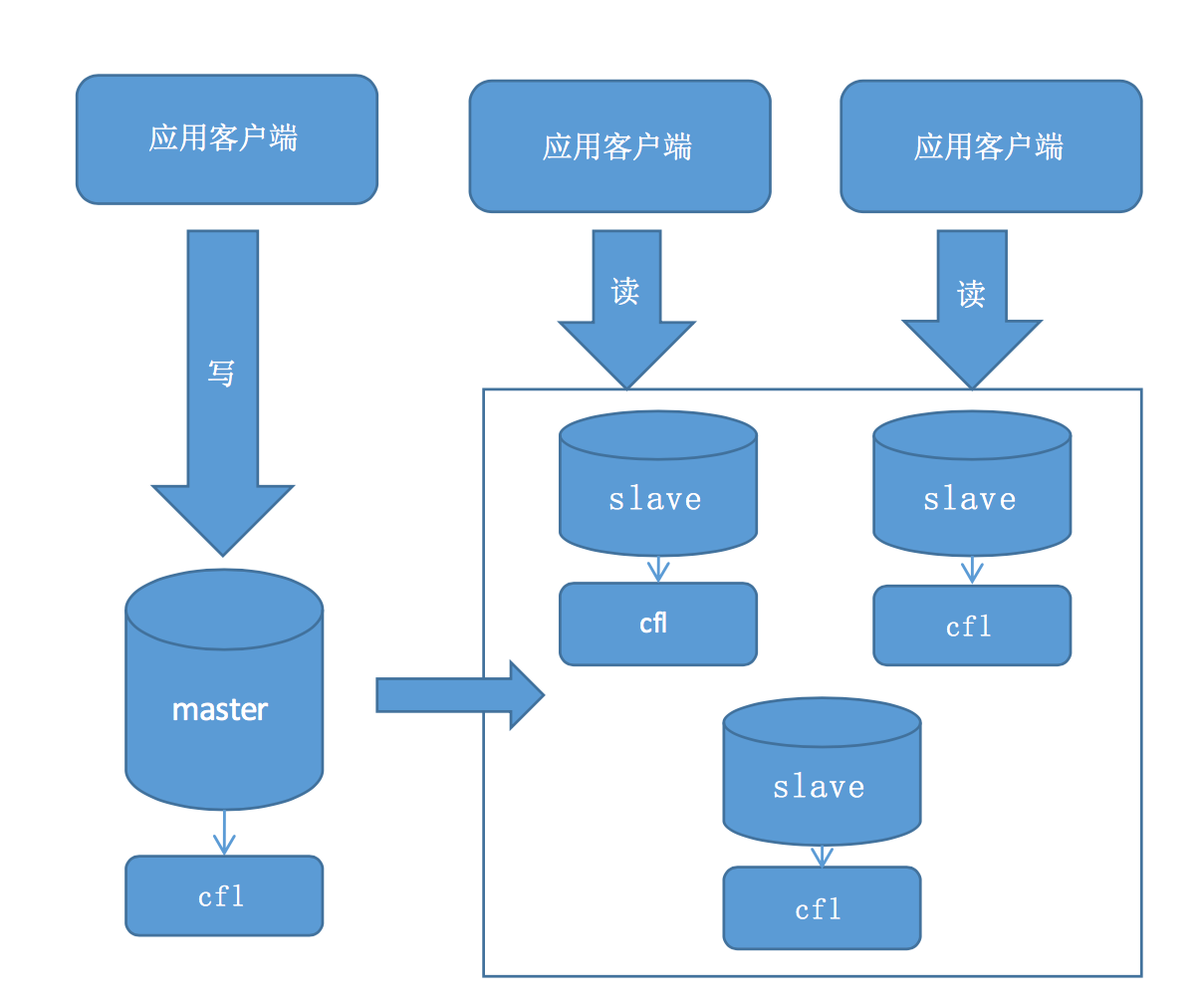
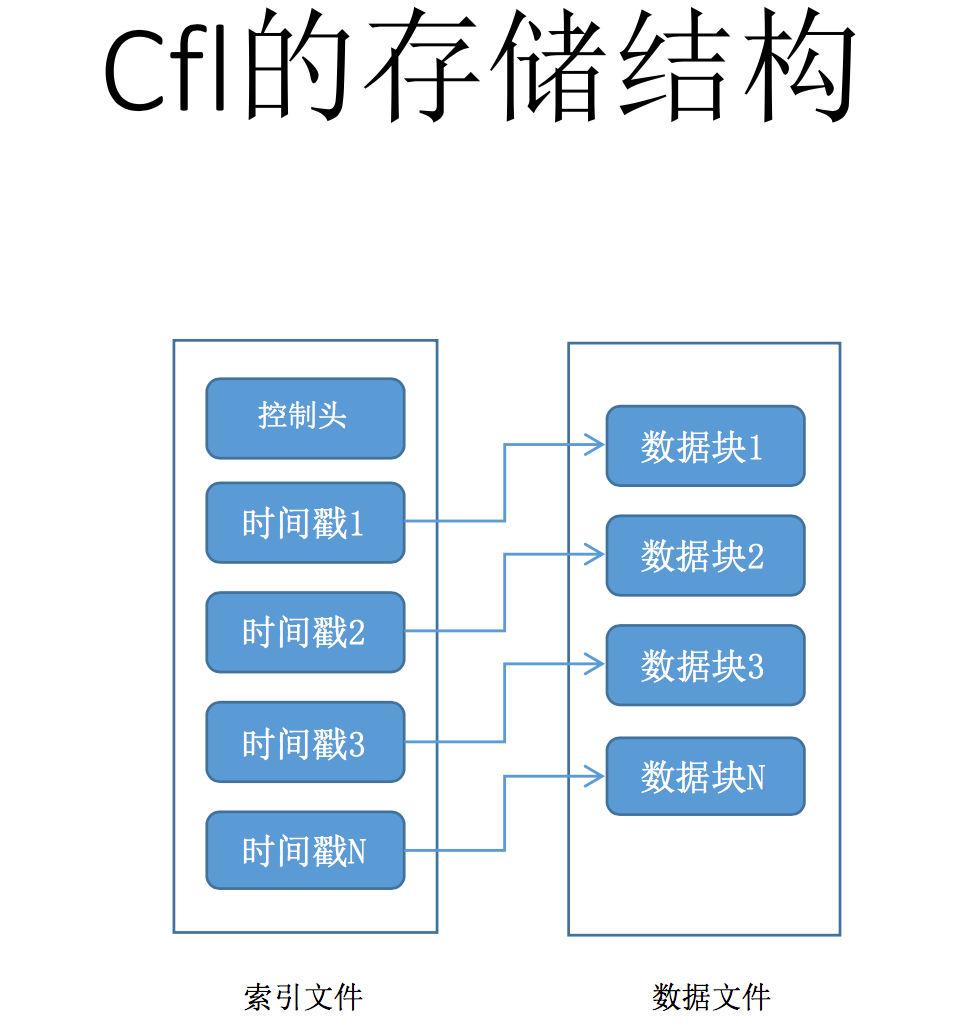
携程的同学做了一个MySQL时序数据库引擎(Ctrip fast logging),用于实时收集服务器的状态信息。时序数据的特点每条信息都包含了时间戳,并且是顺序追加的,而且这些信息一般不会发生变更,PPT的内容主要是讲如何基于Mysql的框架实现一个存储引擎,包括相关接口的实现。由于底层存储格式非常简单,只支持顺序插入,相对于innodb的B+树非常简单,因此效率也比较高。但个人感觉既然是收集服务器状态信息,性能不会成为瓶颈,用普通的innodb或者myisam足以满足需求,或者对于这种流水型作业用已有方案基于Hbase的OpenTSDB也能满足需求,我想做这个引擎的最大收益应该是积累引擎开发经验吧。
《揭开SQL优化的盖头来》
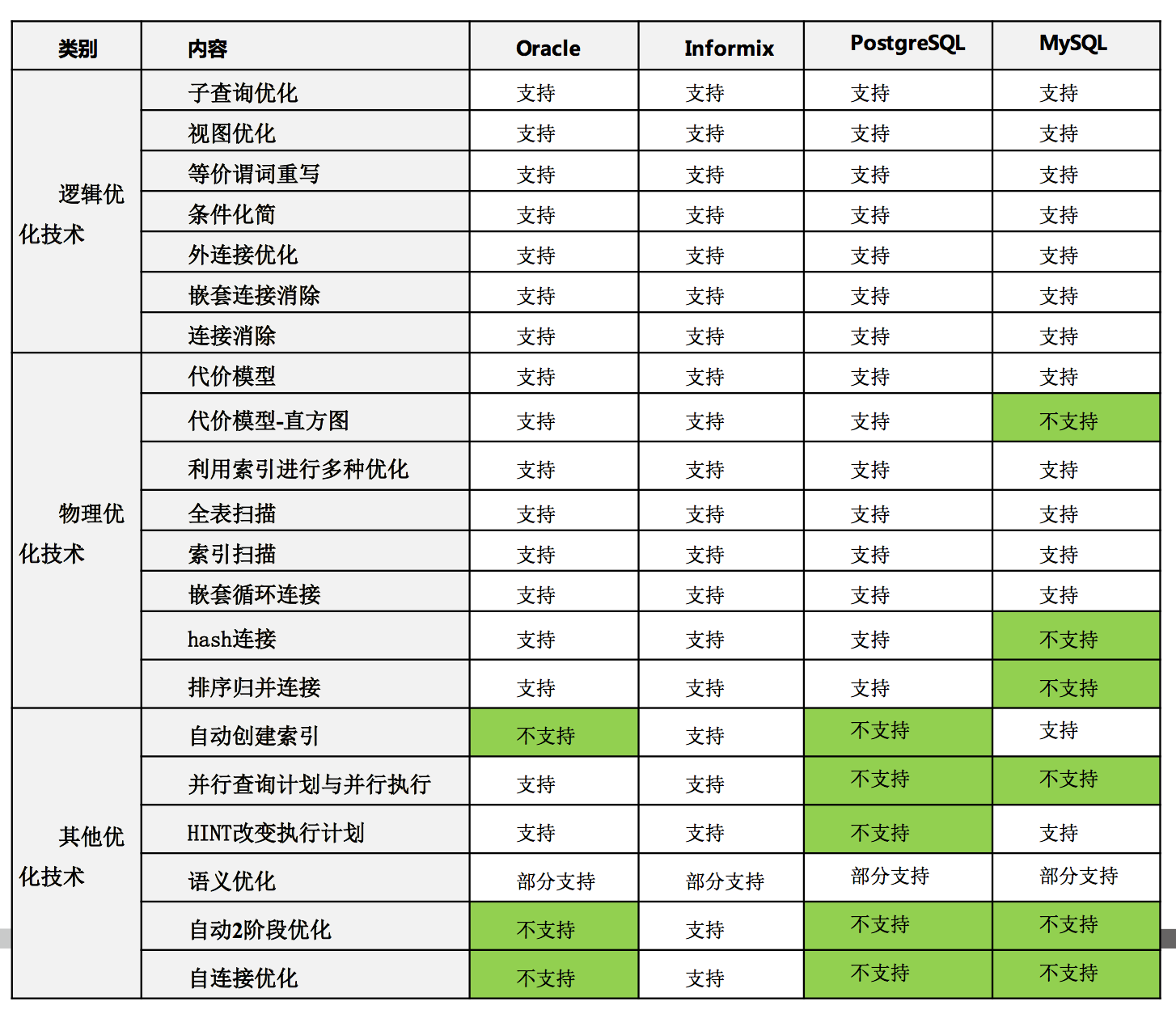
李海翔@那海蓝蓝老师从理论和实践上讲了一条SQL语句的编译和优化过程,并介绍了常用的优化技术,包括逻辑优化和物理优化。逻辑优化主要包括子查询上拉,等价谓词重写和外连接消除等;物理优化包括表连接时使用索引,利用索引扫描,group by利用索引,多表连接空间搜索等。最后介绍了各个常用数据库的优化器功能对比。总体来说,PPT的质量还是很不错的,对于DBA同学了解SQL执行原理非常有帮助。

《数据库事务处理原理与实例剖析》
华为的同学讲了事务的ACID的原理,并结合PostgreSQL介绍了MVCC机制,锁机制和故障恢复机制,基本上讲清楚了事务的原理和实现,比较偏理论,值得仔细体会。

《华泰证券数据库分布式架构》
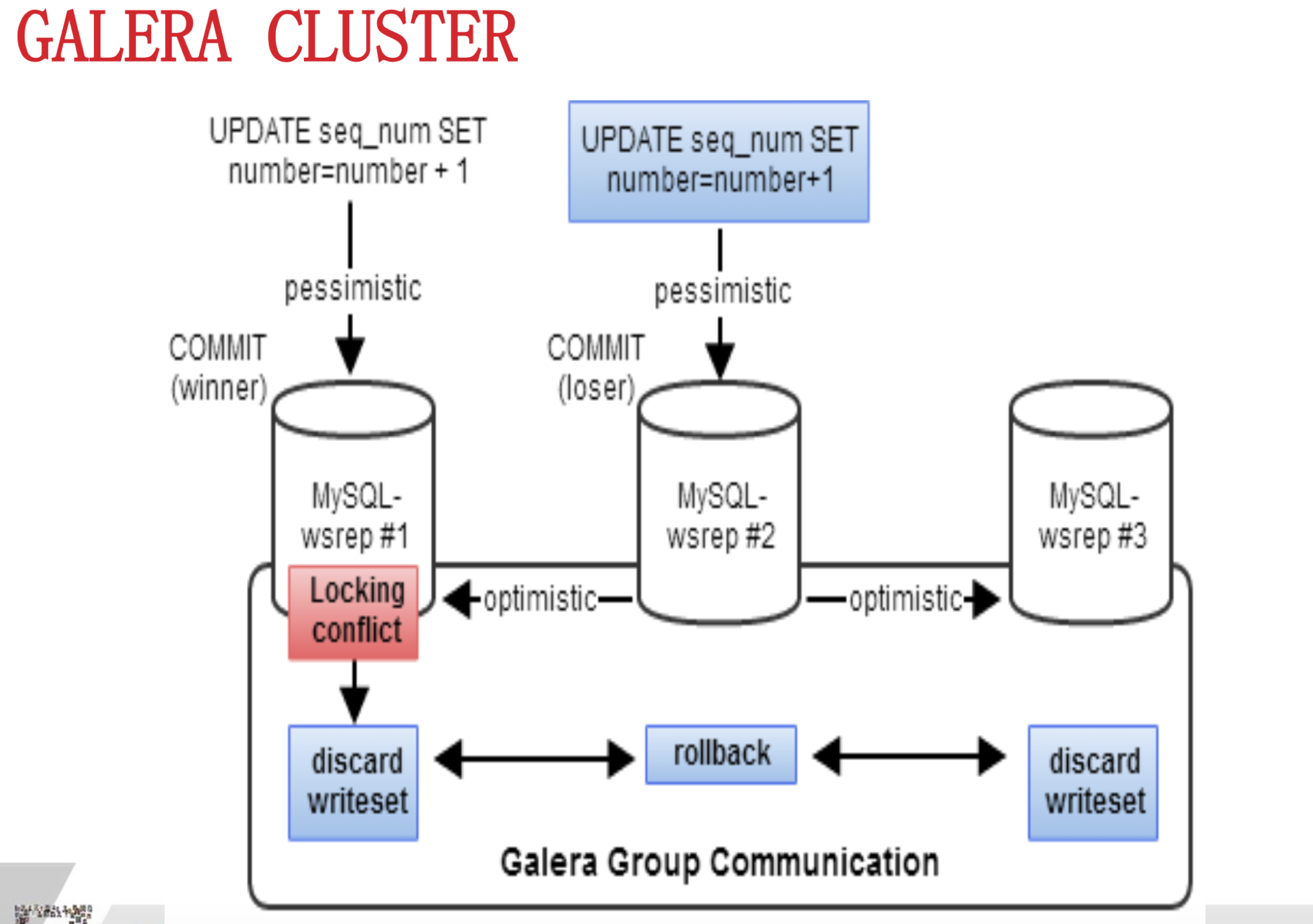
华泰的首席DBA讲了他们的Oralce迁移到MySQL后的高可用方案,通过引入中间件作为路由实现分库分表和读写分离,实现数据库集群水平扩展能力。此外,它们还引入了Galara Cluter集群技术,真正的强同步,数据完全不丢失,也就是PXC(Percona XtraDB Cluster)方案,据我了解,目前去哪儿公司也在用这种架构。这种架构强依赖于网络,所以他们的集群都是在一个机房的,对于我们同城的主备方案有参考意义,但是跨地域网络不稳定的场景下,感觉这种方案不太合适。
《RocksDB》
facebook工程师详细讲解了RocksDB的组织结构和存储原理,RocksDB是对LevelDB做了改进,目前作为MySQL的一个引擎(MyRocks)广泛应用于facebook生产环境中,并且MariaDB也支持引入了MyRocks引擎。RocksDB底层数据采用LSM(Log Structed Merge) Tree,相对于传统关系型数据库采用的以page为单位组织的B+树结构,更节省磁盘空间(B+树的page中存在空洞,空间利用率有限),控制写放大问题也更好(比如B+树中,更新一条记录,可能需要写入一个或多个Page)。RocksDB支持一次获取多个K-V,还支持Key范围查找,架构本身对数据自动做到冷热分离,此外RocksDB支持HDFS。个人感觉在省成本方面,RocksDB引擎是一个可以考虑的方向。MyRocks已经开源,git地址:https://github.com/MySQLOnRocksDB/mysql-5.6
《游戏云存储--TSpider分布式数据库》
腾讯的同学讲了他们的中间件方案,采用TSpider引擎的MySQL服务器作为代理,实现分库分表和读写分离的功能。TSpider是基于开源的引擎Spider定制,对性能和稳定性做了一定的优化。由于TSpider实际是Mysql的框架的一个引擎,因此它天然具备了Mysql处理复杂SQL的功能,这个是相对于其它中间件的一个优势。TSpider相当于中间服务层,自身不存业务数据,只存分区键信息和路由信息,TSpider对进行转发,并聚合查询结果。