|
*
|
name |
age
|
|
1
|
赵风
|
18
|
|
2
|
钱雨
|
20
|
|
3
|
孙雷
|
21
|
|
4
|
李电
|
18
|
|
5
|
李电
|
22
|
|
*
|
name
|
age
|
|
1
|
李电
|
18
|
|
2
|
钱雨
|
20
|
|
3
|
孙雷
|
21
|
|
4
|
赵风
|
18
|
|
5
|
李电
|
22
|
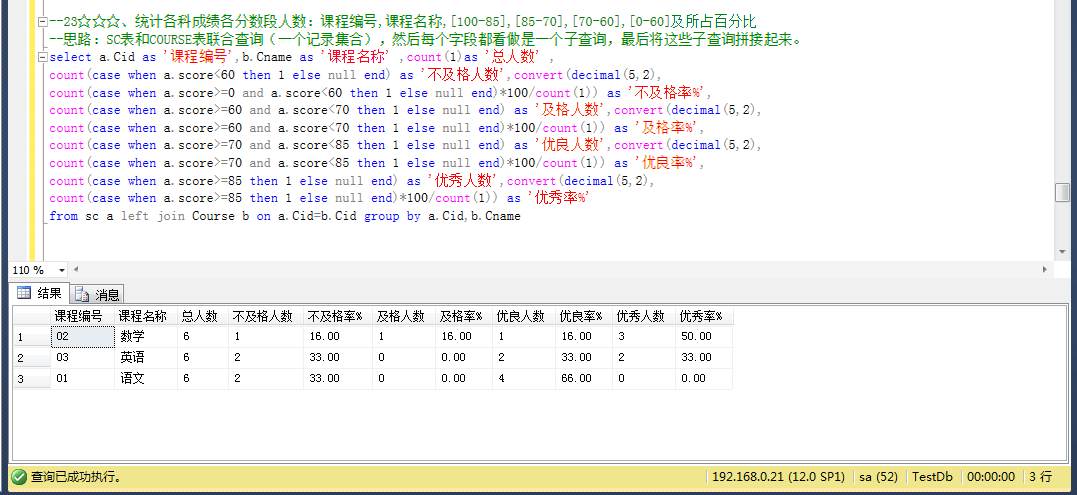
具体代码如下;


--23☆☆☆、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比 --思路:SC表和COURSE表联合查询(一个记录集合),然后每个字段都看做是一个子查询,最后将这些子查询拼接起来。 select a.Cid as '课程编号',b.Cname as '课程名称' ,count(1)as '总人数' , count(case when a.score<60 then 1 else null end) as '不及格人数',convert(decimal(5,2), count(case when a.score>=0 and a.score<60 then 1 else null end)*100/count(1)) as '不及格率%', count(case when a.score>=60 and a.score<70 then 1 else null end) as '及格人数',convert(decimal(5,2), count(case when a.score>=60 and a.score<70 then 1 else null end)*100/count(1)) as '及格率%', count(case when a.score>=70 and a.score<85 then 1 else null end) as '优良人数',convert(decimal(5,2), count(case when a.score>=70 and a.score<85 then 1 else null end)*100/count(1)) as '优良率%', count(case when a.score>=85 then 1 else null end) as '优秀人数',convert(decimal(5,2), count(case when a.score>=85 then 1 else null end)*100/count(1)) as '优秀率%' from sc a left join Course b on a.Cid=b.Cid group by a.Cid,b.Cname
(4)保留两位小数
代码如下所示:
CAST( count(case when a.score>0and a.score<60 then 1 else null end)*1.00/count(1)as decimal(18,2)) as '不及格率'
其中cast函数是转换数据类型的函数,cast((需要转换的数据)as 数据类型);
前面一定要乘于1.00,否则算出来的不及格率为0(让我想起了C#里面要保留两位小数就直接乘于1.00);
除号前后分别用cast转换得不到保留两位数,我也不知道什么原因 !!

(5)在写这些SQL语句时,我一直在避免使用 in,not in,null,not null这些关键字,但是,每次使用视图查询然后group by时,因为group by 的特性,都会发现排在第一个的是值为null的,如下图所示

而要将null这列去掉就得在后面加上having条件is not null ,因此很苦恼。
接下来可能要参与做一个winform的项目,所以来看看winform的一些比较重要的控键。。
(6)DataGridView控键的一些常见属性,附上网址:
https://www.cnblogs.com/jiangshuai52511/p/7843672.html
(7)创建临时表(表复制)
语法如下:
select * into 临时表名 from 原始表名
例:select * into #temporary from Student
往临时表添加数据
insert into #temporary(sNo,sName,sSex,sClass,id)values('s1111','林霖琳','女','19','1111')
这时候查询临时表#temporary的全部数据会发现增加一条数据,但是查询原始表Student的时候并没有增加一条数据,也就是说在临时表上做的任何操作都不会影响到原始表,之前以为既然并不会对数据库数据有任何改变,那么创建临时表的意义何在呢?通过问别人,知道了,创建临时表就是为了方便查询数据,在进行完一系列操作后,临时表会自动删除掉。
(8)单例模式
单例模式是确保一个类只有一个实例,并提供一个全局访问方式的设计方法
什么时候使用单例模式呢?
1.需要频繁实例化然后销毁的对象
2.创建对象时耗时过多或耗资源过多,但又经常用到的对象
3.频繁访问数据库或文件的对象
C#实现单例模式
1.单线程单例模式
private static Singleton _instance;
public static Singleton GetInstance()
{
if(_instance==null)
{
_instance=new Singleton();
}
return _instance;
}