本文将介绍如何使用虚拟机一步步从安装Ubuntu到搭建Hadoop伪分布式集群。
本文主要参考:在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境 - CSDN博客
一、所需的环境和软件:(以下是我们的环境,仅供参考)
1. 操作系统:Windows 10 64位
2. 内存:4G以上(4G 可以搭建,不过虚拟机的运行可能会比较慢,这种情况可以考虑双系统)
3. VMware Workstation 12:VMware-workstation-full-12.5.7-5813279.exe
4. VMware Tools:通过VMware来安装
5. Ubuntu12.04:ubuntu-14.04.5-desktop-amd64.iso,ubuntu-16.04.3-desktop-amd64.iso(团队中两种系统都有人成功,不过高版本的比较顺利)
6. SSH:通过linux命令来安装
7. JDK1.8:jdk-8u11-linux-x64.tar.gz
8. Hadoop2.6.0:hadoop-2.6.0.tar.gz
二、安装JDK
1、从我们的共享文件夹中把JDK拷到我们的用户目录下。

2、使用 sudo mkdir /usr/lib/jvm 命令来创建一个文件夹。sudo命令可能需要密码,通过sudo passwd root 命令改一下就好了
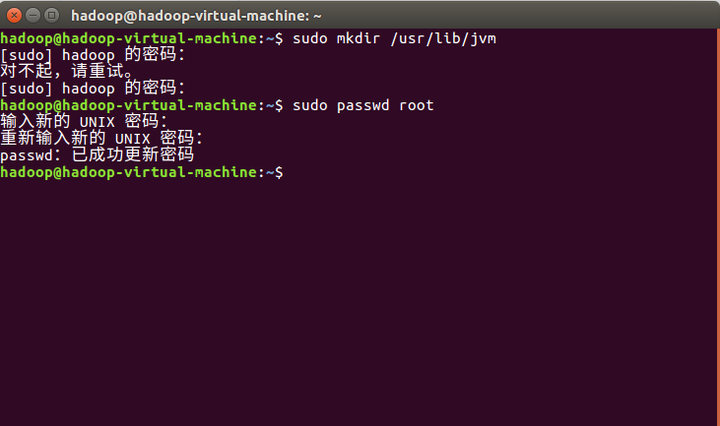
3、解压文件到该目录 sudo tar -zxvf jdk-8u11-linux-x64.tar.gz -C /usr/lib/jvm
上面是解压完毕后的界面。
4、修改环境变量
sudo gedit ~/.bashrc
在文档末尾添加下面的内容
#set oracle jdk environment
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_11 ## 这里要注意目录要换成自己解压的jdk 目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
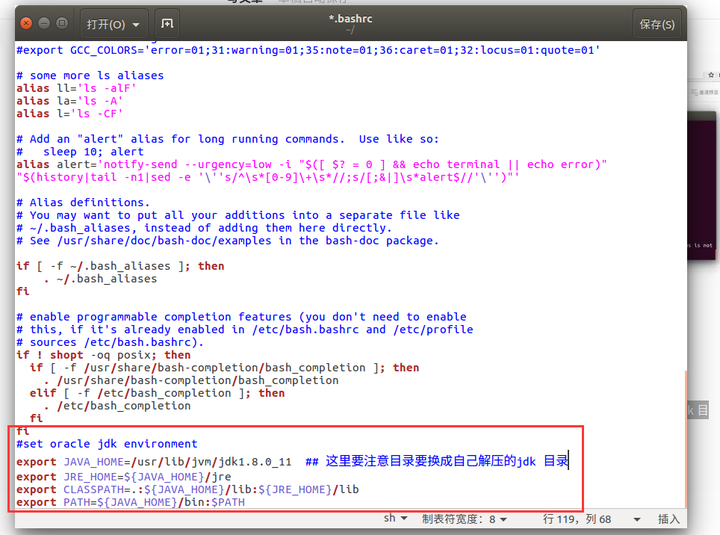
保存退出编辑。
5、输入如下命令使配置文件生效。
source ~/.bashrc
6、测试是否安装成功:
终端输入java和javac
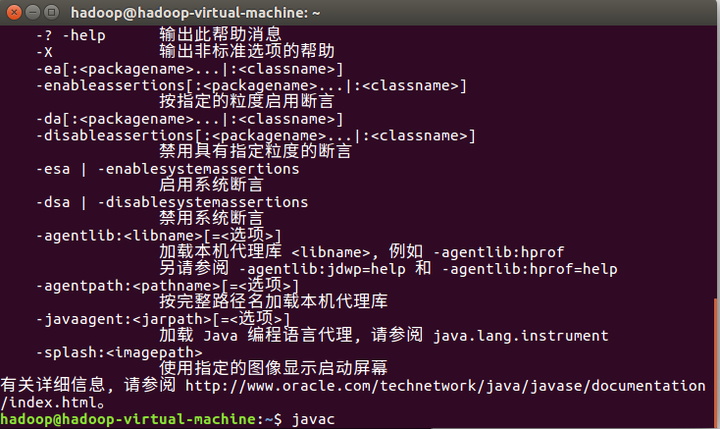
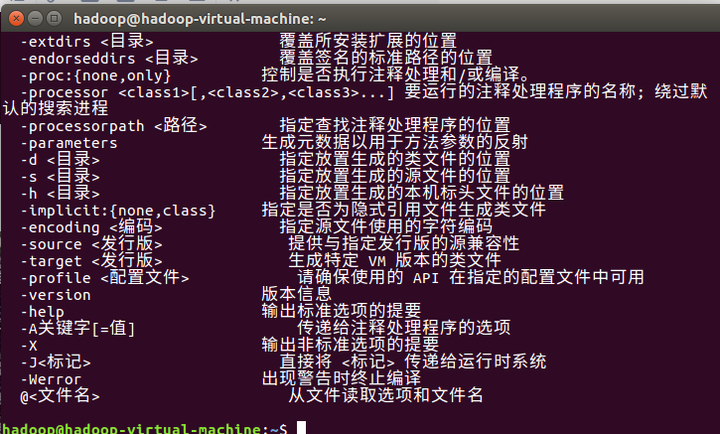
能够出现上面的界面就表明你的JDK 安装成功了。
备注:如果使用sudo gedit ~/.bashrc发现没有成功修改环境变量,还可以敲入指令:
sudo gedit /etc/profile
在 profile 文件最后回车键隔开一行,添加以下几行:
#####set java environment
export JAVA_HOME=/java/jvm/jdk_8u51
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
确认跟安装时的文件路径一直,保存关闭即可;
好以上挖坑的第二步已经搞定。