对redisson不熟悉的,请看官网或者github上面的
在Redisson框架中,实现了红锁的机制,Redisson的RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock对象关联为一个红锁,
每个RLock对象实例可以来自于不同的Redisson实例。当红锁中超过半数的RLock加锁成功后,才会认为加锁是成功的,这就提高了分布式锁的高可用。
我们可以使用Redisson框架来实现红锁。
public void testRedLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){ RLock lock1 = redisson1.getLock("lock1"); RLock lock2 = redisson2.getLock("lock2"); RLock lock3 = redisson3.getLock("lock3"); RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3); try { // 同时加锁:lock1 lock2 lock3, 红锁在大部分节点上加锁成功就算成功。 lock.lock(); // 尝试加锁,最多等待100秒,上锁以后10秒自动解锁 boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } }
其实,在实际场景中,红锁是很少使用的。这是因为使用了红锁后会影响高并发环境下的性能,使得程序的体验更差。所以,在实际场景中,我们一般都是要保证Redis集群的可靠性。同时,使用红锁后,当加锁成功的RLock个数不超过总数的一半时,会返回加锁失败,即使在业务层面任务加锁成功了,但是红锁也会返回加锁失败的结果。另外,使用红锁时,需要提供多套Redis的主从部署架构,同时,这多套Redis主从架构中的Master节点必须都是独立的,相互之间没有任何数据交互。
高并发“黑科技”与致胜奇招
假设,我们就是使用Redis来实现分布式锁,假设Redis的读写并发量在5万左右。我们的商城业务需要支持的并发量在100万左右。如果这100万的并发全部打入Redis中,Redis很可能就会挂掉,那么,我们如何解决这个问题呢?接下来,我们就一起来探讨这个问题。
在高并发的商城系统中,如果采用Redis缓存数据,则Redis缓存的并发处理能力是关键,因为很多的前缀操作都需要访问Redis。而异步削峰只是基本的操作,关键还是要保证Redis的并发处理能力。
解决这个问题的关键思想就是:分而治之,将商品库存分开放。
暗度陈仓
我们在Redis中存储商品的库存数量时,可以将商品的库存进行“分割”存储来提升Redis的读写并发量。
例如,原来的商品的id为10001,库存为1000件,在Redis中的存储为(10001, 1000),我们将原有的库存分割为5份,则每份的库存为200件,此时,我们在Redia中存储的信息为(10001_0, 200),(10001_1, 200),(10001_2, 200),(10001_3, 200),(10001_4, 200)。
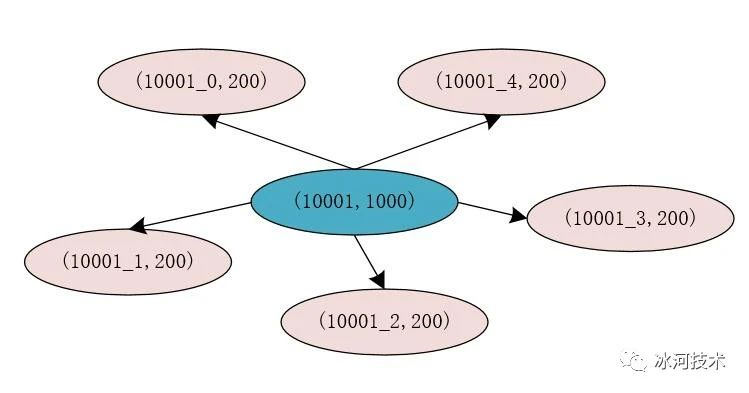
此时,我们将库存进行分割后,每个分割后的库存使用商品id加上一个数字标识来存储,这样,在对存储商品库存的每个Key进行Hash运算时,得出的Hash结果是不同的,这就说明,存储商品库存的Key有很大概率不在Redis的同一个槽位中,这就能够提升Redis处理请求的性能和并发量。
分割库存后,我们还需要在Redis中存储一份商品id和分割库存后的Key的映射关系,此时映射关系的Key为商品的id,也就是10001,Value为分割库存后存储库存信息的Key,也就是10001_0,10001_1,10001_2,10001_3,10001_4。在Redis中我们可以使用List来存储这些值。
在真正处理库存信息时,我们可以先从Redis中查询出商品对应的分割库存后的所有Key,同时使用AtomicLong来记录当前的请求数量,使用请求数量对从Redia中查询出的商品对应的分割库存后的所有Key的长度进行求模运算,得出的结果为0,1,2,3,4。再在前面拼接上商品id就可以得出真正的库存缓存的Key。此时,就可以根据这个Key直接到Redis中获取相应的库存信息。
同时,我们可以将分隔的不同的库存数据分别存储到不同的Redis服务器中,进一步提升Redis的并发量。
移花接木
在高并发业务场景中,我们可以直接使用Lua脚本库(OpenResty)从负载均衡层直接访问缓存。
这里,我们思考一个场景:如果在高并发业务场景中,商品被瞬间抢购一空。此时,用户再发起请求时,如果系统由负载均衡层请求应用层的各个服务,再由应用层的各个服务访问缓存和数据库,其实,本质上已经没有任何意义了,因为商品已经卖完了,再通过系统的应用层进行层层校验已经没有太多意义了!!而应用层的并发访问量是以百为单位的,这又在一定程度上会降低系统的并发度。
为了解决这个问题,此时,我们可以在系统的负载均衡层取出用户发送请求时携带的用户id,商品id和活动id等信息,直接通过Lua脚本等技术来访问缓存中的库存信息。如果商品的库存小于或者等于0,则直接返回用户商品已售完的提示信息,而不用再经过应用层的层层校验了。