本次学习来自李宏毅老师的机器学习视频
首先梯度下降法:

这时候要小心调你的学习率:

做梯度下降的时候你应该把上方的图画出来,知道曲线的走势,才好调学习率。
但调学习率很麻烦,有没有一些自动的办法来帮助我们调学习率呢?
最基本的原则是随着参数的更新让学习率变得越来越小。为什么会这样呢?因为当你在开始的时候,它通常是离最低谷是比较远的,所以这时你的步伐要大一点。
但是经过好几次参数的更新后,你已经比较靠近你的目标了,所以这时候你应该减少你的学习率,让他能够收敛在你最低点的地方。
举例来说,你学习率的设置方法可能这样:
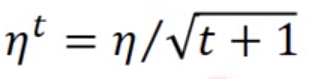
但是光这样是不够的,你需要因材施教,因为有不同的参数需要更新,最好的状况应该是每一个不同的参数,都给他不同的学习率。这件事情是有很多小技巧的,我觉得最简单,最容易操作的叫做Adagrad
1.Adagrad
即每一个不同的参数都把他除以之前算出来的微分值的均方根,原来的梯度下降算法如下所示:

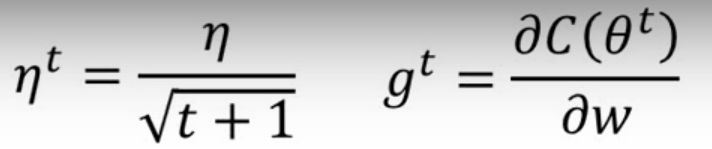
现在Adagrad:

这样的话,学习率对每个参数来说都是不一样的。具体来说:


2. Stochastic梯度下降
它可以让你的训练更快一点。它并不是算所有样本的loss值,然后在进行梯度下井,但在这个算法里面,你挑出一个样本的loss,就只算出一个样本的loss,然后就更新一下参数这样。
