os.walk(top, topdown = True, onerror = None, followlinks = False)
文件结构
Test folder:
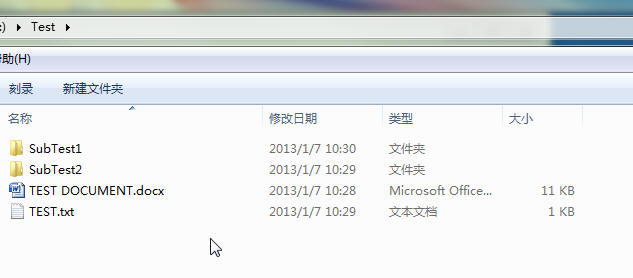
SubTest1 folder:

ThirdLayer folder:

SubTest2 folder:

示例代码1: import os path = 'D:Test' for root, dirs, files in os.walk(path): print("Root = ", root, "dirs = ", dirs, "files = ", files)
结果: Root = D:Test dirs = ['SubTest1', 'SubTest2'] files = ['TEST DOCUMENT.docx', 'TEST.txt'] Root = D:TestSubTest1 dirs = ['ThirdLayer'] files = ['TEST DOCUMENT1.docx', 'TEST1.txt'] Root = D:TestSubTest1ThirdLayer dirs = [] files = ['TEST DOCUMENT L3.docx', 'TEST L3.txt'] Root = D:TestSubTest2 dirs = [] files = ['TEST DOCUMENT2.docx', 'TEST2.txt']
结果分析
1,先从根目录进行遍历,读取跟目录的文件夹和文件。
2,以根目录第一个子目录为新的根目录,读取其文件夹和文件。
3,再以2中的第一个子文件夹为根目录,读取文件夹和文件。(这个应该是属于树结构里面的自上而下深度遍历算法)
4,读取1步骤里面其他子目录的文件夹和文件。
示例代码2:(修改topdown 为False) import os path = 'D:Test' for root, dirs, files in os.walk(path, False): print("Root = ", root, "dirs = ", dirs, "files = ", files)
返回结果 Root = D:TestSubTest1ThirdLayer dirs = [] files = ['TEST DOCUMENT L3.docx', 'TEST L3.txt'] Root = D:TestSubTest1 dirs = ['ThirdLayer'] files = ['TEST DOCUMENT1.docx', 'TEST1.txt'] Root = D:TestSubTest2 dirs = [] files = ['TEST DOCUMENT2.docx', 'TEST2.txt'] Root = D:Test dirs = ['SubTest1', 'SubTest2'] files = ['TEST DOCUMENT.docx', 'TEST.txt']
结果分析:
其实结果实质是一样的,不同的是,这次使用的是自下而上的深度遍历算法。
其他说明:
- 文件的全路径: 从上面的结果可以看出,文件的全路径,应该是os.path.join(root, files)
- 如果你要数路径下有多少个文件夹,其实很简单就是所有的root数目-1,因为root数目包含path文件夹。
- 如果以文件作为path路径会怎样? 返回空。
import os path = 'D:Test1' for root, dirs, files in os.walk(path, False): print("Root = ", root, "dirs = ", dirs, "files = ", files)
- 如果以一个不存在的文件夹为路径作为path会怎样?这里假定如果onerror = None,返回为空。
import os path = 'D:TestTEST.txt' for root, dirs, files in os.walk(path, False): print("Root = ", root, "dirs = ", dirs, "files = ", files)