A Closer Look at Spatiotemporal Convolutions for Action Recognition
研究机构:facebook的论文
主要思想与创新:实验上论证R(2+1)D比C3D会更好,相同的参数,卷积效果更好
1针对视频任务(可以看做是有关联信息的3D图像),单用2D卷积网络不能捕捉时间上的推理信息(图1(a)),采用3D卷积网络还是能达到比较好的效果,毕竟卷积了前后几个slice的信息(图1(d)),但是3D网络不可避免会多了很多参数,有计算冗余的缺点。
2在性能和模型大小的权衡之下,论文提出第一版改进模型:2D+3D,称之为混合卷积(MC,mixed convolution),一共有两种模式(图1(b)(c)),这样做的好处:减少参数,保持性能。论文给出了数据,相对于2D网络参数增加了3-4%,相对于3D网络参数为三分之一,但可以达到接近3D卷积网络的效果。
3在2的基础上,论文又提出了升级版(图1(e)),(2+1)D,将3D的卷积拆分成两个既分开又连续的操作,所谓分开是指分两步进行提取信息(图2),第一步采用2D卷积提取的是空间上的信息,第二步采用1D卷积将上一步提取的空间上的信息给关联起来。所谓连续是指先空间卷积再时间卷积,以此结构实现对于时空信息提取更好的非线性操作,增加模型的复杂度,可能会拟合得更加贴切。另外还有个好处就是,这样相比3D卷积参数少,而且更加容易优化,收敛效果更好。
————————————————
版权声明:本文为CSDN博主「Wa_o_Fi」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010142666/article/details/81009550
结果和优点
top1:71~% recognition accuracy
在底层对时间运动信息编码的效果要好于在顶层对时间运动信息编码
知识点
- 几个网络模型图

- 对R(2+1)D的解释

- 结果对比

自己的思考
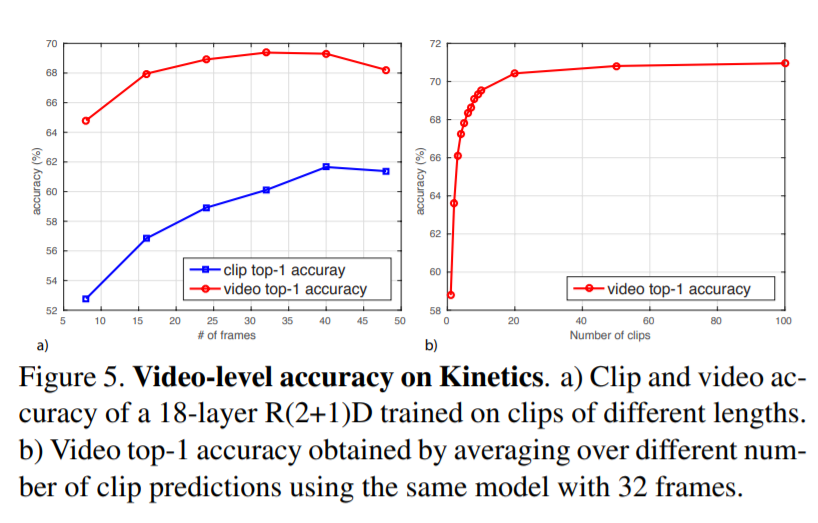
这个R(2+1)D的卷积,需要32帧的图片输入,感觉计算量还是很大的,不会是一个小数。
参考博客
- 【论文阅读】A Closer Look at Spatiotemporal Convolutions for Action Recognition
- PaperReading3-A Closer Look at Spatiotemporal Convolutions for Action Recognition
- https://www.cnblogs.com/hizhaolei/p/10186050.html
- http://jacobkong.github.io/blog/3309988052/
代码和数据
代码:https://github.com/MRzzm/action-recognition-models-pytorch
数据:http://r
read_date:20191129