前言
Structured Streaming 消费 Kafka 时并不会将 Offset 提交到 Kafka 集群,本文介绍利用 StreamingQueryListener 间接实现对 Kafka 消费进度的监控。
基于StreamingQueryListener向Kafka提交Offset
监听StreamingQuery各种事件的接口,如下:
public abstract class StreamingQueryListener {
public abstract void onQueryStarted(StreamingQueryListener.QueryStartedEvent var1); public abstract void onQueryProgress(StreamingQueryListener.QueryProgressEvent var1); public abstract void onQueryTerminated(StreamingQueryListener.QueryTerminatedEvent var1);
}
在QueryProgressEvent中,我们是可以拿到每个Source消费的Offset的。因此,基于StreamingQueryListener,可以将消费的offset的提交到kafka集群,进而实现对Kafka Lag的监控。
KafkaOffsetCommiter
package com.trace.spark; import com.alibaba.fastjson.JSONObject; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.common.TopicPartition; import org.apache.spark.sql.streaming.SourceProgress; import org.apache.spark.sql.streaming.StreamingQueryListener; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.HashMap; import java.util.Map; import java.util.Properties; public class CustomStreamingQueryListener extends StreamingQueryListener { /** * logger. */ private static final Logger logger = LoggerFactory.getLogger(CustomStreamingQueryListener.class); /** * 初始化KafkaConsumer. */ private static KafkaConsumer kafkaConsumer = null; Properties properties= new Properties(); { properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "sparkStructuredStreaming"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); kafkaConsumer = new KafkaConsumer(properties); } @Override public void onQueryStarted(QueryStartedEvent event) { logger.info("Started query with id : {}, name: {},runId : {}", event.id(), event.name(), event.runId().toString()); } @Override public void onQueryProgress(QueryProgressEvent event) { logger.info("Streaming query made progress: {}", event.progress().prettyJson()); for (SourceProgress sourceProgress : event.progress().sources()) { Map<String, Map<String, String>> endOffsetMap = JSONObject.parseObject(sourceProgress.endOffset(), Map.class); for (String topic : endOffsetMap.keySet()) { Map<TopicPartition, OffsetAndMetadata> topicPartitionsOffset = new HashMap<>(); Map<String, String> partitionMap = endOffsetMap.get(topic); for (String partition : partitionMap.keySet()) { TopicPartition topicPartition = new TopicPartition(topic, Integer.parseInt(partition)); OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(Long.parseLong(String.valueOf(partitionMap.get(partition)))); topicPartitionsOffset.put(topicPartition, offsetAndMetadata); } logger.info("【commitSync offset】topicPartitionsOffset={}", topicPartitionsOffset); kafkaConsumer.commitSync(topicPartitionsOffset); } } } @Override public void onQueryTerminated(QueryTerminatedEvent event) { logger.info("Stream exited due to exception : {}, id : {}, runId: {}", event.exception().toString(), event.id(), event.runId()); } }
Structured Streaming App
package com.trace.spark; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Encoders; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.functions; import org.apache.spark.sql.streaming.StreamingQuery; import org.springframework.util.StringUtils; import com.alibaba.fastjson.JSONObject; import com.google.common.collect.Lists; import com.trace.spark.function.CleanDataFunction; import com.trace.spark.function.HbaseForeachWriter; import com.trace.spark.function.HbaseHelper; import com.trace.util.KafkaOpsUtils; import com.trace.util.TraceUtils; import scala.Tuple3; public class SparkKafkaManager { private static final Logger logger = LoggerFactory.getLogger(SparkKafkaManager.class); public static AtomicLong atomic = new AtomicLong(1); public static void main(String[] args) throws Exception { String brokers = "172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092"; final SparkSession spark = SparkSession.builder().appName("TimeWindow").getOrCreate(); spark.udf().register("cleanData", new CleanDataFunction()); spark.streams().addListener(new CustomStreamingQueryListener()); Dataset<Row> lines = spark .readStream() .format("kafka") .option("subscribe", KafkaOpsUtils.trace_topic_name) .option("kafka.bootstrap.servers", brokers) .load();
省略后续代码...................
查看Kafka Offset
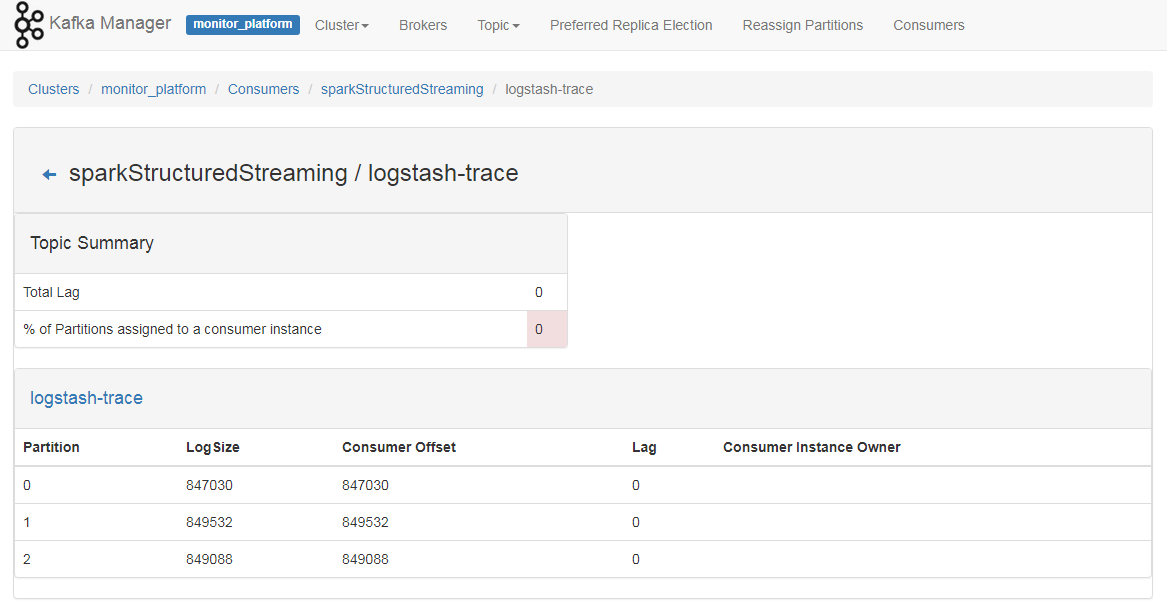
其它
还有以下两种方式也可以实现监控效果:
CheckpointStreamingQueryAPI
引用: