前言:
最近在使用elasticSearch中发现有些数据查不出来,于是研究了一下,发现是分词导致的,现梳理并总结一下。
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
ElasticSearch字符串将默认被同时映射成text和keyword类型,将会自动创建下面的动态映射(dynamic mappings):
"relateId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
这就是造成部分字段还会自动生成一个与之对应的“.keyword”字段的原因。
存储查询示例:
relateId存储:20191101R672499460503 1个值
relateId.keyword存储:20191101 R 672499460503 3个值
这时用relateId进行精确查询,查不出数据,因为已经被分成3个词了:
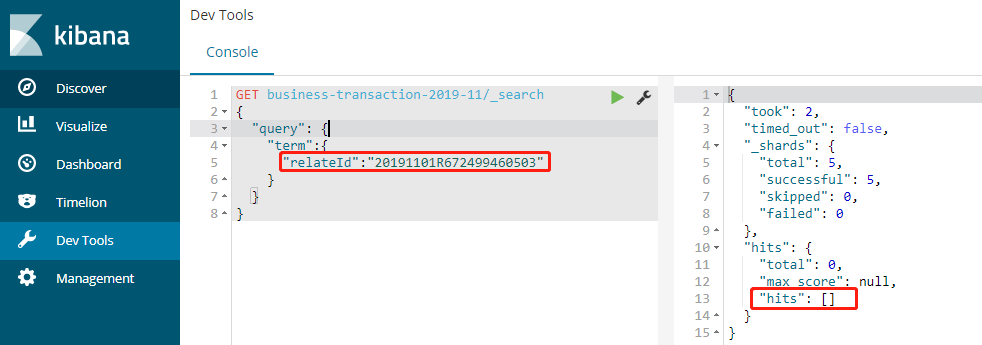
用relateId.keyword进行精确查询则可以查出数据来:
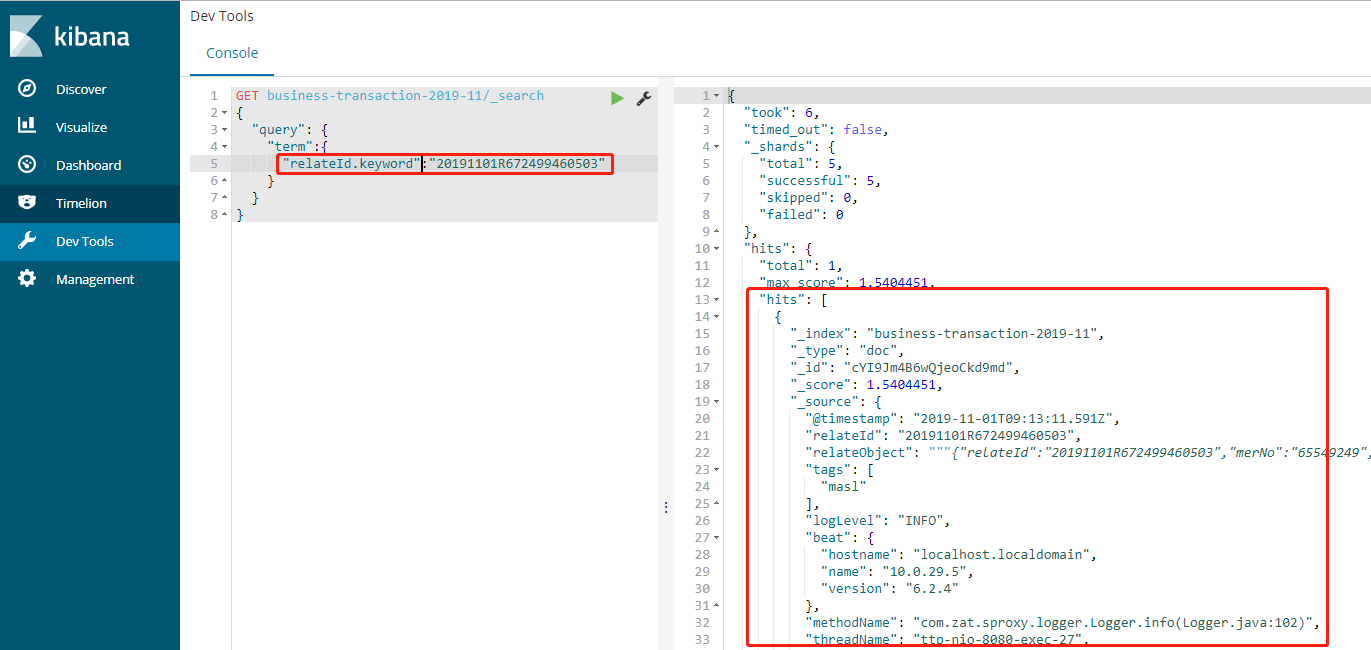
两者比较:
Text:默认会分词,然后进行索引,支持模糊、精确查询,不支持聚合
keyword:不进行分词,直接索引,支持模糊、精确查询,支持聚合
进阶处理:
注意:Text默认会分词,这是很智能的,但在有些字段里面是没用的,所以对于有些字段使用text则浪费了空间。这时可以设置mapping为not analyzied,让它不分词。
"relateId": { "type": "text", "index": "not_analyzed" }
如果要指定分词则用下面的方式:
"relateId": { "type": "text", "analyzer": "ik_max_word", "search_analyzer":"ik_smart", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }