废话不多说,直接上代码:
package com.sysker.util;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Date;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.Test;
public class getVideoUrls {
private void getHtmlSources() {
BufferedWriter writerPage = null;
Document doc = null;
try {
writerPage = new BufferedWriter(new FileWriter("ygdy8-"+ System.currentTimeMillis() + ".html"));
doc = Jsoup.connect(
"http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html").get();
Element list = doc.getElementsByClass("co_content8").first();
Elements bs = list.getElementsByTag("b");
String lastPage = list.getElementsByTag("div").first()
.getElementsByTag("a").last().attr("href");
int page = Integer.parseInt(lastPage.substring(
lastPage.length() - 8, lastPage.length() - 5));
writerPage.write("<html><head><title>电影天堂最新电影</title></head><h1>电影天堂最新电影</h1><body>");
writerPage.write("<p>日期:" + new Date() + "</p><br/>");
System.out.println(page);
for (int i = 0; i < 17; i++) {
doc = Jsoup.connect(
"http://www.ygdy8.net/html/gndy/dyzz/list_23_" + (i+1) + ".html").get();
list = doc.getElementsByClass("co_content8").first();
bs = list.getElementsByTag("b");
System.out.println("===============第" + (i + 1)
+ "页================");
for (Element element : bs) {
String url = element.getElementsByTag("a").first()
.attr("abs:href");
writerPage.write("<li><a href="+ """ + getDownloadUrls(url) + """ + ">" +element.text() +"</a></li><br/>
");
writerPage.flush();
}
}
writerPage.write("</body></html>");
writerPage.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writerPage != null) {
writerPage.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
private String getDownloadUrls(String url) throws IOException {
Document doc = Jsoup.connect(url).get();
Element span = doc.getElementById("Zoom").getElementsByTag("span")
.first();
String downloadUrl = span.getElementsByTag("table").last()
.getElementsByTag("a").first().attr("href");
return downloadUrl;
}
@Test
public void testName() throws Exception {
long startTime = System.currentTimeMillis();
getHtmlSources();
long endTime = System.currentTimeMillis();
long useTime = (endTime - startTime) / 1000;
System.out.println("耗时" + useTime + "s");
}
}
-
用到的包:

-
生成页面效果:
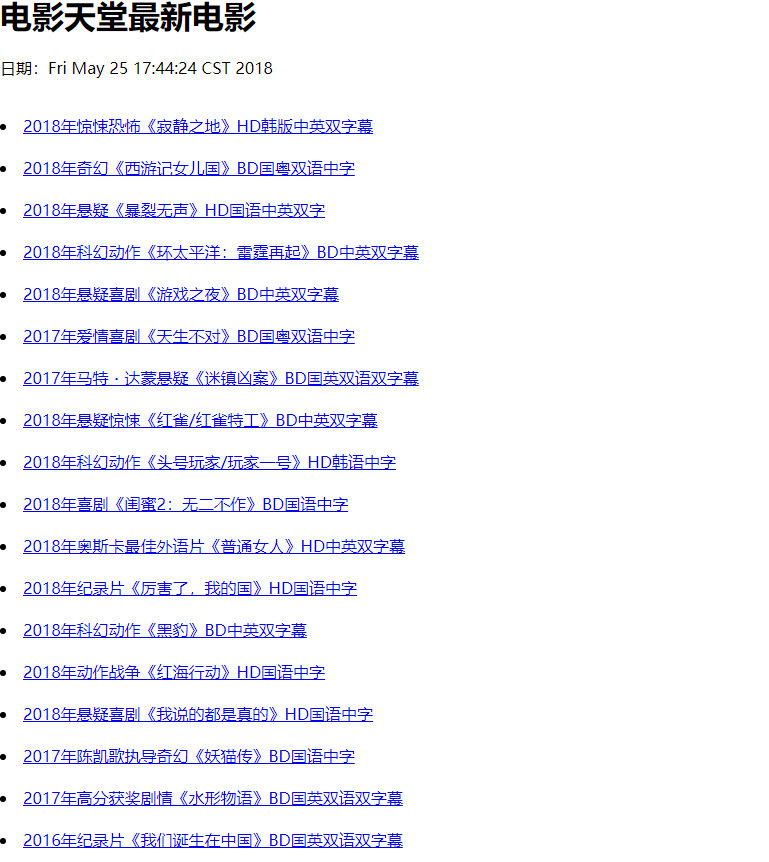
-
- 右键复制链接可以直接复制至百度云或迅雷下载
-
说明:由于页面结构的问题,目前仅支持抓取前17页;
-
声明:本教程仅供交流学习参考,切勿用于其他用途!