hashmap存储结构
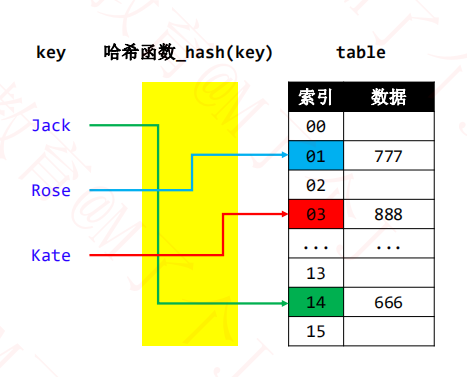
1、通过对key进行hash函数运算,得到索引,此时的索引与哈希值不一样

2、哈希值一样,索引一定一样,key不一样一样。哈希值不一样,索引可能一样
自定义对象的key,为什么要实现hashcode与equals
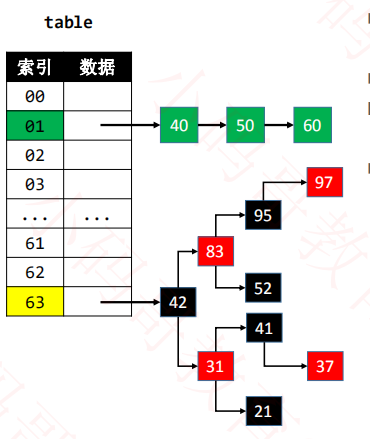
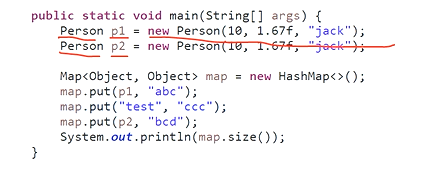
1、只实现hashcode
只实现hashcode的话,它们的索引可以得到判定是否一样,但是由于没有实现equal,导致它们的自定义对象key判定不了,判定不了就会采用object中的equal判定。如果它们的key不一样,就会采用链地址法存储key,如果是一样就会覆盖。这样结果就会出现随机,map.size()结果也会随机。但是我们大部分自定义key对象,都需要根据业务要判断key是否是一样,所以同时要实现equal
2、只实现equal
可能会导致的结果是,索引不一样,索引也可能一样,那map.size()数量就是随机的,比如上面的例子,p1与p2通过内存地址生成hashcode,计算出来的hashcode可以导致索引一样,也可能导致索引不一样,如果索引一样,那么p1与p2对象就存储在同一个索引地方,然后hashmap还会继续比较自定义对象的key,用equal,如果equal一样,就会p2覆盖p1的key,则上面的例子map.size()是等于2。否则就会采用链地址法,则上面的例子map.size()是等于3
3、总结
自定义对象的key,首先通过 :person自定义对象 =====》哈希函数 =====》得到索引======》进行key的equal比较,如果索引与equal相同,则覆盖,如果不同,则链地址法。所以说,一般都会根据自己的业务,同时实现了hashcode与equal,这样Map<object,object>就会根据自己的业务进行存储。