前言
在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到。这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法
什么事xpath呢?
百度结果:XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
通俗一点讲就是通过元素的路径来查找到这个元素的。
一、xpath:属性定位
1.xpath也可以通过元素的id、name、class这些属性定位,如下图
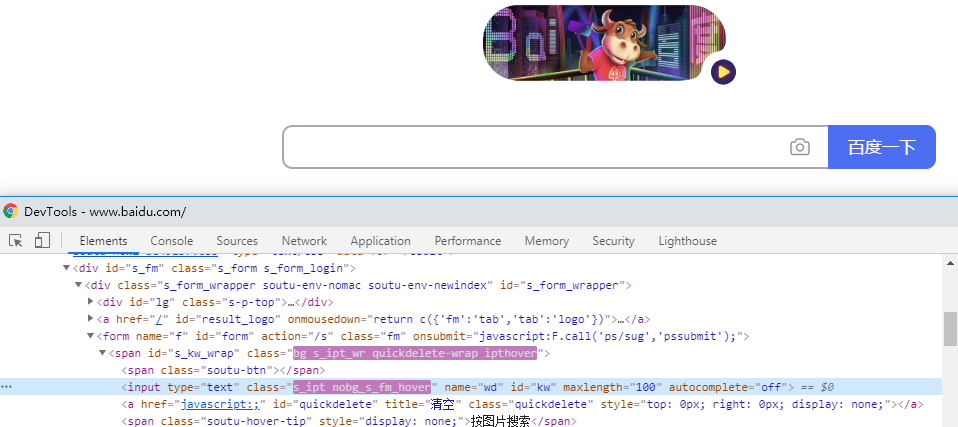
2.于是可以用以下xpath方法定位
# coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
#用xpath通过id属性定位
# driver.find_element_by_xpath("//*[@id='kw']").send_keys("xi")
#用xpath通过name属性定位
# driver.find_element_by_xpath("//*[@name='wd']").send_keys('xi')
#用xpath通过class属性定位
driver.find_element_by_xpath("//*[@class='s_ipt']").send_keys("xi")
二、xpath:其它属性
1.如果一个元素id、name、class属性都没有,这时候也开业通过其它属性定位到
# coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
#用xpath通过其它属性定位
driver.find_element_by_xpath("//*[@autocomplete='off']").send_keys("ha")
三、xpath:标签
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
2.如果不想指定标签名称,可以用*号表示任意标签
3.如果想指定具体某个标签,就可以直接写标签名称
# coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
#用xpath通过其它属性定位
# driver.find_element_by_xpath("//*[@autocomplete='off']").send_keys("ha")
# driver.find_element_by_xpath("//input[@autocomplete='off']").send_keys("ha")
driver.find_element_by_xpath("//input[@id='kw']").send_keys("ha")
四、xpath:层级
1.如果一个元素,他的属性不是很明显,无法直接定位到,这时候我们可以先找他老爸(父元素)
2.找到它老爸后,再找下一个层级就能定位到了
这里的父元素查找报错了,why? 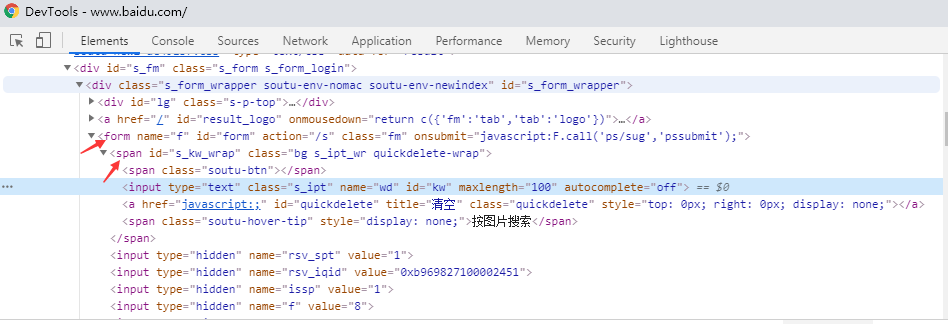
3.如上图所示,要定位的是input这个标签,他的老爸的id=s_kw_wrap
4.要是它老爸的属性也不是很明显,就找它爷爷id=form
5.于是就可以通过层级关系定位到
# coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
#通过定位它老爸来定位input输入框,报错: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//span[@id='s_kw_wrap']/input"},不明白是为什么
# driver.find_element_by_xpath("//span[@id='s_kw_wrap']/input").send_keys("xi")
#通过定位它爷爷来定位input输入框
driver.find_element_by_xpath("//form[@id='form']/span/input").send_keys("ha")
五、xpath:索引
1.如果一个元素它的兄弟元素跟它的标签一样,这时候就无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图多胞胎兄弟
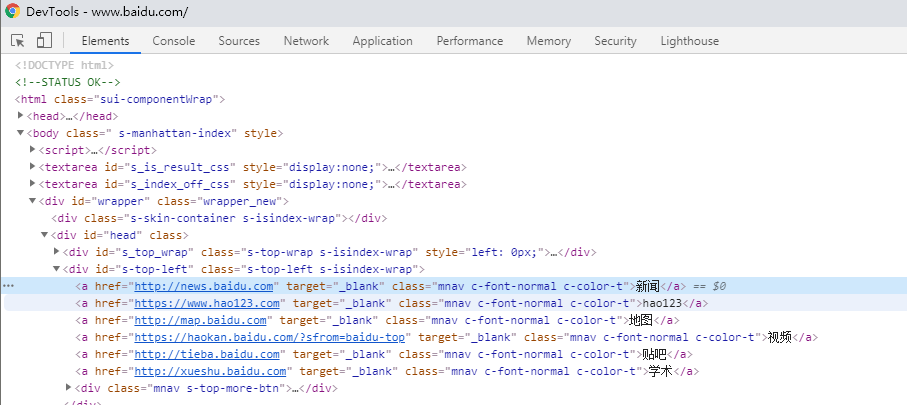
4.用xpath定位老大和老三(这里的索引是从1开始算起的,跟python的索引不一样)
# coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
#driver.find_element_by_xpath("//div[@id='s-top-left']/a[1]").click()
driver.find_element_by_xpath("//div[@id='s-top-left']/a[3]").click()
六、xpath:逻辑运算
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性。
# coding:utf-8
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_xpath("//*[@id='kw' and @name='wd']").send_keys("xixi")
七、xpath:模糊匹配
1.xpath还有一个非常强大的功能,模糊匹配
2.掌握了模糊匹配功能,基本上没有定位不到的
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link_text,也可以通过by_partial_link_text,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。
# coding:utf-8
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#xpath模糊匹配功能
driver.find_element_by_xpath("//*[contains(text(),'hao123')]").click()
#xpath也可以模糊匹配某个属性
# driver.find_element_by_xpath("//*[contains(@id,'kw')]").send_keys("hehe")
#xpath可以模糊匹配以什么开头
# driver.find_element_by_xpath("//*[starts-with(@id,'s-usersettin')]").click()
#xpath可以模糊匹配以什么结尾,百度——设置,一直报错;is not a valid XPath expression.
# driver.find_element_by_xpath("//*[ends-with(@id,'setting-top')]").click()
# <span class="s-top-right-text c-font-normal c-color-t" id="s-usersetting-top" name="tj_settingicon">设置</span> #属性