会话对象
会话对象让你能够跨请求保持某些参数。它也会在同一个Session实例发出的所有请求之间保持cookie,期间使用urllib3的connection pooling功能。所以如果你向同一主机发送多个请求,底层的TCP链接将会被重用,从而带来显著的性能提升。
我们来跨请求保持一些cookie:
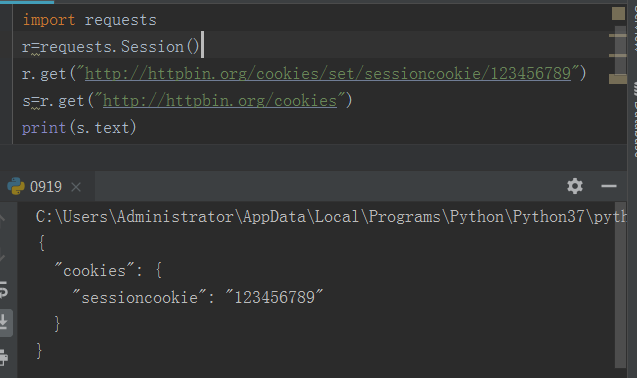
会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的:

任何你传递给请求方法的字典都会与已设置会话层数据合并。方法层的参数覆盖会话的参数。
不过需要注意,就算使用了会话,方法级别的参数也不会被跨请求保持。下面的例子只会和第一个请求发送cookie,而非第二个;

从字典参数中移除一个值:
有时你会想省略字典参数中一些会话层的键。要做到这一点,你只需简单地在方法层参数中将那个键的值设置为None,那个键就会被自动省略掉。
请求与响应对象
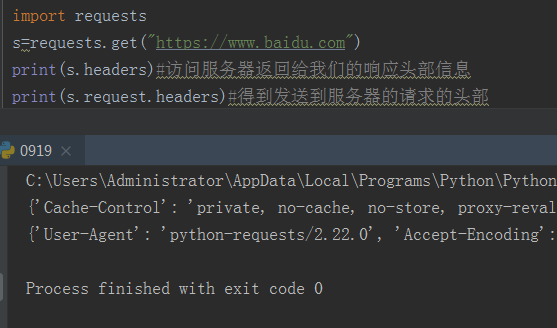
任何时候进行了类似requests.get()的调用,你都在做两件主要的事情。其一,你在构建一个Request对象,该对象将被发送到某个服务器请求或查询一些资源。其二。一旦requests得到一个从服务器返回的响应就会产生一个Response对象。该响应对象包含服务器返回的所有信息,也包含你原来创建的request对象。
准备的请求
当你从API或者会话调用中收到一个Response对象时,request属性其实是使用了PrepareRequest。有时在发送请求之前,你需要对body或者header做一些额外处理。
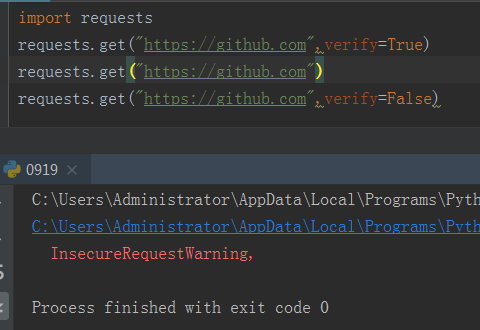
SSL证书验证
Requests可以为HTTPS请求验证SSL证书,就像web浏览器一样。SSL验证默认是开启的。
客户端证书
你也可以指定一个本地证书用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:
CA证书
Requests默认附带了一套它信任的根证书,来自于Mozilla trust store。
响应体内容工作流
默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过stream参数覆盖这个行为,推迟下载响应体直接访问Response.content属性。
import requests
#s=requests.get("https://www.baidu.com")
s=requests.get("https://www.baidu.com",stream=True)
print(s.content)
如果你在请求中把 stream 设为 True,Requests 无法将连接释放回连接池,除非你 消耗了所有的数据,或者调用了 Response.close。 这样会带来连接效率低下的问题。如果你发现你在使用 stream=True 的同时还在部分读取请求的 body(或者完全没有读取 body),那么你就应该考虑使用 with 语句发送请求,这样可以保证请求一定会被关闭:
with requests.get('http://httpbin.org/get', stream=True) as r:
# 在此处理响应。
保持活动状态(持久连接)
好消息——归功于 urllib3,同一会话内的持久连接是完全自动处理的!同一会话内你发出的任何请求都会自动复用恰当的连接!
注意:只有所有的响应体数据被读取完毕连接才会被释放为连接池;所以确保将 stream 设置为 False 或读取 Response 对象的 content 属性。
流式上传
Requests支持流式上传,这允许你发送大的数据流或文件而无需先把它们读入内存。
要使用流式上传,仅需为你的请求体提供一个类文件对象即可:

块编码请求
对于出去或进来的请求,Requsts也支持分块传输编码。要发送一个块编码的请求,仅需为你的请求体提供一个生成器(或任意没有具体长度的迭代器):
POST多个分块编码的文件
你可以在一个请求中发送多个文件。
事件挂钩
Requests有一个钩子系统,你可以用来操控部分请求过程,或信号事件处理。

自定义身份验证
Requests允许你使用自己指定的身份验证机制。
任何传递给请求方法的auth参数的可调用对象,在请求发出之前都有机会修改请求。
自定义的身份验证机制是作为requests.auth.AuthBase的子类来实现的,也非常容易定义。Requests在requests.auth中提供了两种常见的身份验证方案:
HTTPBasicAuth和HTTPDigestAuth。
流式请求
使用Response.iter_lines()你可以很方便地对流式API进行迭代。简单地设置stream为True便可以使用iter_lines对响应进行迭代:
import json
import requests
r = requests.get('http://httpbin.org/stream/20', stream=True)
for line in r.iter_lines():
# filter out keep-alive new lines
if line:
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line))


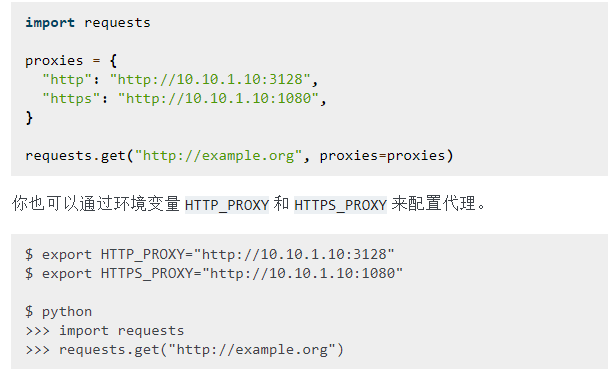
代理
如果需要使用代理,你可以通过为任意请求方法提供proxies参数来配置单个请求:
SOCKS
除了基本的HTTP代理,Request还支持SOCKS协议的代理。这是一个可选功能,若要使用,你需要安装第三方库。

合规性
Requests符合所有相关的规范和RFC,这样不会为用户造成不必要的困难。但这种对规范的考虑导致一些行为对于不熟悉相关规范的人来说看似有点奇怪。
编码方式

HTTP动词
Requests提供了几乎所有HTTP动词的功能:GET,OPTIONS,HEAD,POST,PUT,PATCH,DELETE。以下内容为使用Requests中的这些动词以及Github API提供了详细示例。
定制动词
有时候你会碰到一些服务器,处于某些原因,他们允许或者要求用户使用上述HTTP动词之外的定制动词。比如说WEBDAV服务器会要求你使用MKCOL方法。别担心,Requests一样可以搞定他们。你可以使用内建的.requests方法;
响应头链接字段
许多HTTP API都有响应头链接字段的特性,他们使得API能够更好地自我描述和自我暴露。
传输适配器
从v1.0.0以后,Requests的内部采用了模块化设计。部分原因是为了实现传输适配器。
阻塞和非阻塞
使用默认的传输适配器,Requests不提供任何形式的非阻塞IO。Response.content属性会阻塞,直到整个响应下载完成。
Header排序
在某些特殊情况下你也许需要按照次序来提供header,如果你向headers关键字参数传入一个OrderDict,就可以向提供一个带排序的header。然而,Requests 使用的默认 header 的次序会被优先选择,这意味着如果你在 headers 关键字参数中覆盖了默认 header,和键字参数中别的 header 相比,它们也许看上去会是次序错误的。
如果这个对你来说是个问题,那么用户应该考虑在 Session 对象上面设置默认 header,只要将 Session 设为一个定制的 OrderedDict 即可。这样就会让它成为优选的次序。
超时(timeout)
为防止服务器不能及时响应,大部分发至外部服务器的请求都应该带着timeout参数。在默认情况下,除非显式指定了timeout值,requests是不会自动进行超时处理的。如果没有timeout,你的代码可能会挂起若干分钟甚至更长时间。
连接超时指的是在你的客户端实现到远端机器端口的连接时(对应的是`connect()`_),Request 会等待的秒数。一个很好的实践方法是把连接超时设为比 3 的倍数略大的一个数值,因为 TCP 数据包重传窗口 (TCP packet retransmission window) 的默认大小是 3。
一旦你的客户端连接到了服务器并且发送了 HTTP 请求,读取超时指的就是客户端等待服务器发送请求的时间。(特定地,它指的是客户端要等待服务器发送字节之间的时间。在 99.9% 的情况下这指的是服务器发送第一个字节之前的时间)。
