Vue基础
1.vue生命周期
1)创建前后 beforeCreate/created
在beforeCreate 阶段,vue实例的挂载元素el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象有了,el还没有。
2)载入前后 beforeMount/mounted
在beforeMount阶段,vue实例的$el和data都初始化了,但还是挂载之前未虚拟的DOM节点,data尚未替换。
在mounted阶段,vue实例挂载完成,data成功渲染。
3)更新前后 beforeUpdate/updated
当data变化时,会触发beforeUpdate和updated方法。这两个不常用,不推荐使用。
4)销毁前后beforeDestory/destoryed
beforeDestory是在vue实例销毁前触发,一般在这里要通过removeEventListener解除手动绑定的事件。实例销毁后,触发的destroyed。
2.vue双向绑定原理
采用数据劫持结合发布者 - 订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
Vue原理:Vue的模式是m-v-vm模式,即(model-view-modelView),通过modelView作为中间层(即vm的实例),进行双向数据的绑定与变化。
1)通过建立虚拟dom树document.createDocumentFragment(),方法创建虚拟dom树。
2)一旦被监测的数据改变,会通过Object.defineProperty定义的数据拦截,截取到数据变化。
3)截取到的数据变化,从而通过订阅——发布者模式,触发Watcher(观察者),从而改变虚拟dom的中的具体数据。
4)最后,通过更新虚拟dom的元素值,从而改变最后渲染dom树的值,完成双向绑定。
3. v-show 与 v-if 区别
v-show是css切换,v-if是完整的销毁和重新创建。
频繁切换时用v-show,运行时较少改变时用v-if(性能)。
4. 计算属性和 watch 的区别
计算属性是自动监听依赖值的变化,从而动态返回内容;监听是一个过程,在监听的值变化时,可以触发一个回调,并做一些事情。
所以区别来源于用法,只是需要动态值,那就用计算属性;需要知道值的改变后执行业务逻辑,才用 watch。
当有一些数据需要随着另外一些数据变化时,建议使用computed。
当有一个通用的响应数据变化的时候,要执行一些业务逻辑或异步操作的时候建议使用watcher。
5. 组件中 data 为什么是函数
因为组件是用来复用的,JS 里对象是引用关系,这样作用域没有隔离。
组件是复用类型,可反复使用,需保证每一次根据组件声明对象创建组件实例时,data唯一,和其他不相互影响,则需通过函数return新对象;实例只有一个,只作用在一个dom结构
上。
6. keep-alive(失活的组件将会被缓存)
包裹动态组件时,会缓存不活动的组件实例,主要用于保留组件状态或避免重新渲染;
当在这些组件之间切换的时候,有时会想保持这些组件的状态,以避免反复重渲染导致的性能问题。重新创建动态组件的行为通常是非常有用的,有时候,我们更希望组件实例能够被在它们第一次被创建的时候缓存下来。为了解决这个问题,我们可以用一个 <keep-alive> 元素将其动态组件包裹起来。
7. 组件间通信(父子、非父子传值)
1)父传子:正向传值,通过父组件使用子组件标签时,给子组件添加自定义属性,在子组件内部使用props接收外部传递的属性,就能使用;
2)子传父:反向传值,通过父组件使用子组件时,给子组件添加自定义事件,当子组件传值给父组件时,触发自定义事件,达到传值目的;
3)非父子:新建一个Vue实例引入中间件,监听、触发;
8.vuex(管理全局数据状态)
https://blog.csdn.net/m0_37631322/article/details/89158150
五个属性:state,getters,mutations,actions,modules
注意:涉及组件间大量通信,优先使用vuex,不管大小项目。
1)State:对应全局数据,基本状态参数--相当于data,作用一样
2)Getters:计算属性,全局状态根据计算得到的值,外部调用$store.getters,相当与computed。接收state作为其第一个参数,接受其他 getters 作为第二个参数,如不需要,第二个参数可以省略
3)Mutations:修改状态的方法,专门用于修改全局状态,同步,外部调用$store.commit(‘函数名’, 参数),相当于methods。提交mutation是更改Vuex中的store中的状态的唯一方法;mutation必须是同步的,如果要异步需要使用action。接受 state 作为第一个参数,提交载荷作为第二个参数。(提交荷载在大多数情况下应该是一个对象),提交荷载也可以省略的
4)Actions:事件,包含异步操作,调用mutations修改state;Action 通过 $store.dispatch 方法触发。Action 类似于 mutation,不同在于:Action 提交的是 mutation,而不是直接变更状态。Action 可以包含任意异步操作。Action 函数接受一个与 store 实例具有相同方法和属性的 context 对象,因此你可以调用 context.commit 提交一个 mutation,或者通过 context.state 和 context.getters 来获取 state 和 getters。
5)modules:Vuex 允许我们将 store 分割到模块(module)。每个模块拥有自己的 state、mutation、action、getters。
9. 怎样理解单向数据流
这个概念出现在组件通信。父组件是通过 prop 把数据传递到子组件的,但是这个 prop 只能由父组件修改,子组件不能修改,否则会报错。子组件想修改时,只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件修改。
在子组件的 data 中拷贝一份 prop,data 是可以修改的;computed计算属性;
单向数据流: 顾名思义,数据流是单向的。数据流动方向可以跟踪,流动单一,追查问题的时候可以更快捷。缺点就是写起来不太方便。要使 UI 发生变更就必须创建各种 action来维护对应的 state。
双向数据绑定:数据之间是相通的,将数据变更的操作隐藏在框架内部。优点是在表单交互较多的场景下,会简化大量与业务无关的代码。缺点就是无法追踪局部状态的变化,增加了出错时 debug 的难度。
10. nextTick()
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后,立即使用这个回调函数,获取更新后的 DOM。
11. 什么是MVVM?
MVVM是是Model-View-ViewModel的缩写,Model代表数据模型,定义数据操作的业务逻辑,View代表视图层,负责将数据模型渲染到页面上,ViewModel通过双向绑定把View和Model进行同步交互,不需要手动操作DOM的一种设计思想。
12. MVVM和MVC区别?和其他框架(jquery)区别?那些场景适用?
MVVM和MVC都是一种设计思想,主要就是MVC中的Controller演变成ViewModel,,MVVM主要通过数据来显示视图层而不是操作节点,解决了MVC中大量的DOM操作使页面渲染性能降低,加载速度慢,影响用户体验问题。主要用于数据操作比较多的场景。
13. 请说下封装vue组件的过程?
1)组件可以提升整个项目的开发效率能够把页面抽象成多个相对独立的模块,解决了我们传统项目开发:效率低,难维护,复用性等问题。
2)使用Vue.extend方法创建一个组件,然后使用Vue.component方法注册组件。子组件需要数据,可以在道具中接受定义。而子组件修改好数据后,想把数据传递给父组件。可以采用发射方法。
14. vue和react区别
--相同点:都鼓励组件化,都有’props’的概念,都有自己的构建工具,Reat与Vue只有框架的骨架,其他的功能如路由、状态管理等是框架分离的组件。
--不同点:React:数据流单向,语法—JSX,在React中你需要使用setState()方法去更新状态。Vue:数据双向绑定,语法--HTML,state对象并不是必须的,数据由data属性在Vue对象中进行管理。适用于小型应用,但对于对于大型应用而言不太适合。
15. $route和$router的区别
$route是“路由信息对象”,包括path,params,hash,query,fullPath,matched,name等路由信息参数。而$router是“路由实例”对象包括了路由的跳转方法,钩子函数等。
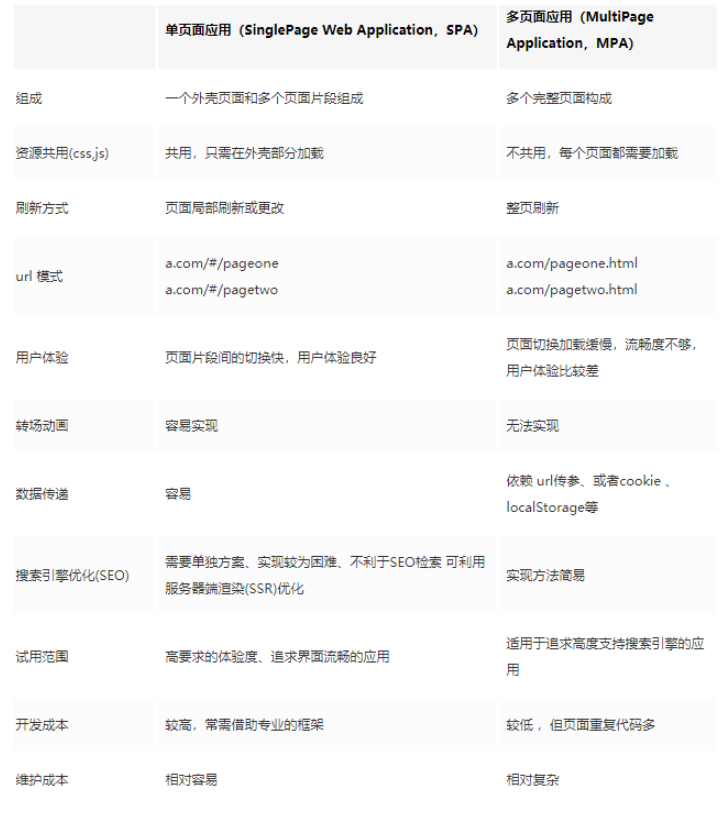
16. Vue 等单页面应用的优缺点
优点:良好的交互体验;良好的前后端工作分离模式;减轻服务器压力
缺点:SEO 难度较高;前进、后退管理;初次加载耗时多
单页面的优点:
1,用户体验好,快,内容的改变不需要重新加载整个页面,基于这一点spa对服务器压力较小
2,前后端分离
3,页面效果会比较炫酷(比如切换页面内容时的专场动画)
单页面缺点:
1,不利于seo
2,导航不可用,如果一定要导航需要自行实现前进、后退。(由于是单页面不能用浏览器的前进后退功能,所以需要自己建立堆栈管理)
3,初次加载时耗时多
4,页面复杂度提高很多
17.单页面与多页面的区别
https://www.cnblogs.com/yunyea/p/8824178.html
单页面应用(SPA):是指只有一个主页面的应用,浏览器一开始要加载所有必须的 html, js, css。所有的页面内容都包含在这个所谓的主页面中。但在写的时候,还是会分开写(页面片段),然后在交互的时候由路由程序动态载入,单页面的页面跳转,仅刷新局部资源。多应用于pc端。
多页面(MPA),就是指一个应用中有多个页面,页面跳转时是整页刷新。
18.vue static和assets的区别?
assets里面的资源会被webpack打包进代码,static里面的资源就直接引用了;
一般在static里放一些类库的文件,assets放属于项目的资源文件。
说的再通俗一点,就是static放别人家的资源,assets放自己家的资源。
Js基础
1. ajax中 get 和 post 有什么区别?
1)get和post都是数据提交的方式。
2)get的数据是通过网址问号后边拼接的字符串进行传递的。post是通过一个HTTP包体进行传递数据的。
3)get的传输量是有限制的,post是没有限制的。
4)get的安全性可能没有post高,所以我们一般用get来获取数据,post一般用来修改数据。
2. ajax 和 jsonp ?
相同点:都是请求一个url
不同点:ajax的核心是通过xmlHttpRequest获取内;jsonp的核心则是动态添加<script>标签来调用服务器 提供的js脚本。
3.ajax的工作原理?
https://www.cnblogs.com/wanghp/p/6991554.html
ajax并非一种新的技术,而是几种原有技术的结合体。
1)使用CSS和XHTML来表示;2)使用DOM模型来交互和动态显示;3)使用XMLHttpRequest来和服务器进行异步通信;4)使用javascript来绑定和调用;
ajax 的全称是Asynchronous JavaScript and XML,其中,Asynchronous 是异步的意思,它有别于传统web开发中采用的同步的方式。
Ajax的原理简单来说是通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。这其中最关键的一步就是从服务器获得请求数据。要清楚这个过程和原理,我们必须对 XMLHttpRequest有所了解。
XMLHttpRequest是ajax的核心机制,它是在IE5中首先引入的,是一种支持异步请求的技术。简单的说,也就是javascript可以及时向服务器提出请求和处理响应,而不阻塞用户。达到无刷新的效果。
拓展:ajax缺点
1)ajax干掉了back按钮,即对浏览器后退机制的破坏;2)对搜索引擎的支持比较弱;3)违背了url和资源定位的初衷;4)一些手持设备(如手机、PDA等)现在还不能很好的支持ajax;
拓展:手写ajax
this.$.ajax({
type: 'get',
url: 'test.json',
data: {
username: this.$('#username').val(),
content: this.$('#content').val()
},
dataType: 'json',
success: function (data) {
// ...
}
})
4. ajax请求流程?
1)创建一个xmlHttpRequest对象
var xmlhttp= new XMLHttpRequest();
2)创建一个http请求,设置.open()参数:请求的方法,url,和是否异步
xmlhttp.open('get',url,true),
3)发送http请求
xmlhttp.send(); 发送请求到服务器
4)接收服务器的响应,判断onreadyState 是否== 4 和status是否等于200,是的话即接收数据成功
xmlhttp.onreadystatechange = function(){
if(xmlhttp.onreadyState == 4 && status == 200){ }
}
(1)当readystate值从一个值变为另一个值时,都会触发readystatechange事件。
(2)当readystate==4时,表示已经接收到全部响应数据。
(3)当status ==200时,表示服务器成功返回页面和数据。
(4)如果(2)和(3)内容同时满足,则可以通过xhr.responseText,获得服务器返回的内容。
拓展:XMLHttpRequest对象
onreadystatechange 每次状态改变所触发事件的事件处理程序
responseText 从服务器进程返回数据的字符串形式
responseXML 从服务器进程返回的DOM兼容的文档数据对象
status 从服务器返回的数字代码,比如常见的404(未找到)和200(已就绪)
status Text 伴随状态码的字符串信息
readyState 对象状态值
0 (未初始化) 对象已建立,但是尚未初始化(尚未调用open方法)
1 (初始化) 对象已建立,尚未调用send方法
2 (发送数据) send方法已调用,但是当前的状态及http头未知
3 (数据传送中) 已接收部分数据,因为响应及http头不全,这时通过responseBody和responseText获取部分数据会出现错误,
4 (完成) 数据接收完毕,此时可以通过通过responseXml和responseText获取完整的回应数据
5.jsonp(非正式的传输协议)
原理:利用浏览器“漏洞”,src不受同源策略的影响可以访问其他页面的数据。
过程:1)创建全局函数;
2)创建script标签
3)将src的属性值换成接口,?后接给后端传递的参数
4)将script插入页面
5)当script加载完毕以后删除自身
6.解决跨域方式
1)jsonp
2)后端跨域
7.同源策略
为了保证各个浏览器地址之间的数据不能相互的被访问而设定的规则
同源:协议,域名,端口号相同
8. 闭包是什么,有什么特性,对页面有什么影响
闭包就是能够读取其他函数内部变量的函数,使得函数不被GC回收,如果过多使用闭包,容易导致内存泄露。
1)好处:可以让局部变量在全局访问;保留i的值
2)坏处:占用内存空间;在ie浏览器下会造成内存溢出;不要滥用闭包,用完记得销毁
手写闭包:
function demo() {
let count = 1
return function () {
count++
console.log(count)
}
}
解释:addCount() 执行的时候, 返回一个函数, 函数是可以创建自己的作用域的, 但是此时返回的这个函数内部需要引用 addCount() 作用域下的变量 count, 因此这个 count 是不能被销毁的.接下来需要几个计数器我们就定义几个变量就可以,并且他们都不会互相影响,每个函数作用域中还会保存 count 变量不被销毁,进行不断的累加。
9. Gc机制是什么?为什么闭包不会被回收变量和函数?
1)Gc垃圾回收机制;2)外部变量没释放,所以指向的大函数内的小函数也释放不了;
垃圾回收机制:当函数运行完毕以后,如果内部的变量或函数没有在全局挂载的话,那么这个函数就会被销毁掉,若第二次执行,函数里面代码就会重新执行。
10. 说出几个http协议状态码?
200, 201, 302, 304, 400, 404, 500
200:请求成功
201:请求成功并且服务器创建了新的资源
302:服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。
304:自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
400:服务器不理解请求的语法。
404:请求的资源(网页等)不存在
500: 内部服务器错误
11.es6
https://www.jianshu.com/p/5511bf45642b
1)let const
let:不允许被重复定义;不会被声明提升;可以将值保留在块级作用域内;不能删除变量。
const:不允许被重复定义;常量不允许修改;不会被声明提升。
2)字符串模板
``表示,${}表示包含变量
includes:判断字符串中是否存在某个字符串
例:` ${name},no matter what you do,
I trust you.`3)数组
Array.of:将一组数值转换为数组
Array.from:将伪数组转换为数组
for of:循环
4)解构赋值
a.解构数组
数组以序号位置一一对应,这是一个有序的对应关系。
let [a, b, c] = [1, 2, 3];
// 即: let a = 1;let b = 2;let c = 3;
//[a,,c]忽略b的写法也允许b.解构对象
对象根据属性名一一对应,这是一个无序的对应关系。
const obj = { a: "aaa", b: "bbb" };
let { a, b,c, d="ddd",a:e} = obj ;
// 变量与属性重名对应赋值,即let a=obj .a;let b=obj .b
// 没有找到对应属性的为undefined,即let c = undefined
// 对应的属性值严格等于undefined,取默认值,即let d = "ddd"
// 匹配属性:真正变量,即let e = obj .a(对象中"a"对应的值)
console.log(a,b,c,d,e); //aaa bbb undefined ddd aaac.字符串解构赋值
let [a, b, c, d, e] = 'hello'; //字符串数组
console.log(a,b,c,d,e); //h e l l o
let {length} = 'hello';
//类似数组的对象都有一个length属性,因此还可以对这个属性解构赋值
console.log(length); //5d.函数参数的结构
5)箭头函数
普遍应用在回调函数上,()=> {}表示
this的指向,指向定义时的对象,而不是调用时的对象
6)sumbol
新增基本数据类型,值是独一无二的;
声明时不能使用new Symbol(),而是 Symbol();
声明时可以加参数,用于描述;
作为key时不能被遍历;
7)set集合
相当于数组封装好的另一种用法,最简易的数组去重
8)展开运算符
...[]表示
例:const arr1 = [1,2,3];
const arr2 = [3,4];
console.log(...arr1); //1 2 3
const arr3 = [...arr1,...arr2];
console.log(arr3); //arr1和arr2的合并
9)导入、导出模块
https://www.cnblogs.com/nanianqiming/p/8074867.html
exprot:导出。作为一个模块,它可以选择性的暴露自己的属性和方法,供其他模块使用
import:导入。作为一个模块,可以根据需要,引入其他模块提供的属性和方法,供自己的模块使用
例:批量导出导入
let name = 1,age = 25
export {bame, age}
import {name, age} from modulesA(模块路径)
import * as obj from modulesA(模块路径) 整体导入,as重命变量名
12.rem响应式布局以及vw百分比布局
rem
rem单位:CSS3 新增的一个相对单位;相对于根元素html的font-size的值进行动态计算得到的,如font-size:14px,1rem = 14px。目前移动端响应式布局,推荐使用 rem。
注意:rem需要配合媒体查询才可实现响应式布局
em
·em单位:相对于父元素字体大小,默认情况下,1em = 16px
一般适用于响应式,但不推荐使用,计算比较繁琐。
vw/vh
vw单位:viewpoint width 视窗宽度的百分比(1vw 代表视窗的宽度为 1%)
vh单位:viewpoint height 视窗高度的百分比(1vh 代表视窗的高度为 1%)
一般适用于百分比布局。
拓展:响应式布局和自适应布局区别
1.自适应布局通过检测视口分辨率,来判断当前访问的设备是:pc端、平板、手机,从而请求服务层,返回不同的页面;
响应式布局通过检测视口分辨率,针对不同客户端,在客户端做代码处理,来展现不同的布局和内容。
2.自适应布局需要开发多套界面;
响应式布局只需要开发一套界面就可以了。
3.自适应布局对页面做的屏幕适配是在一定范围:比如pc端一般要大于1024像素,手机端要小于768像素;
响应式布局是一套页面全部适应。
4.自适应布局如果屏幕太小会发生内容过于拥挤;
响应式布局正是为了解决这个问题而衍生出的概念,它可以自动识别屏幕宽度并做出相应调整的网页设计。
13.定时器
a. 单次定时使用 setTimeout;后面执行匿名函数3000毫秒后弹出“hello”,只执行一次。
例:setTimeout(function () {
alert('hello')
}, 3000)
b. 多次定时使用 stime = setInterval,多次执行。
例:stime = setInterval(function () {
alert('你好')
}, 4000)
c. 为了节约系统资源,多次定时通常需要清除操作,使用clearInterval。
例:clearInterval(stime)
14.块级作用域
任何一对花括号({和})中的语句集都属于一个块,在这之中定义的所有变量在代码块外都是不可见的,我们称之为块级作用域。
15.link和@import引入外部样式的区别
1)隶属上的差别;
link属于HTML标签,而@import完全是CSS提供的一种方式。
2)加载顺序的不同;
当页面被加载的时候,link引用的CSS会同时被加载,而@import引用的CSS 会等到页面全部被下载完再被加载。所以有时候浏览@import加载CSS的页面时开始会没有样式,然后突然样式会出现,网速慢的时候还挺明显。
3)兼容性上的差别;
由于@import是CSS2.1提出的,@import只有在IE5以上的才能识别,而link标签无此问题。
4)使用dom控制样式上的差别;
当使用javascript控制DOM(document.styleSheets)去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的。
5)@import次数;
限制@import只能引入31次css文件。
6)link是htm方式,而@import是css方式;
16.从输入URL到浏览器显示页面发生了什么?
1.在浏览器中输入url(解析IP地址)
2.应用层DNS解析域名
3.应用层客户端发送HTTP请求
4.传输层TCP传输报文(3次握手)
5.网络层IP协议查询MAC地址
6.数据到达数据链路层
7.服务器接收数据
8.服务器响应请求
9.服务器返回相应文件
17.性能优化常见做法有哪些?
雪碧图、减少http请求数、避免重定向、缓存ajax请求、延迟加载、预加载、减少DOM数、使用框架例如React的虚拟DOM树、减少DOM操作、减少 css 里 @import 写法、减小cookie大小、将css放在html顶部,js文件放在htl底部、删除无效代码和注释、优化图片大小
18.sessionStorage、localStorage、cookie区别
1)存储大小
cookie:一般不超过4K(因为每次http请求都会携带cookie、所以cookie只适合保存很小的数据,如会话标识)
sessionStorage:5M或者更大
localStorage:5M或者更大
2)数据有效期
cookie:一般由服务器生成,可以设置失效时间;若没有设置时间,关闭浏览器cookie失效,若设置了时间,cookie就会存放在硬盘里,过期才失效
sessionStorage:仅在当前浏览器窗口关闭之前有效,关闭页面或者浏览器会被清除
localStorage:永久有效,窗口或者浏览器关闭也会一直保存,除非手动永久清除,因此用作持久数据
3)作用域
cookie:在所有同源窗口中都是共享的
sessionStorage:在同一个浏览器窗口是共享的(不同浏览器、同一个页面也是不共享的)
localStorage:在所有同源窗口中都是共享的
4)通信
ccokie:十种携带在同源的http请求中,即使不需要,故cookie在浏览器和服务器之间来回传递;如果使用cookie保存过多数据会造成性能问题
sessionStorage:仅在客户端(即浏览器)中保存,不参与和服务器的通信;不会自动把数据发送给服务器,仅在本地保存
localStorage:仅在客户端(即浏览器)中保存,不参与和服务器的通信;不会自动把数据发送给服务器,仅在本地保存
5)易用性
cookie:需要自己进行封装,原生的cookie接口不够友好
sessionStorage:原生接口可以接受,可以封装来对Object和Array有更好的支持
localStorage:原生接口可以接受,可以封装来对Object和Array有更好的支持
19.http和https的区别?
1)Http 协议都是未加密的,http传输隐私消息非常的不安全
2)https就是由ssl+http协议构建进行加密传送的要比http协议安全
3)https需要申请证书,会需要一定的费用
4)http未加密,https 是加密的
5)http端口是80,https 是443
20.xss跨站脚本攻击
xss是一种经常出现在web应用中的计算机安全漏洞,也是最主流的攻击方式。
xss是指恶意攻击者利用网站没有对用户提交的数据进行转义处理或过滤不足的缺点,进而添加一些代码,嵌入到web页面中去;使别的用户访问都会执行相应的嵌入代码,从而盗取用户资料、利用用户身份进行某些动作或者对访问者进行病毒侵害的一种攻击方式。
为啥出现?
主要原因是:过于信任客户端提交的数据;xss根源就是没完全过滤客户端提交的数据
细节分析:客户端提交的数据本就是应用需要的,但是恶意攻击者利用网站对客户端提交的数据的信任,在数据中插入一些符号以及js代码,那这些数据将会成为应用代码中的一部分,进而攻击者就可以进行攻击。
危害:
1)盗取各类用户账号;如:机器登录账号...
2)控制企业数据;包括读取、篡改、添加、删除企业敏感数据能力;
3)盗窃企业具有商业价值的重要资料
4)非法转账
5)控制受害者机器向其他网站发起攻击
如何解决?
不要信任任何客户端提交的数据;只要是客户端提交的数据信息都应该先做过滤处理再进行下一步操作。
21.&与&&、|与||的区别?
&和|无论左边结果如何,右边都要继续运算;&&和||左边计算完,看结果进不进行右边的计算。
&和&&、| 和 || 运行最后的结果都是相同的;&&和 || 更为高效一点,可以减少不必要的运算。
22.