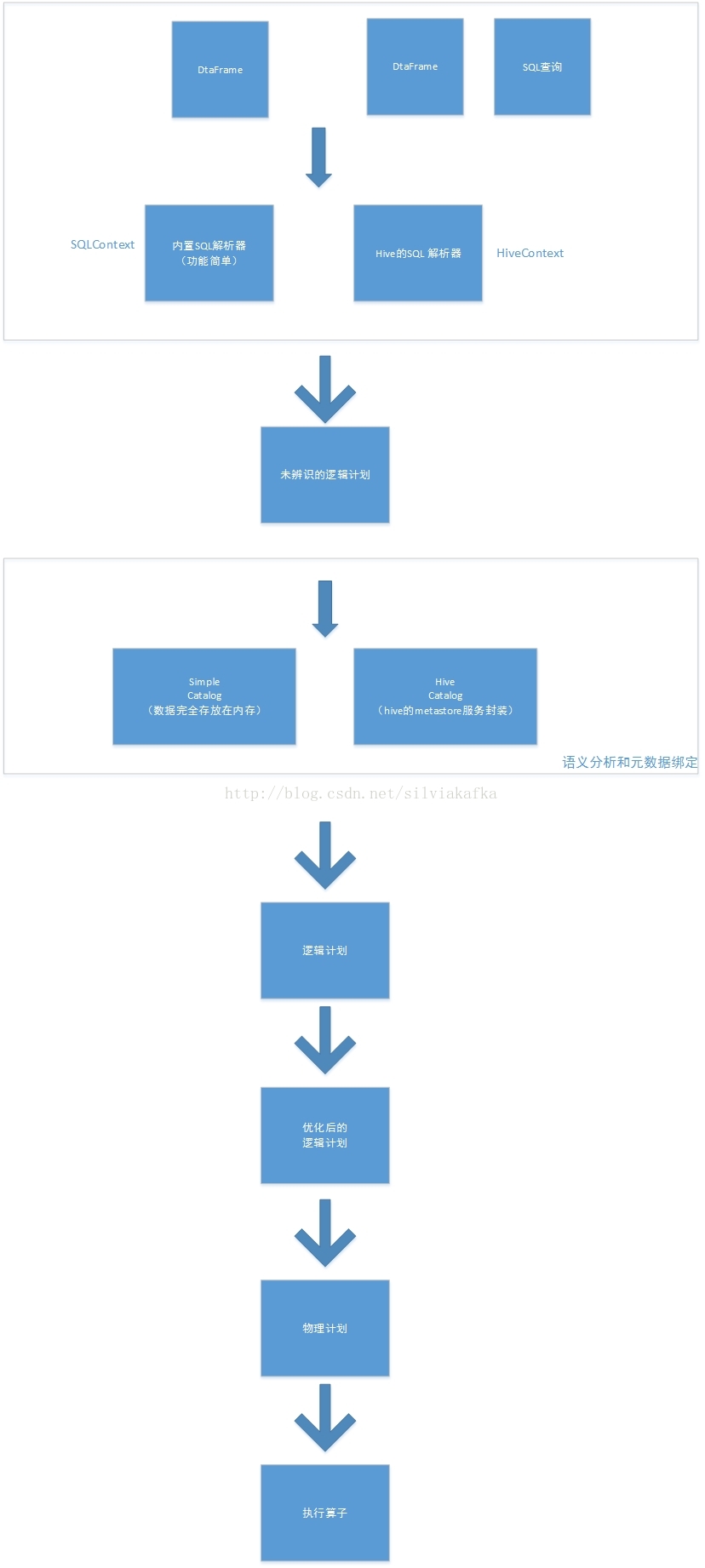
一. 整体架构
总结为如下图:
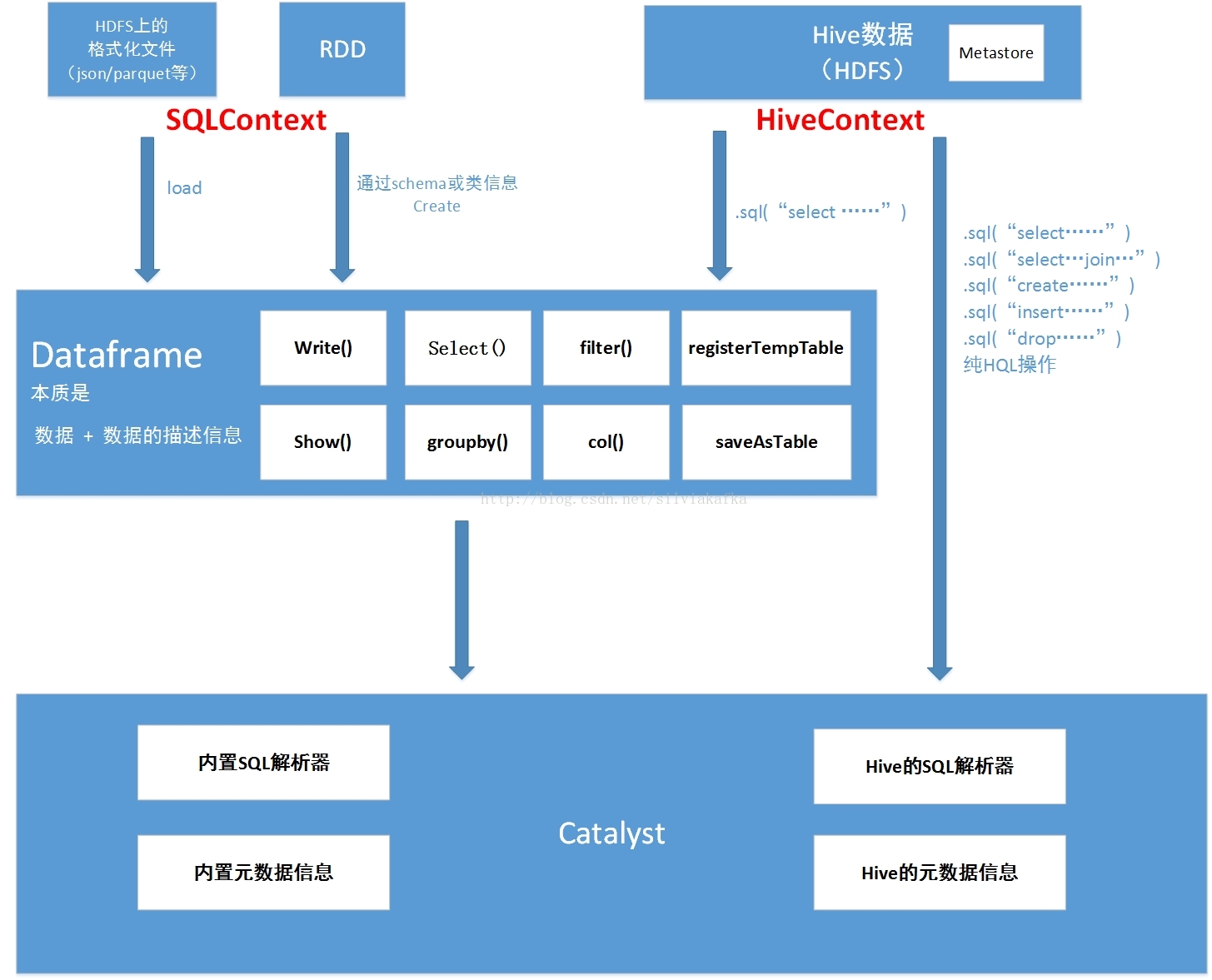
Dataframe本质是 数据 + 数据的描述信息(结构元信息)
所有的上述SQL及dataframe操作最终都通过Catalyst翻译成spark程序RDD操作代码
sparkSQL前身是shark,大量依赖Hive项目的jar包与功能,但在上面的扩展越来越难,因此出现了SparkSQL,它重写了分析器,执行器
脱离了对Hive项目的大部分依赖,基本可以独立去运行,只用到两个地方:
1.借用了hive的词汇分析的jar即HiveQL解析器
2.借用了hive的metastore和数据访问API即hiveCatalog
也就是说上图的左半部分的操作全部用的是sparkSQL本身自带的内置SQL解析器解析SQL进行翻译,用到内置元数据信息(比如结构化文件中自带的结构元信息,RDD的schema中的结构元信息)
右半部分则是走的Hive的HQL解析器,还有Hive元数据信息
因此左右两边的API调用的底层类会有不同
SQLContext使用:
简单的解析器(scala语言写的sql解析器)【比如:1.在半结构化的文件里面使用sql查询时,是用这个解析器解析的,2.访问(半)结构化文件的时候,通过sqlContext使用schema,类生成Dataframe,然后dataframe注册为表时,registAsTmpTable
然后从这个表里面进行查询时,即使用的简单的解析器,一些hive语法应该是不支持的,有待验证)】
simpleCatalog【此对象中存放关系(表),比如我们指定的schema信息,类的信息,都是关系信息】
HiveContext使用:
HiveQL解析器【支持hive的hql语法,如只有通过HiveContext生成的dataframe才能调用saveAsTable操作】
hiveCatalog(存放数据库和表的元数据信息)
Sparksql的解析与Hiveql的解析的执行流程:
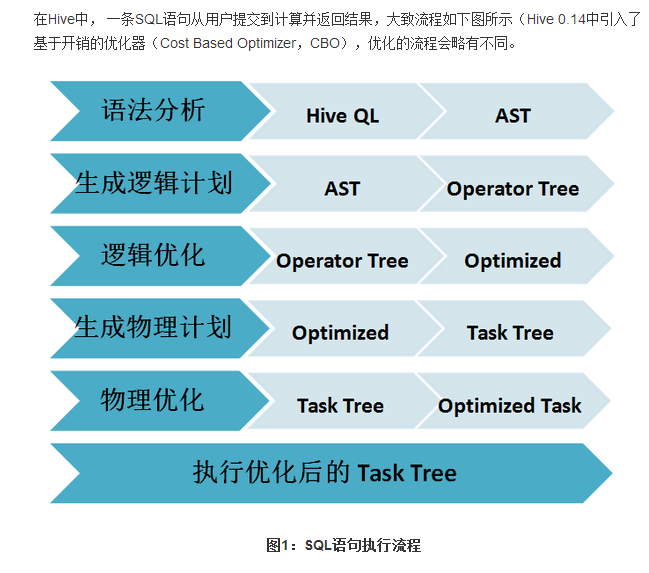
一个Sql语句转化为实际可执行的Spark的RDD模型需要经过以下几个步骤:
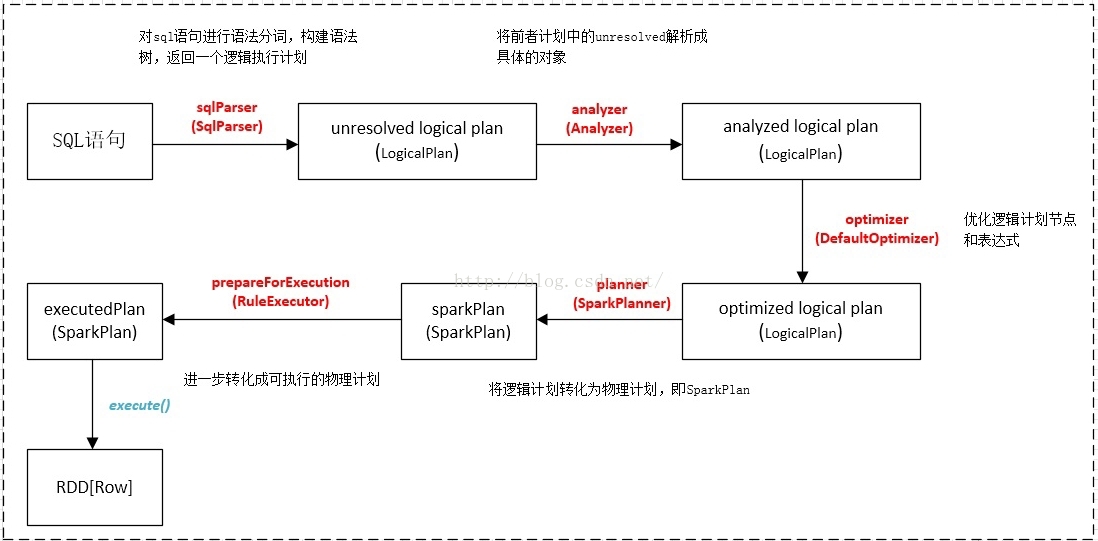
主要介绍下Spark-SQL里面的主要类成员:
1.2 SQLContext
SQL上下文环境,它保存了QueryExecution中所需要的几个类:
一个存储<tableName,logicalPlan>的map结构,查找关系的目录,注册表,注销表,查询表和逻辑计划关系的类
-
@transient
-
protected[sql] lazy val catalog: Catalog = new SimpleCatalog(conf)
-
class SimpleCatalog(val conf: CatalystConf) extends Catalog {
-
val tables = new mutable.HashMap[String, LogicalPlan]()
-
override def registerTable(
-
tableIdentifier: Seq[String],
-
plan: LogicalPlan): Unit = {
-
-
val tableIdent = processTableIdentifier(tableIdentifier)
-
tables += ((getDbTableName(tableIdent), plan))
-
}
-
override def unregisterTable(tableIdentifier: Seq[String]): Unit = {
-
val tableIdent = processTableIdentifier(tableIdentifier)
-
tables -= getDbTableName(tableIdent)
-
}
-
override def unregisterAllTables(): Unit = {
-
tables.clear()
-
}
-
override def tableExists(tableIdentifier: Seq[String]): Boolean = {
-
val tableIdent = processTableIdentifier(tableIdentifier)
-
tables.get(getDbTableName(tableIdent)) match {
-
case Some(_) => true
-
case None => false
-
}
-
}
-
override def lookupRelation(
-
tableIdentifier: Seq[String],
-
alias: Option[String] = None): LogicalPlan = {
-
val tableIdent = processTableIdentifier(tableIdentifier)
-
val tableFullName = getDbTableName(tableIdent)
-
-
val table = tables.getOrElse(tableFullName, sys.error(s"Table Not Found: $tableFullName"))
-
val tableWithQualifiers = Subquery(tableIdent.last, table)
-
-
-
alias.map(a => Subquery(a, tableWithQualifiers)).getOrElse(tableWithQualifiers)
-
}
-
override def getTables(databaseName: Option[String]): Seq[(String, Boolean)] = {
-
tables.map {
-
case (name, _) => (name, true)
-
}.toSeq
-
}
-
override def refreshTable(databaseName: String, tableName: String): Unit = {
-
throw new UnsupportedOperationException
-
}
-
}
1.2.2 SparkSQLParser
将Sql语句解析成语法树,返回一个Logical Plan。它首先拆分不同的SQL(将其分类),然后利用fallback解析。
-
-
-
-
-
-
-
private[sql] class SparkSQLParser(fallback: String => LogicalPlan) extends AbstractSparkSQLParser {
-
protected val AS = Keyword("AS")
-
protected val CACHE = Keyword("CACHE")
-
protected val CLEAR = Keyword("CLEAR")
-
protected val IN = Keyword("IN")
-
protected val LAZY = Keyword("LAZY")
-
protected val SET = Keyword("SET")
-
protected val SHOW = Keyword("SHOW")
-
protected val TABLE = Keyword("TABLE")
-
protected val TABLES = Keyword("TABLES")
-
protected val UNCACHE = Keyword("UNCACHE")
-
override protected lazy val start: Parser[LogicalPlan] = cache | uncache | set | show | others
-
private lazy val cache: Parser[LogicalPlan] =
-
CACHE ~> LAZY.? ~ (TABLE ~> ident) ~ (AS ~> restInput).? ^^ {
-
case isLazy ~ tableName ~ plan =>
-
CacheTableCommand(tableName, plan.map(fallback), isLazy.isDefined)
-
}
-
private lazy val uncache: Parser[LogicalPlan] =
-
( UNCACHE ~ TABLE ~> ident ^^ {
-
case tableName => UncacheTableCommand(tableName)
-
}
-
| CLEAR ~ CACHE ^^^ ClearCacheCommand
-
)
-
private lazy val set: Parser[LogicalPlan] =
-
SET ~> restInput ^^ {
-
case input => SetCommandParser(input)
-
}
-
private lazy val show: Parser[LogicalPlan] =
-
SHOW ~> TABLES ~ (IN ~> ident).? ^^ {
-
case _ ~ dbName => ShowTablesCommand(dbName)
-
}
-
private lazy val others: Parser[LogicalPlan] =
-
wholeInput ^^ {
-
case input => fallback(input)
-
}
-
}
1.2.3 Analyzer
语法分析器,Analyzer会使用Catalog和FunctionRegistry将UnresolvedAttribute和UnresolvedRelation转换为catalyst里全类型的对象。例如将
'UnresolvedRelation[test], None
转化为
Relation[id#0L,dev_id#1,dev_chnnum#2L,dev_name#3,dev_chnname#4,car_num#5,car_numtype#6,car_numcolor#7,car_speed#8,car_type#9,car_color#10,car_length#11L,car_direct#12,car_way_code#13,cap_time#14L,cap_date#15L,inf_note#16,max_speed#17,min_speed#18,car_img_url#19,car_img1_url#20,car_img2_url#21,car_img3_url#22,car_img4_url#23,car_img5_url#24,rec_stat#25,dev_chnid#26,car_img_count#27,save_flag#28,dc_cleanflag#29,pic_id#30,car_img_plate_top#31L,car_img_plate_left#32L,car_img_plate_bottom#33L,car_img_plate_right#34L,car_brand#35L,issafetybelt#36,isvisor#37,bind_stat#38,car_num_pic#39,combined_pic_url#40,verify_memo#41,rec_stat_tmp#42]org.apache.spark.sql.parquet.ParquetRelation2@2a400010
-
class Analyzer(
-
catalog: Catalog,
-
registry: FunctionRegistry,
-
conf: CatalystConf,
-
maxIterations: Int = 100)
-
extends RuleExecutor[LogicalPlan] with HiveTypeCoercion with CheckAnalysis {
-
……
-
}
1.2.4 Optimizer
优化器,将Logical Plan进一步进行优化
-
object DefaultOptimizer extends Optimizer {
-
val batches =
-
-
Batch("Remove SubQueries", FixedPoint(100),
-
EliminateSubQueries) ::
-
Batch("Operator Reordering", FixedPoint(100),
-
UnionPushdown,
-
CombineFilters,
-
PushPredicateThroughProject,
-
PushPredicateThroughJoin,
-
PushPredicateThroughGenerate,
-
ColumnPruning,
-
ProjectCollapsing,
-
CombineLimits) ::
-
Batch("ConstantFolding", FixedPoint(100),
-
NullPropagation,
-
OptimizeIn,
-
ConstantFolding,
-
LikeSimplification,
-
BooleanSimplification,
-
SimplifyFilters,
-
SimplifyCasts,
-
SimplifyCaseConversionExpressions) ::
-
Batch("Decimal Optimizations", FixedPoint(100),
-
DecimalAggregates) ::
-
Batch("LocalRelation", FixedPoint(100),
-
ConvertToLocalRelation) :: Nil
-
}
例如:
CombineFilters:递归合并两个相邻的filter。例如:将
Filter(a>1)
Filter(b>1)
Project……
转化为
Filter(a>1) AND Filter(b>1)
Project……
CombineLimits:合并两个相邻的limit。例如:将select * from (select * from c_picrecord limit 100)a limit 10
优化为:
Limit if ((100 < 10)) 100 else 10
Relation[id#0L,dev_id#1,dev_chnnum#2L,de……
1.2.5 SparkPlanner
将LogicalPlan转化为SparkPlan
-
protected[sql] class SparkPlanner extends SparkStrategies {
-
val sparkContext: SparkContext = self.sparkContext
-
val sqlContext: SQLContext = self
-
def codegenEnabled: Boolean = self.conf.codegenEnabled
-
def unsafeEnabled: Boolean = self.conf.unsafeEnabled
-
def numPartitions: Int = self.conf.numShufflePartitions
-
def strategies: Seq[Strategy] =
-
experimental.extraStrategies ++ (
-
DataSourceStrategy ::
-
DDLStrategy ::
-
TakeOrdered ::
-
HashAggregation ::
-
LeftSemiJoin ::
-
HashJoin ::
-
InMemoryScans ::
-
ParquetOperations ::
-
BasicOperators ::
-
CartesianProduct ::
-
BroadcastNestedLoopJoin :: Nil)
-
}
比方说:
Subquery test
Relation[id#0L,dev_id#1,dev_chnnum#2L,dev_name#3,dev_chnname#4,car_num#5,car_numtype#6,car_numcolor#7,car_speed#8,car_type#9,car_color#10,car_length#11L,car_direct#12,car_way_code#13,cap_time#14L,cap_date#15L,inf_note#16,max_speed#17,min_speed#18,car_img_url#19,car_img1_url#20,car_img2_url#21,car_img3_url#22,car_img4_url#23,car_img5_url#24,rec_stat#25,dev_chnid#26,car_img_count#27,save_flag#28,dc_cleanflag#29,pic_id#30,car_img_plate_top#31L,car_img_plate_left#32L,car_img_plate_bottom#33L,car_img_plate_right#34L,car_brand#35L,issafetybelt#36,isvisor#37,bind_stat#38,car_num_pic#39,combined_pic_url#40,verify_memo#41,rec_stat_tmp#42]org.apache.spark.sql.parquet.ParquetRelation2@2a400010
通过DataSourceStrategy中的
-
- case PhysicalOperation(projectList, filters, l @ LogicalRelation(t: HadoopFsRelation)) =>
将其转化为
PhysicalRDD
1.2.6 PrepareForExecution
在SparkPlan中插入Shuffle的操作,如果前后2个SparkPlan的outputPartitioning不一样的话,则中间需要插入Shuffle的动作,比分说聚合函数,先局部聚合,然后全局聚合,局部聚合和全局聚合的分区规则是不一样的,中间需要进行一次Shuffle。
-
-
-
- @transient
- protected[sql] val prepareForExecution = new RuleExecutor[SparkPlan] {
- val batches =
- Batch("Add exchange", Once, EnsureRequirements(self)) :: Nil
- }
GeneratedAggregate false,[Coalesce(SUM(PartialCount#44L),0) AS count#43L], false
GeneratedAggregatetrue, [COUNT(1) AS PartialCount#44L], false
PhysicalRDDMapPartitionsRDD[1]
经过PrepareForExecution,转化为
GeneratedAggregate false,[Coalesce(SUM(PartialCount#44L),0) AS count#43L], false
Exchange SinglePartition
GeneratedAggregate true, [COUNT(1) AS PartialCount#44L], false
PhysicalRDDMapPartitionsRDD[1]
1.3 QueryExecution
SQL语句执行环境
-
protected[sql] class QueryExecution(val logical: LogicalPlan) {
-
def assertAnalyzed(): Unit = analyzer.checkAnalysis(analyzed)
-
lazy val analyzed: LogicalPlan = analyzer.execute(logical)
-
lazy val withCachedData: LogicalPlan = {
-
assertAnalyzed()
-
cacheManager.useCachedData(analyzed)
-
}
-
lazy val optimizedPlan: LogicalPlan = optimizer.execute(withCachedData)
-
-
lazy val sparkPlan: SparkPlan = {
-
SparkPlan.currentContext.set(self)
-
-
-
planner.plan(optimizedPlan).next()
-
}
-
lazy val executedPlan: SparkPlan = prepareForExecution.execute(sparkPlan)
-
lazy val toRdd: RDD[Row] = {
-
toString
-
executedPlan.execute()
-
}
-
protected def stringOrError[A](f: => A): String =
-
try f.toString catch { case e: Throwable => e.toString }
-
def simpleString: String =
-
s"""== Physical Plan ==
-
|${stringOrError(executedPlan)}
-
""".stripMargin.trim
-
-
override def toString: String = {
-
def output =
-
analyzed.output.map(o => s"${o.name}: ${o.dataType.simpleString}").mkString(", ")
-
-
-
-
s"""== Parsed Logical Plan ==
-
|${stringOrError(logical)}
-
|== Analyzed Logical Plan ==
-
|${stringOrError(output)}
-
|${stringOrError(analyzed)}
-
|== Optimized Logical Plan ==
-
|${stringOrError(optimizedPlan)}
-
|== Physical Plan ==
-
|${stringOrError(executedPlan)}
-
|Code Generation: ${stringOrError(executedPlan.codegenEnabled)}
-
|== RDD ==
-
""".stripMargin.trim
-
}
-
}
这里唯一需要注意的是analyzed,optimizedPlan,sparkPlan,executedPlan都为懒变量,也就是说只有真正要用到的时时候才会去执行相应的代码逻辑,没有用到的时候是不会发生任何事情的。
1.4 LogicalPlan and SparkPlan
LogicalPlan和SparkPlan都继承自QueryPlan,QueryPlan为泛型类
-
abstract class QueryPlan[PlanType <: TreeNode[PlanType]] extends TreeNode[PlanType] {
-
}
-
abstract class LogicalPlan extends QueryPlan[LogicalPlan] with Logging {
-
}
-
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
-
}
以上都为抽象类,然后在此基础上又根据不同的类型衍生出不同的树节点
-
-
-
-
abstract class LeafNode extends LogicalPlan with trees.LeafNode[LogicalPlan] {
-
self: Product =>
-
}
-
-
-
-
abstract class UnaryNode extends LogicalPlan with trees.UnaryNode[LogicalPlan] {
-
self: Product =>
-
}
-
-
-
-
abstract class BinaryNode extends LogicalPlan with trees.BinaryNode[LogicalPlan] {
-
self: Product =>
-
}
-
-
private[sql] trait LeafNode extends SparkPlan with trees.LeafNode[SparkPlan] {
-
self: Product =>
-
}
-
-
private[sql] trait UnaryNode extends SparkPlan with trees.UnaryNode[SparkPlan] {
-
self: Product =>
-
}
-
-
private[sql] trait BinaryNode extends SparkPlan with trees.BinaryNode[SparkPlan] {
-
self: Product =>
-
}
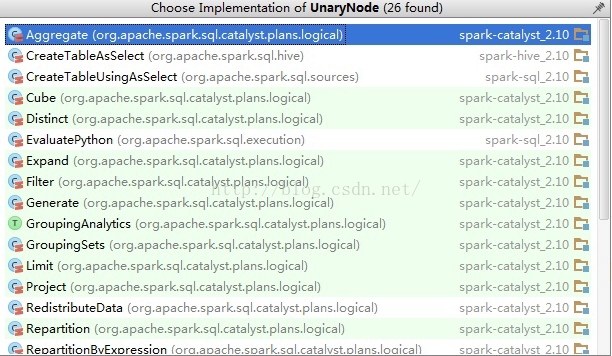
其各自真正的具体类为:
-
abstract class LeafNode extends LogicalPlan with trees.LeafNode[LogicalPlan] {
-
self: Product =>
-
}
-
abstract class UnaryNode extends LogicalPlan with trees.UnaryNode[LogicalPlan] {
-
self: Product =>
-
}
-
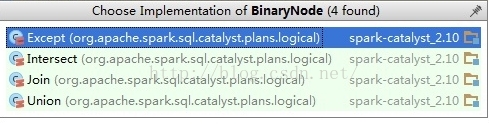
abstract class BinaryNode extends LogicalPlan with trees.BinaryNode[LogicalPlan] {
-
self: Product =>
-
}
-
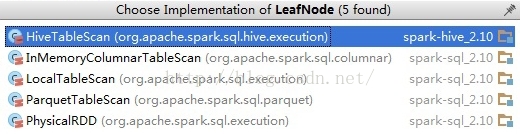
private[sql] trait LeafNode extends SparkPlan with trees.LeafNode[SparkPlan] {
-
self: Product =>
-
}
-
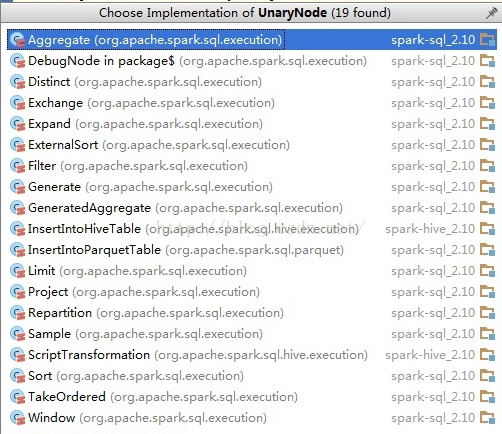
private[sql] trait UnaryNode extends SparkPlan with trees.UnaryNode[SparkPlan] {
-
self: Product =>
-
}
-
private[sql] trait BinaryNode extends SparkPlan with trees.BinaryNode[SparkPlan] {
-
self: Product =>
-
}
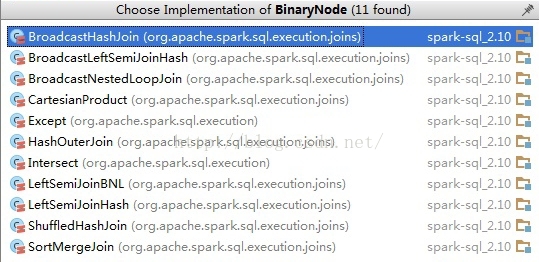 可见Spark-Sql里面二叉树结构贯穿了整个解析过程。
可见Spark-Sql里面二叉树结构贯穿了整个解析过程。
二. Catalyst
所有的SQL操作最终都通过Catalyst翻译成spark程序代码
三. SparkSQL整体架构(前端+后端)
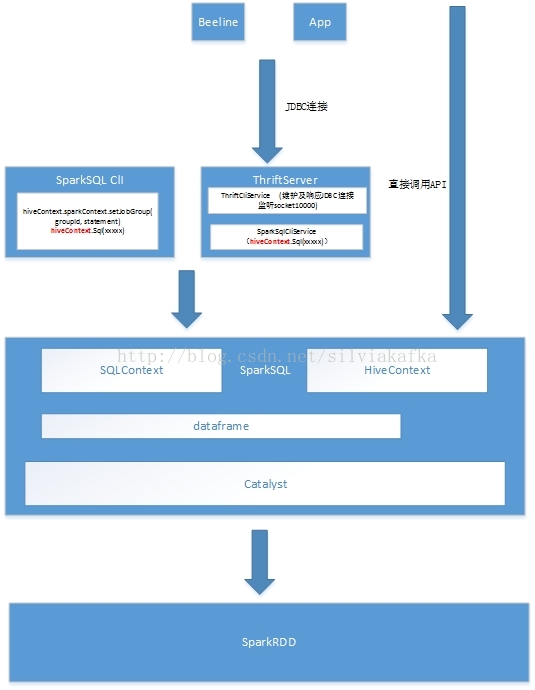
thriftserver作为一个前端,它其实只是主要分为两大块:
1.维护与用户的JDBC连接
2.通过HiveContext的API提交用户的HQL查询