Storm On YARN带来的好处
相比于将Storm部署到一个独立的集群中,Storm On YARN带来的好处很多,主要有以下几个:
- 弹性计算资源: 将Storm运行到YARN上后,Storm可与其他应用程序(比如MapReduce批处理应用程序)共享整个集群中的资源,这样,当Storm负载骤增时,可动态为它增加计算资源,而当负载减小时,可释放部分资源,从而将这些资源暂时分配给负载更重的批处理应用程序。
- 共享底层存储: Storm可与运行在YARN上的其他框架共享底层的一个HDFS存储系统,可避免多个集群带来的维护成本,同时避免数据跨集群拷贝带来的网络开销和时间延迟。
- 支持多版本: 可同时将多个Storm版本运行YARN上,避免一个版本一个集群带来的维护成本。
Storm On YARN存在的问题
由于YARN本身的不完善,导致Storm On YARN设计存在诸多缺陷,以下是几个典型问题:
- 难以将所有Storm服务运行在相邻的节点上,比如同一个机架上,这是由于YARN自身不支持资源组调度,只能实现指定一个rack,然后增量获取资源,以期望所有资源来自这个rack,但是当该rack空闲资源不足时,YARN也无能为力。
- 由于Nimbus服务运行在ApplicationMaster上,而一旦ApplicationMaster失败后,YARN会将它运行在另外一个节点上,这意味着Nimbus服务可能神不知鬼不觉的在另一个节点上启动了,这给用户使用带来诸多不便,YARN需要提供一个ApplicationMaster或Nimbus位置获取服务,客户端直接通过该服务获取Nimbus位置即可。社区目前正在推荐一个基于Zookeeper的方案,你可以使用最新开源项目Weave完成该功能。
- NodeManager本身无法支持动态升级,这意味着,如果NodeManager升级,则它上面运行的服务将全部被杀死,这将给运行在YARN上的服务带来诸多不稳定因素。如果能够将更广泛的服务,比如Web server、Mysql等,运行在YARN上,需要让NodeManager支持动态升级,像YARN的同质项目Mesos那样。
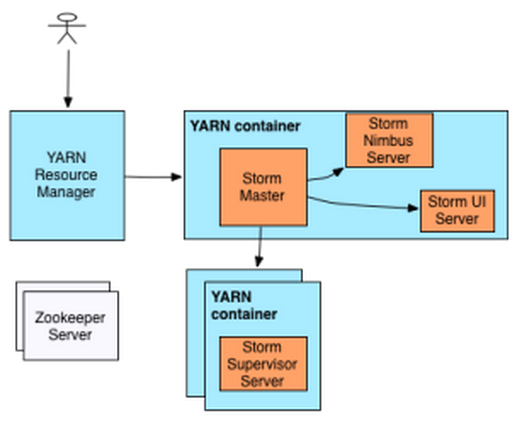
Storm On YARN架构
Storm ApplicationMaster初始化时,将在同一个Container中启动Storm Nimbus和Storm Web UI两个服务,然后根据待启动的Supervisor数目向ResourceManager申请资源,在目前实现中,ApplicationMaster将请求一个节点上所有资源然后启动Supervisor服务,也就是说,当前Supervisor将独占节点而不会与其他服务共享节点资源,这种情况下可避免其他服务对Storm集群的干扰。除了运行Storm Nimbus和Web UI外,Storm ApplicationMaster还会启动一个Thrift Server以处理来自YARN-Storm Client端的各种请求。
Launch Storm Cluster with Hadoop YARN
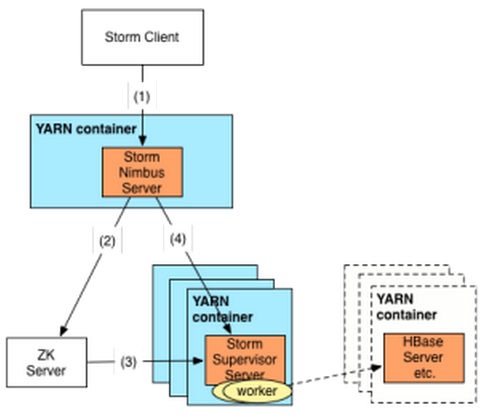
Storm-YARN asks YARN’s Resource Manager to launch a Storm Application Master. The Application Master then launches a Storm nimbus server and a Storm UI server locally. It also uses YARN to find resources for the supervisors and launch them.
Submit and Execute Storm Topologies
each Storm supervisor will launch worker processes within its container. These Storm worker processes are enabled to access Hadoop datasets stored in HDFS and HBase etc..
参考链接:http://dongxicheng.org/mapreduce-nextgen/storm-on-yarn/
参考链接:https://developer.yahoo.com/blogs/ydn/storm-yarn-released-open-source-143745133.html
下载
从github上下载storm-yarn的源码
编译
前提需要安装好JDK和Maven,解压storm-yarn-master.zip,并修改pom.xml中storm和hadoop版本
<properties> <storm.version>0.9.0</storm.version> <hadoop.version>2.5.0-cdh5.3.0</hadoop.version> </properties>
- 1
- 2
- 3
- 4
注:这里一定要注意,通过https://clojars.org/repo/storm这个repository发现storm-core和storm-netty这两个依赖库的版本只发布到了0.9.0.1,所以将storm下降到了0.9.0。
因为我这里使用的是cloudera的Hadoop,所以添加上maven的repository
<repository> <id>cdh.repo</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> <name>Cloudera Repositories</name> </repository>
- 1
- 2
- 3
- 4
- 5
使用maven编译源码
$ mvn clean package -DskipTests
- 1
部署
解压缩storm.zip,这个storm.zip是在storm-yarn-master/lib目录下,其实这个storm.zip只是一个软连接,指向的是storm-0.9.0-wip21.zip
$ unzip storm.zip
- 1
配置storm-yarn-master和storm-0.9.0-wip21的bin到系统的环境变量中
# STORM_YARN_HOME export STORM_YARN_HOME=/home/hadoop/compile/storm-yarn-master export PATH=$PATH:$STORM_YARN_HOME/bin:$STORM_YARN_HOME/lib/storm-0.9.0-wip21/bin
- 1
- 2
- 3
记得使配置的环境变量生效
$ source /etc/profile
- 1
添加Storm工程需要的额外Jar包到storm-0.9.0-wip21的lib下,比如MySQL的驱动jar包之类的,重新压缩成storm.zip文件,上传至HDFS的指定目录中(非常重要,集群中通过访问hdfs中的storm.zip获取工作环境) ,进入【/home/hadoop/compile/storm-yarn-master/lib】目录下
$ zip -r storm.zip storm-0.9.0-wip21 $ hdfs dfs -mkdir -p /lib/storm/0.9.0-wip21/ $ hdfs dfs -put storm.zip /lib/storm/0.9.0-wip21/
- 1
- 2
- 3
运行
修改【/opt/modules/storm-yarn-master/lib/storm-0.9.0-wip21/conf】目录下的storm.yaml,这里只修改了zookeeper的地址:
storm.zookeeper.servers: - "hadoop-yarn01.dimensoft.com.cn" - "hadoop-yarn02.dimensoft.com.cn" - "hadoop-yarn03.dimensoft.com.cn"
- 1
- 2
- 3
- 4
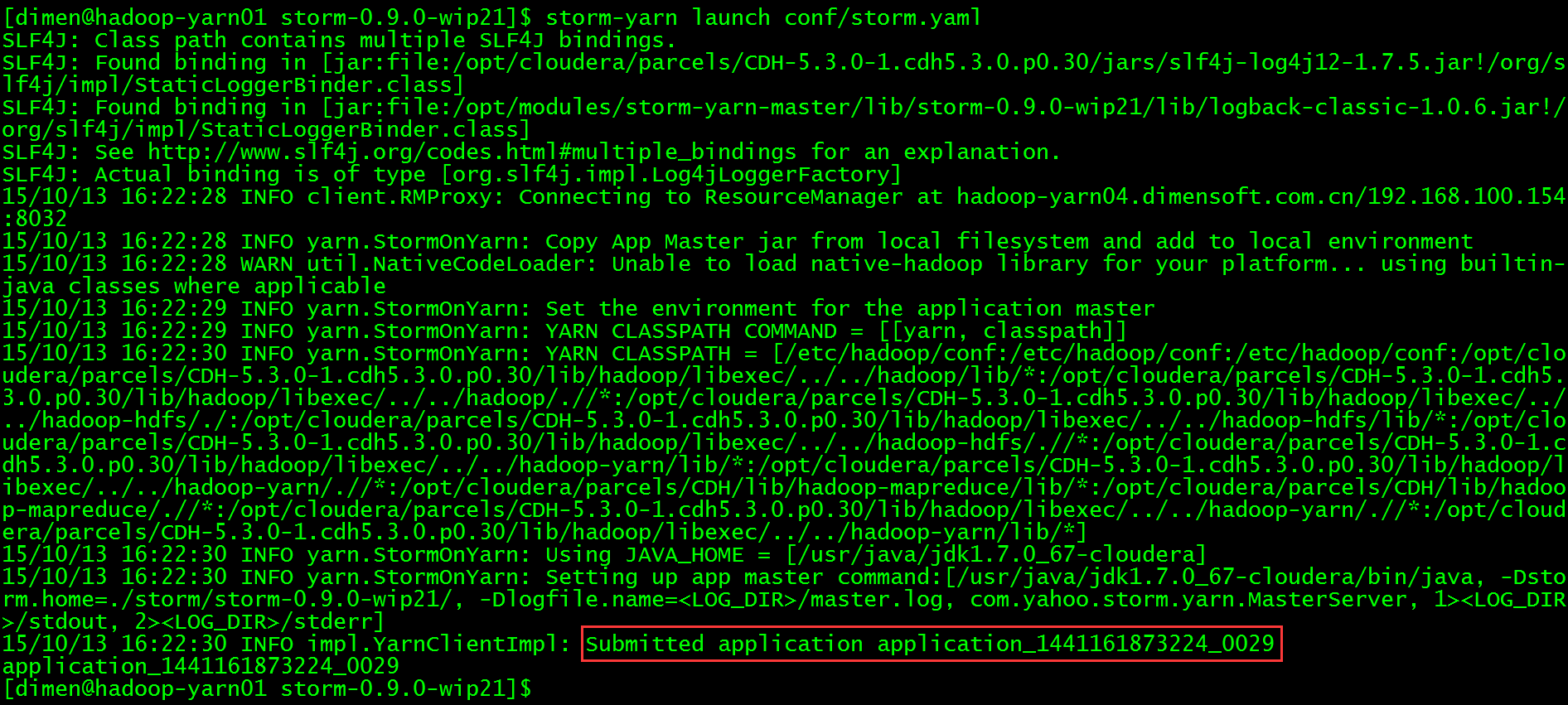
提交storm到yarn
$ storm-yarn launch conf/storm.yaml
- 1
通过YARN的界面查看,作业执行报错:
15/10/13 16:22:34 ERROR auth.ThriftServer: ThriftServer is being stopped due to: org.apache.thrift7.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9000. org.apache.thrift7.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9000. at org.apache.thrift7.transport.TNonblockingServerSocket.<init>(TNonblockingServerSocket.java:89) at org.apache.thrift7.transport.TNonblockingServerSocket.<init>(TNonblockingServerSocket.java:68) at org.apache.thrift7.transport.TNonblockingServerSocket.<init>(TNonblockingServerSocket.java:61) at backtype.storm.security.auth.SimpleTransportPlugin.getServer(SimpleTransportPlugin.java:47) at backtype.storm.security.auth.ThriftServer.serve(ThriftServer.java:52) at com.yahoo.storm.yarn.MasterServer.main(MasterServer.java:175)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这是因为部署storm-yarn的节点运行了CM Server和CM Server db,导致9000端口号已经被占用了,Storm ApplicationMaster初始化时,将在同一个Container中启动Storm Nimbus和Storm Web UI两个服务,然后根据待启动的Supervisor数目向ResourceManager申请资源,在目前实现中,ApplicationMaster将请求一个节点上所有资源然后启动Supervisor服务,也就是说,当前Supervisor将独占节点而不会与其他服务共享节点资源,这种情况下可避免其他服务对Storm集群的干扰。 除了运行Storm Nimbus和Web UI外,Storm ApplicationMaster还会启动一个Thrift Server以处理来自YARN-Storm Client端的各种请求,在此不再赘述。直接在storm.yaml中添加配置修改thrift端口号。
master.thrift.port: 9002
- 1
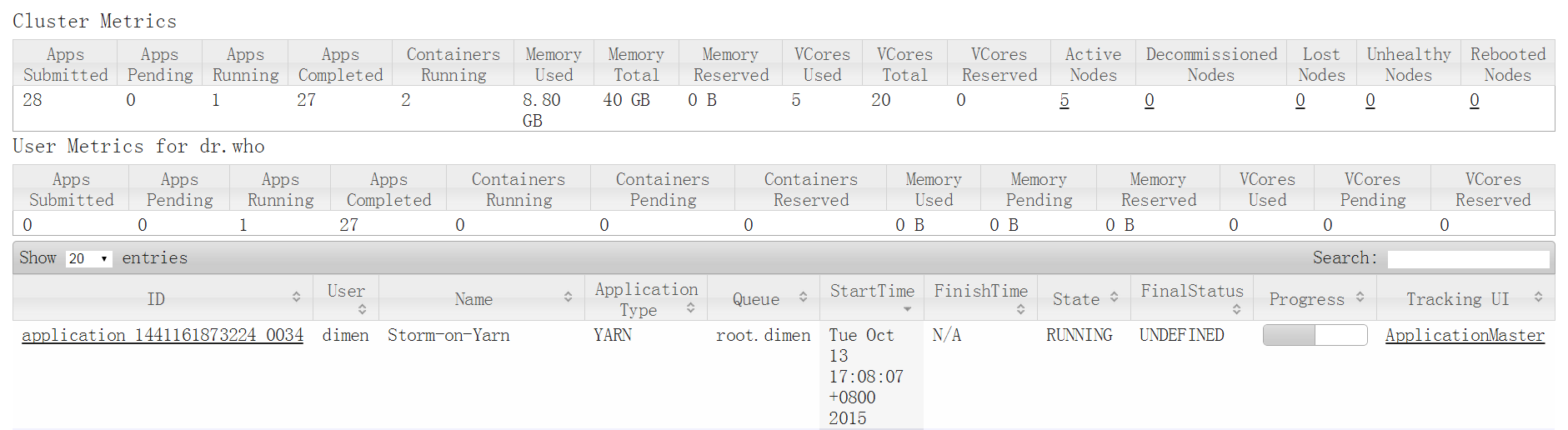
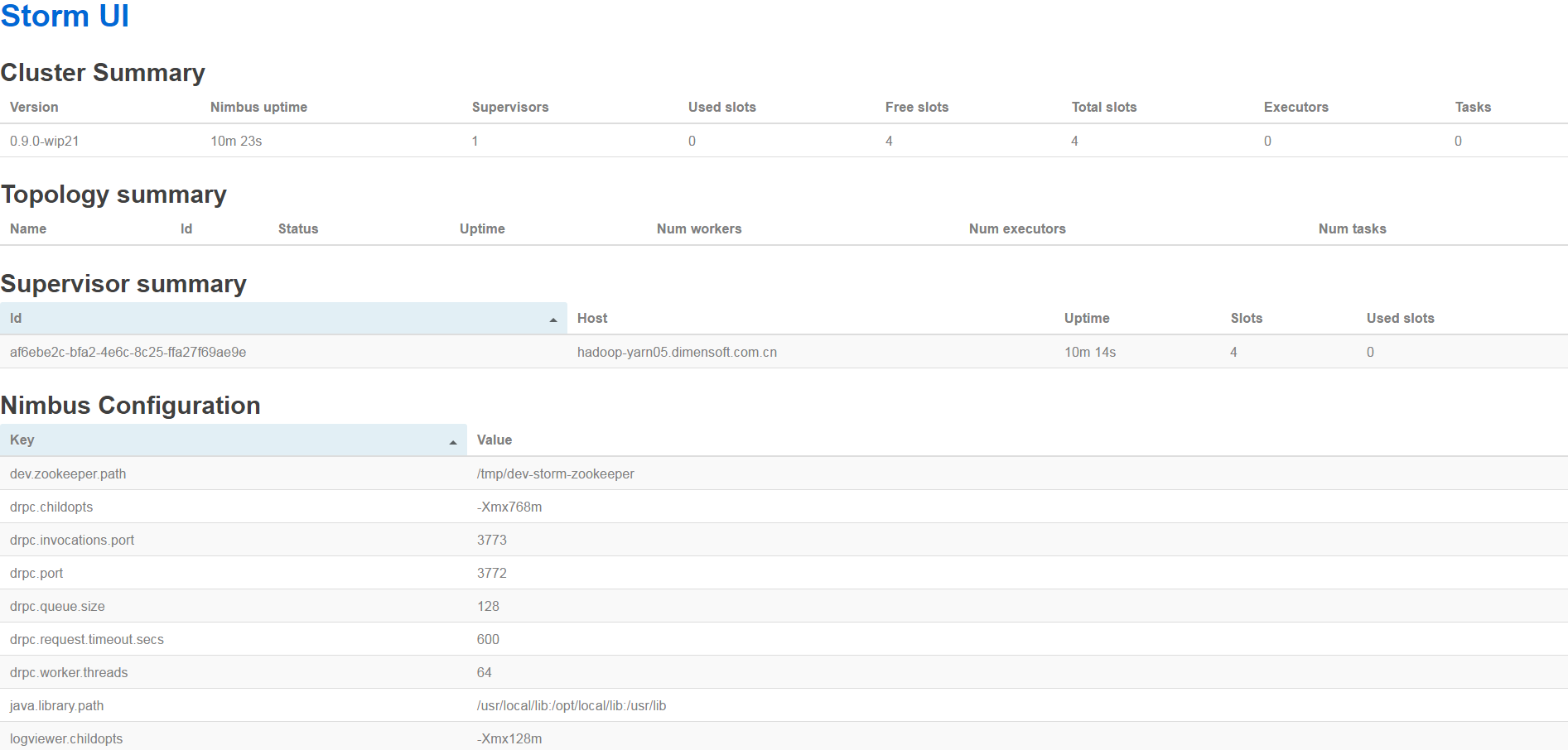
再次提交一遍成功,查看YARN Web UI
直接通过YARN的Web UI查看该job在哪个节点运行,该节点就是Storm集群的UI节点,例如:192.168.100.154节点,那么Storm的UI就是
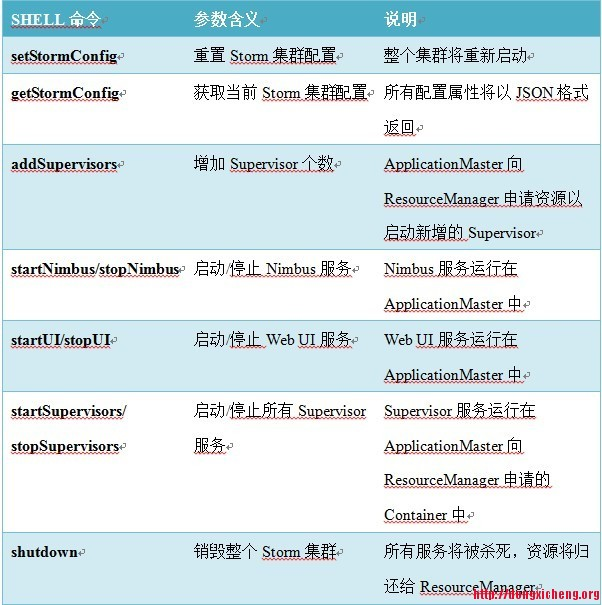
可以使用的command
$ storm-yarn [command] –appId [appId] –output [file] [–supervisors [n]]
- 1
其中,Command为具体命令,具体见下表,参数“-appId”为启动的Storm的应用程序Id,“-supervisors”为需增加的Supervisor服务个数,该参数只对命令“addSupervisors”有效