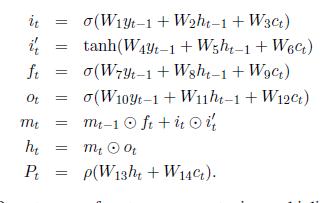整体流程与第一篇差不多,只是在encoder和decoder加入了RNN
Encoder:
1.

ai=xi+li
ai=词向量+词在序列中的位置信息(相当于一个权重,[M, 1])
流程:
先是CNN获取位置信息,然后再加上词向量,然后再通过LSTM
2.
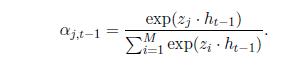
常见的求注意力权重的方法
a. ht-1:RNN输出
流程:
通过LSTM进行编码,然后再求attention
3.

注意力累加
Decoder:
流程:
经过LSTM进行解码,然后再乘以个[cell_output_size, vocab_size]矩阵(这里是考虑依赖词库),如果不依赖词库则乘以[cell_output_size, sequence_size](依赖输入长度)
本文介绍了两种Decoder,均用到了LSTM,最后输出的是K个最大词的概率,求概率求的是对整个词库分配概率,如果生成词时依赖词库,输出长度[V,1],V表示词库大小;依赖输入句子,那么就是对整个输入句子的每个词分配概率,输出[M,1],M表示词的长度
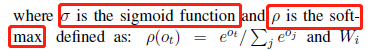
1.
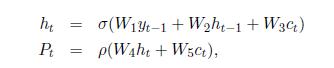
2.