Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
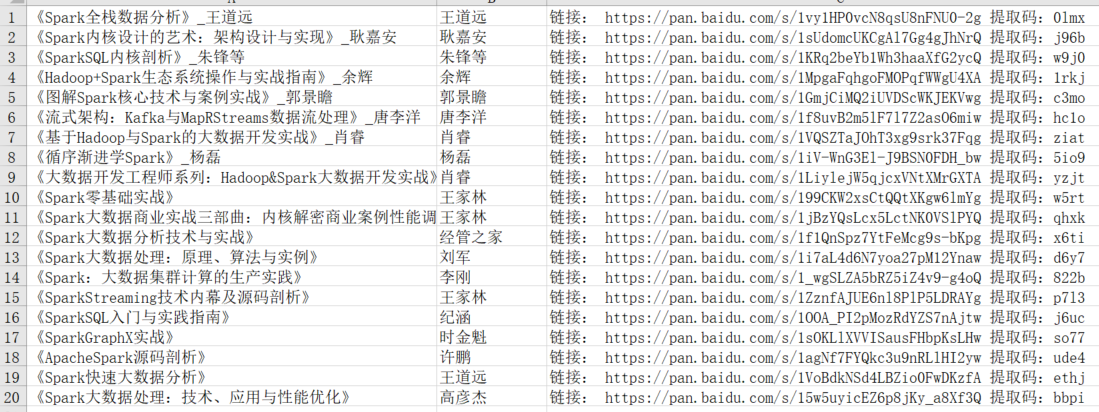
《Spark全栈数据分析》_王道远 1vy1HP0vcN8qsU8nFNU0-2g 0lmx
《Spark内核设计的艺术:架构设计与实现》_耿嘉安 1sUdomcUKCgAl7Gg4gJhNrQ j96b
《SparkSQL内核剖析》_朱锋等 1KRq2beYb1Wh3haaXfG2ycQ w9j0
《Hadoop+Spark生态系统操作与实战指南》_余辉 1MpgaFqhgoFMOPqfWWgU4XA 1rkj
《图解Spark核心技术与案例实战》_郭景瞻 1GmjCiMQ2iUVDScWKJEKVwg c3mo
《流式架构:Kafka与MapRStreams数据流处理》_唐李洋 1f8uvB2m5lF7l7Z2asO6miw hc1o
《基于Hadoop与Spark的大数据开发实战》_肖睿 1VQSZTaJOhT3xg9srk37Fqg ziat
《循序渐进学Spark》_杨磊 1iV-WnG3El-J9BSN0FDH_bw 5io9
《大数据开发工程师系列:Hadoop&Spark大数据开发实战》 1LiylejW5qjcxVNtXMrGXTA yzjt
《Spark零基础实战》 199CKW2xsCtQQtXKgw6lmYg w5rt
《Spark大数据商业实战三部曲:内核解密商业案例性能调优》 1jBzYQsLcx5LctNK0VSlPYQ qhxk
《Spark大数据分析技术与实战》 1f1QnSpz7YtFeMcg9s-bKpg x6ti
《Spark大数据处理:原理、算法与实例》 1i7aL4d6N7yoa27pM12Ynaw d6y7
《Spark:大数据集群计算的生产实践》 1_wgSLZA5bRZ5iZ4v9-g4oQ 822b
《SparkStreaming技术内幕及源码剖析》 1ZznfAJUE6nl8PlP5LDRAYg p7l3
《SparkSQL入门与实践指南》 1OOA_PI2pMozRdYZS7nAjtw j6uc
《SparkGraphX实战》 1sOKLlXVVISausFHbpKsLHw so77
《ApacheSpark源码剖析》 1agNf7FYQkc3u9nRLlHI2yw ude4
《Spark快速大数据分析》 1VoBdkNSd4LBZio0FwDKzfA ethj
《Spark大数据处理:技术、应用与性能优化》 15w5uyicEZ6p8jKy_a8Xf3Q bbpi