Data-types-and-missing-values
教程
Dtypes
DataFrame或Series中列的数据类型称为dtype。
您可以使用dtype属性来获取特定列的类型。 例如,我们可以在review的DataFrame中获得价格列的dtype:
reviews.price.dtype
另外,dtypes属性返回DataFrame中每一列的dtype:
reviews.dtypes
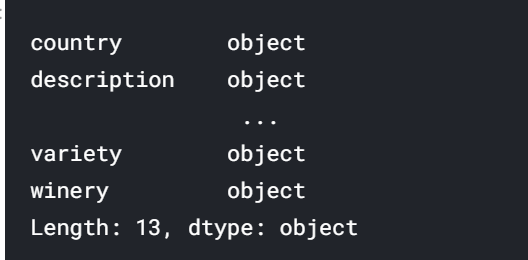
数据类型告诉我们有关pandas如何在内部存储数据的信息。 float64表示它使用的是64位浮点数。 int64表示大小类似的整数,依此类推。
需要牢记的一个独特之处(在这里非常清楚地显示)是,完全由字符串组成的列没有自己的类型; 相反,它们被赋予对象类型。
只要使用astype()函数,只要有这种转换意义,就可以将一种类型的列转换为另一种类型。 例如,我们可以将points列从其现有的int64数据类型转换为float64数据类型。
reviews.points.astype('float64')
Missing data
缺少值的条目将被赋予值NaN,是“非数字”的缩写。 出于技术原因,这些NaN值始终为float64 dtype。
熊猫提供了一些针对丢失数据的方法。 要选择NaN条目,可以使用pd.isnull()(或其配套的pd.notnull())。 这意味着可以这样使用:
reviews[pd.isnull(reviews.country)]
替换缺失值是常见的操作。 Pandas为这个问题提供了一个非常方便的方法:fillna()。 fillna()提供了几种缓解此类数据的策略。 例如,我们可以简单地将每个NaN替换为“未知”:替换缺失值是常见的操作。 Pandas为这个问题提供了一个非常方便的方法:fillna()。 fillna()提供了几种缓解此类数据的策略。 例如,我们可以简单地将每个NaN替换为“未知”
练习
1.
What is the data type of the `points` column in the dataset?
# Your code here dtype = reviews.points.dtype # Check your answer q1.check()
2.
Create a Series from entries in the points column, but convert the entries to strings. Hint: strings are str in native Python.
point_strings =reviews.points.astype('str') # Check your answer q2.check()
3.
Sometimes the price column is null. How many reviews in the dataset are missing a price?
missing_price_reviews = reviews[reviews.price.isnull()] n_missing_prices = len(missing_price_reviews) # print(n_missing_prices) # Check your answer q3.check()
4.
What are the most common wine-producing regions? Create a Series counting the number of times each value occurs in the region_1 field. This field is often missing data, so replace missing values with Unknown. Sort in descending order. Your output should look something like this:
tmp=reviews.region_1.fillna("Unknown") reviews_per_region = reviews.fillna("Unknown").region_1.value_counts().sort_values(ascending=False) print(reviews_per_region) # Check your answer q4.check()