关于MySQL可重复读的理解
(一) 问题引入
描述问题之前,先理解一下两种锁的概念。
共享锁(S锁):如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
排它锁(X锁):如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
共享锁和排他锁都属于悲观锁。排他锁又可以可以分为行锁和表锁。
MySQL常用的两种引擎MyISAM和InnoDB,MyISAM默认使用表锁,InnoDB默认使用行锁。
注意:使用InnoDB引擎,如果筛选条件里面没有索引字段,就会锁住整张表,否则的话,锁住相应的行。
开启两个session,每个session关闭autocommit,select的时候使用lock in share mode 或者 for update,感兴趣的读者可以自行验证。
言归正传,那么问题来了:
一个事务(事务T)要更新一行,如果刚好有另外一个事务(事务T2)拥有这一行的行锁,事务T就会被锁住,进入等待状态。那么等到事务T2释放行锁,事务T获得行锁,要更新数据的时候,它读到的值是什么呢?
(二) 过程详解
2.1准备阶段
1 CREATE TABLE `t` ( 2 `id` int(11) NOT NULL, 3 `k` int(11) DEFAULT NULL, 4 PRIMARY KEY (`id`) 5 ) ENGINE=InnoDB; 6 insert into t(id, k) values(1,1),(2,2);

注意:事务的启动时机。
begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作InnoDB表语句的时候,事务才真正启动。
如果想马上启动一个事务,可以使用start transaction with consistent snapshot 命令。
在上面的例子里面,事务C没有显示地使用begin/commit,表示这个update语句本身就是一个事务,事务完成的时候会自动提交。事务B在更新了之后查询;事务A在一个只读事务中查询,查询时间是在事务B的查询之后。
2.2 视图在MySQL中的应用
一个是view。view基于 SQL 语句的结果集的可视化的表,创建视图的语法是create view …,而它的查询方法与查询表一样。
另一个是InnoDB在实现MVCC时用到的一致性读视图,即consistent read view,用于支持RC(Read Committed)和RR(Repeatable Read)隔离级别的实现。
2.3 快照在MVCC里是怎样工作的?
在可重复读隔离级别下,事务在启动的时候就拍了快照,同时生成一致性视图(read_view)。注意:这个快照是基于整库的,快照就是开启事务当时的整个库的数据,每一行数据都基于事务id有多个不同的版本。如果在读已提交隔离级别下,快照会在每一次sql执行前重新生成,一致性视图(read_view)也会重新生成,就会导致不可重复读的问题。
InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id。它是在事务开始的时候向InnoDB 的事务系统申请的,是按申请顺序严格递增的。
而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。
也就是说,数据表中的一行记录,其实可能有多个版本 (row),每个版本有自己的 row trx_id。
下图就是一个记录被多个事务连续更新后的状态。

图中虚线框里是同一行数据的 4 个版本,当前最新版本是 V4,k 的值是 22,它是被 transaction id 为25的事务更新的,因此它的row trx_id也是25。
语句更新会生成undo log(回滚日志)。
实际上,上图中的三个虚线箭头,就是 undo log;而V1、V2、V3 并不是物理上真实存在的,而是每次需要的时候根据当前版本和 undo log 计算出来的。比如,需要V2 的时候,就是通过 V4 依次执行 U3、U2 算出来。
按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。因此,一个事务只需要在启动的时候声明说,“以我启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后才生成的,我就不认,我必须要找到它的上一个版本”。当然,如果“上一个版本”也不可见,那就得继续往前找。还有,如果是这个事务自己更新的数据,它自己还是要认的。
在实现上, InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID。活跃”指的就是,启动了但还没提交。 数组里面事务ID的最小值记为低水位,当前系统里面已经创建过的事务ID的最大值加1记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
数据版本的可见性规则,就是基于数据的row trx_id和这个一致性视图的对比结果得到的。这个视图数组把所有的 row trx_id 分成了几种不同的情况。
这样,对于当前事务的启动瞬间来说,一个数据版本的row trx_id,有以下几种可能:
如果落在绿色部分,表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的。
如果落在红色部分,表示这个版本是由将来启动的事务生成的,肯定是不可见的。
如果落在黄色部分,那就包括两种情况:
1.若 row trx_id 在数组中,表示这个版本是由还没提交的事务生成的,不可见。
2.若 row trx_id 不在数组中,表示这个版本是由已经提交的事务生成的,可见。
下面,我们分析一下图1中的三个事务,分析一下事务A的返回结果
这里,我们作如下假设:
a)事务A开始之前,系统里只有一个活跃事务ID是99;
b) 事务A、B、C的版本分别是100、101、102,且当前系统只有这四个事务;
c) 三个事务开始之前,(1,1)这一行的数据的row trx_id是90;
如图4所示,分析事务A的结果
从图4可以看到,第一个有效更新是事务C,把数据从(1,1)改成了(1,2)。此时,这个数据最新版本的row trx_id是102,90成了这个数据的历史版本。第二个有效更新是事务B,把数据从(1,2)改成了(1,3)。此时,这个数据最新版本的row trx_id是101,102成了这个数据的历史版本。事务A查询的时候,事务B还没有提交,但是它生成的(1,3)这个版本已经变成当前版本了。但是事务A对这个版本必须是不可见的,否则就变成脏读(Read Uncommited)了。
现在事务A要来读取数据了,它的视图数组是[99,100]。有一点必须要确定的是,读数据都是从当前版本读起的。事务A读取数据的流程具体如下:
找到(1,3)的时候,判断出row trx_id=101,比高水位大,处于红色区域,不可见。
继续找,找到上一个历史版本,一看row trx_id=102,比高水位大,处于红色区域,不可见。
再往前找,找到了(1,1),它的row trx_id=90,比低水位小,处于绿色区域,可见。
这样执行下来,虽然期间这一行数据被改过,但是事务A不论在什么时候查询,看到的这行数据的结果都是一致的,所以称之为一致性读。
简单总结一下,一个数据版本,对于一个事务视图来说,除了自己的更新总是可见以外,还有以下三种情况:
a) 版本未提交,不可见
b) 版本已提交,但是在视图创建后提交的,不可见
c) 版本已提交,并且是在视图创建之前提交的,可见
根据以上三种情况,判断图4中的查询结果,事务A的查询语句的视图数组是在事务A启动的时候生成的,此时:
(1,3)还没提交,属于情况a,不可见
(1,2)虽然提交了,却是在视图创建后提交的,属于情况b,不可见
(1,1)是在视图创建之前提交的,可见
综上,事务A查询出来的结果是1。
2.4 更新逻辑

如图5所示,事务B的视图数组生成早于事务C的提交,为什么还能看见(1,2),之后又计算出(1,3)呢?
假设事务B在更新之前查询的话,这个结果是多少呢?按照之前的一致性读的规则,结果是1,当然这个结果是没错的。
有一点,需要清楚,当它去更新数据的时候,就不能在历史版本上更新了,否则事务C的更新就会丢失。所以,事务B的
set k = k + 1是在(1,2)的基础上进行操作的。这里用到一条规则:更新数据都是先读后写的,而这个读,只能读当前的值,称为当前读(current read)。
因此,在更新的时候,当前读拿到的数据是 (1,2),更新后生了新版本的数据 (1,3),这个新版本的 row trx_id是101。所以,执行事务 B 查询语句的时候,一看自己的版本号是101,最新数据的版本号也是 101,是自己的更新,可以直接使用,故查询到的k的值是3。
select操作如果加锁,也是当前读,就是问题导入介绍的共享锁和排他锁。
1 select k from t where id=1 lock in share mode; 2 select k from t where id=1 for update;
不放多想一些情况,假设事务C不是马上提交,变成了下面的C’,执行的结果会是怎么样呢?

事务 C’的不同是,更新后并没有马上提交,在它提交前,事务B 的更新语句先发起了。前面说过了,虽然事务 C’还没提交,
但是 (1,2) 这个版本也已经生成了,并且是当前的最新版本。那么,事务 B 的更新语句会怎么处理呢?
首先呢?这里阐述一下,什么是两阶段锁协议?(下面会用到)
两阶段锁协议:是指所有的事务必须分两个阶段对数据项加锁和解锁。即事务分两个阶段,第一个阶段是获得锁。事务可以获得任何数据项上的任何类型的锁,但是不能释放;第二阶段是释放锁,事务可以释放任何数据项上的任何类型的锁,但不能申请。
第一阶段是获得封锁的阶段,称为扩展阶段:其实也就是该阶段可以进入加锁操作,在对任何数据进行读操作之前要申请获得S锁,在进行写操作之前要申请并获得X锁,加锁不成功,则事务进入等待状态,直到加锁成功才继续执行。就是加锁后就不能解锁了。
第二阶段是释放封锁的阶段,称为收缩阶段:当事务释放一个封锁后,事务进入封锁阶段,在该阶段只能进行解锁而不能再进行加锁操作。
所以事务都是提交或回滚才能释放锁,在事务中,只能获取锁而不能释放锁。
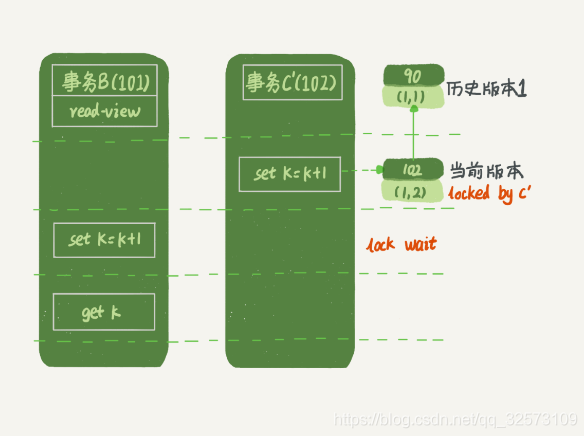
事务 C’没提交,也就是说 (1,2) 这个版本上的写锁还没释放,而事务B是当前读,必须要读取最新版本,而且必须加锁,于是就被锁住了,事务b必须等待,必须等到事务C’提交后释放这个锁,才能继续它的当前读。到这里,就把一致性读,当前读和行锁串联起来了。
2.5 事务的可重复读是怎么实现的?
可重复读的核心是一致性读;事务更新数据的时候,只能用当前读。如果当前记录的行锁被其他事务占用的话,就需要进入锁等待。
简单介绍一下读提交的逻辑,读提交的逻辑与可重复读的逻辑类似,主要的区别如下:
在可重复读隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都共用这个一致性视图
在读提交隔离级别下,每一个语句执行前都会重新算出一个新的视图
那么,我们再看一下,在读提交隔离级别下,事务A和事务B查询到的K,分别是多少呢?
事务A查询语句的视图数组是在执行这个语句的时候创建的,时序上(1,2),(1,3)的生成时间都在创建这个视图数组的时刻之前。
此时:
(1,3) 还没提交,属于情况a,不可见
(1,2)提交了,属于情况c,可见
所以,此时事务A查询语句返回的结果是k=2。
显然,事务B查询语句返回的结果是k=3。
(三) 总结
InnoDB 的行数据有多个版本,每个数据版本有自己的row trx_id,每个事务或者语句有自己的一致性视图。普通查询语句是一致性读,一致性读会根据 row trx_id和一致性视图确定数据版本的可见性。
对于可重复读,查询只承认在事务启动前就已经提交完成的数据
对于读提交,查询只承认在查询语句启动前就已经提交完成的数据
而当前读,总是读取已经提交完成的最新版本
转载:https://blog.csdn.net/qq_32573109/article/details/98610368