java中数组在内存空间中连续的,可以通过内存地址迅速获得该元素。数组的实现可以使得printList以线性时间被执行,而findKth操作则花费常数时间,这正是
我们所能够预期的。不过,插入和删除的花费却潜藏着昂贵的开销,这是要插入发生的位置。最坏的情况下,在位置0的插入首先需要将整个数组后一个位置以空间来,而删除第一个元素需要将表中的所有元素前移一个位置,因此这两种最坏的情况为O(N);平均来看,这两种操作都需要移动表的一半的元素,因此任然需要线性时间。另一方面,如果所有的操作都发生在表的高端,那就没有元素的移动,而添加和删除则只花费O(1)时间.
为了避免插入和删除的线性开销,我们需要保证表可以不连续存储,否则表的每个部分都可能需要整体移动。下图指出链表的基本想法:
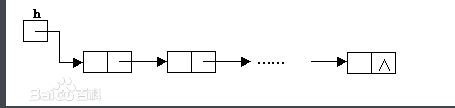
链表由一系列节点组成,这些节点不必在内存中相连。每一个节点均含有表元素和到包含该元素后继元素的节点的链(link).我们称之为next链。最后一个单元的next链引用为
null.(单向链表).为了执行printList或find(x),只要从表的第一个节点开始然后用一些后继的next链遍历该表即可。这种操作显然是线性时间的,和数组实现时一样,不过其中的常数可能会比用实现时要大。findKth操作不如数组实现时的效率高;findKth(i)花费O(i)的时间并以这种明显方式遍历链表而完成。
我们看到,在实践中如果知道变动将要发生的地方,那么向链表插入或从链表中删除一项的操作不需要移动很多的项,而只涉及常数个节点链的该表。