因为:
- 数据库出现瓶颈,系统的吞吐量出现访问速度慢
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间变长
- 数据读写速度缓慢
就是咱们说的“性能问题”,程序员一遇到它总是焦头烂额!
优化
- like 前导符优化
like模糊查询形如'%AAA%'和'%AAA'将不会使用索引,但是业务上不可避免可能又需要使用到这种形式。
通常的方法有两种:
优化方案一:
使用覆盖索引,即查询出的列只是用索引就可以获取,而无须查询表记录,这样也走了索引;
优化方案二:
使用locate函数或者position函数代替like查询:如table.field like '%AAA%'可以改为locate('AAA', table.field) > 0或POSITION('AAA' IN table.field)>0
- in 和 exist
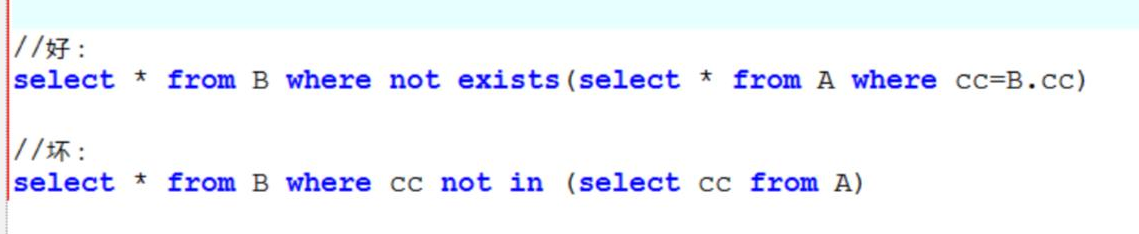
如果查询的两个表大小相当,那么用in和exists差别不大。 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in: 例如:表A(小表),表B(大表)
示例一:

示例二:

- 如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not exist 的子查询依然能用到表上的索引。所以无论哪个表大,用not exists都比not in要快!
- 子查询优化
-
1、MySQL 5.6 之前的版本对子查询处理:不会将查询的结果集计算出来用作与其他表做join,outer表每扫描一条数据,子查询都会被重新执行一遍。
-
2、MySQL 5.6 对子查询的处理 :将子查询的结果集 cache 到临时表里,临时表索引主要用来移除重复记录,并且随后也可能用于做join查询,这种技术在 5.6 中叫做物化的子查询,物化子查询可以看到select_type字段为subquery,而在 5.5 里为DEPENDENT SUBQUERY。
-
3、子查询一般都可以改成表的关联查询,子查询会有临时表的创建、销毁,效率低下。
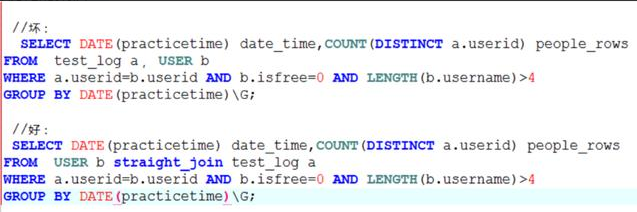
- straight_join
mysql hint:
Mysql 优化器在处理多表的关联的时候,很有可能会选择错误的驱动表进行关联,导致了关联次数的增加,从而使得sql语句执行变得非常的缓慢。
这个时候需要有经验的DBA进行判断,选择正确的驱动表,这个时候 straightjoin 就起了作用了,下面我们来看一看使用straight_join进行优化的案例:
尝试采用user表做驱动表,使用straight_join强制连接顺序:
- 高效分页
传统分页
select * from table limit 10000,10
limit原理
(1) Limit 10000,10(2)偏移量越大则越慢
推荐分页

7. 复杂关联sql的优化
-
1、首先查询返回的结果集,通常查询返回的结果集很少,是有优化的空间的。
-
2、通过查看执行计划,查看优化器选择的驱动表,从执行计划的rows可以大致反应出问题的所在。
-
3、搞清各表的关联关系,查看关联字段是否有合适的索引。
-
4、使用straight_join关键词来强制调整驱动表的选择,对优化的想法进行验证。
-
5、如果条件允许,对复杂的SQL进行拆分。尽可能越简单越好。
8. force index
有时优化器可能由于统计信息不准确等原因,没有选择最优的执行计划,可以人为改变mysql的执行计划,例如:

9. count的优化
按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(*),所以我建议你,尽量使用count(*)。
10. 总结
MySQL 性能优化 最主要是理解 innodb 的索引原理及结构及 SQL 的执行计划,在不断累积经验的基础上熟能生巧。
性能提升之force index()
force index() 方法强制使用这个索引
出现这个问题的原因在于 MySQL 每次查询只能使用一个索引, 而你的 SQL 语句 WHERE 条件和 ORDER BY 的条件不一样, 索引没建好的话, 那么 ORDER BY 就使用不到索引, 出现了 Using filesort 问题。
解决这个问题就是建立一个包含 WHERE 和 ORDER BY 条件的混合索引。
比如原来 SQL 语句是:
SELECT * FROM user u where u.id=100 order by u.update_time
而索引是 idx_user_id(id)
现在重新建立索引为 idx_user_id_update_time(id,update_time)
再使用 explain 命令查看, 如果 key 使用的是上述新建的 idx_user_id_update_time 索引, 则可以看到 Using file sort 问题消失了, 如果 key 不是使用新建 idx_user_id_update_time 索引, 可以使用 force index() 方法强制使用这个索引, 此时 using filesort 问题就解决了。
force index()使用方式:
SELECT * FROM user u force index(idx_user_id_update_time) where u.id=100 order by u.update_time
性能提升之STRAIGHT_JOIN
STRAIGHT_JOIN,在数据量大的联表查询中灵活运用的话,能大大缩短查询时间。
首先来解释下STRAIGHT_JOIN到底是用做什么的:
STRAIGHT_JOIN is similar to JOIN, except that the left table is always read before the right table.
This can be used for those (few) cases for which the join optimizer puts the tables in the wrong order.
意思就是说STRAIGHT_JOIN功能同join类似,但能让左边的表来驱动右边的表,能改表优化器对于联表查询的执行顺序。
接下来我们举个例子进行大致的分析:
select t1.*
from Table1 t1
inner join Table2 t2
on t1.CommonID = t2.CommonID
where t1.FilterID = 1
以上sql大数据量下执行需要30s,是不是很奇怪?明明Table1表的FilterID字段建了索引啊,Table1和Table2的CommonID也建了索引啊。通过explain来分析,你会发现执行计划中表的执行顺序是Table2->Table1。
这个时候要略微介绍下驱动表的概念,mysql中指定了连接条件时,满足查询条件的记录行数少的表为驱动表;如未指定查询条件,则扫描行数少的为驱动表。mysql优化器就是这么粗暴以小表驱动大表的方式来决定执行顺序的。
但如下sql的执行时间都少于1s:
select t1.*
from Table1 t1
where t1.FilterID = 1
或
select t1.*
from Table1 t1
inner join Table2 t2
on t1.CommonID = t2.CommonID
这个时候STRAIGHT_JOIN就派上用场,我们对sql进行改造如下:
select t1.*
from Table1 t1
STRAIGHT_JOIN Table2 t2
on t1.CommonID = t2.CommonID
where t1.FilterID = 1
用explain进行分析,发现执行顺序为Table1->Table2,这时就由Table1来作为驱动表了,Table1中相应的索引也就用上了,执行时间竟然低于1s了。
分析到这里,必须要重点说下:
- STRAIGHT_JOIN只适用于inner join,并不使用与left join,right join。(因为left join,right join已经代表指定了表的执行顺序)
- 尽可能让优化器去判断,因为大部分情况下mysql优化器是比人要聪明的。使用STRAIGHT_JOIN一定要慎重,因为啊部分情况下认为指定的执行顺序并不一定会比优化引擎要靠谱。
区分in和exists, not in和not exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。如何高效的写出一个替代not exists的sql语句?
避免在 where 子句中对字段进行 null 值判断
对于null的判断会导致引擎放弃使用索引而进行全表扫描。
避免在where子句中对字段进行表达式操作
比如
select user_id,user_project from user_base where age*2=36;
中对字段就行了算术运算,这会造成引擎放弃使用索引,建议改成
select user_id,user_project from user_base where age=36/2;
注意范围查询语句
对于联合索引来说,如果存在范围查询,比如between,>,<等条件时,会造成后面的索引字段失效。
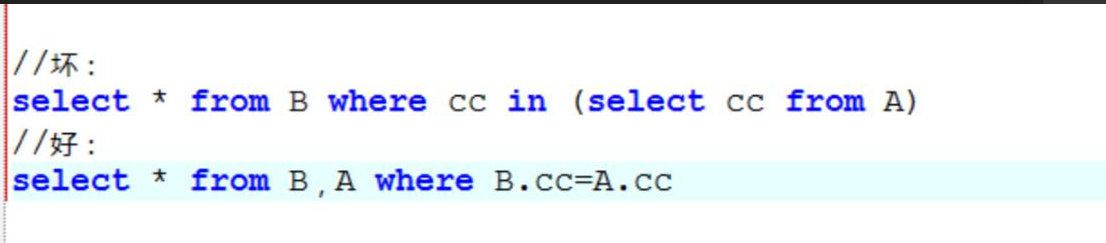
关于JOIN优化
注意:MySQL中没有full join,可以用以下方式来解决
select * from A left join B on B.name = A.name
where B.name is null
union all
select * from B;
尽量使用inner join,避免left join
参与联合查询的表至少为2张表,一般都存在大小之分。如果连接方式是inner join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表,但是left join在驱动表的选择上遵循的是左边驱动右边的原则,即left join左边的表名为驱动表。
合理利用索引
被驱动表的索引字段作为on的限制字段。
利用小表去驱动大表
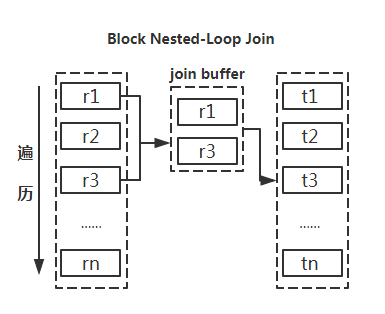
从原理图能够直观的看出如果能够减少驱动表的话,减少嵌套循环中的循环次数,以减少 IO总量及CPU运算的次数。
巧用STRAIGHT_JOIN
inner join是由mysql选择驱动表,但是有些特殊情况需要选择另个表作为驱动表,比如有group by、order by等「Using filesort」、「Using temporary」时。STRAIGHT_JOIN来强制连接顺序,在STRAIGHT_JOIN左边的表名就是驱动表,右边则是被驱动表。在使用STRAIGHT_JOIN有个前提条件是该查询是内连接,也就是inner join。其他链接不推荐使用STRAIGHT_JOIN,否则可能造成查询结果不准确。
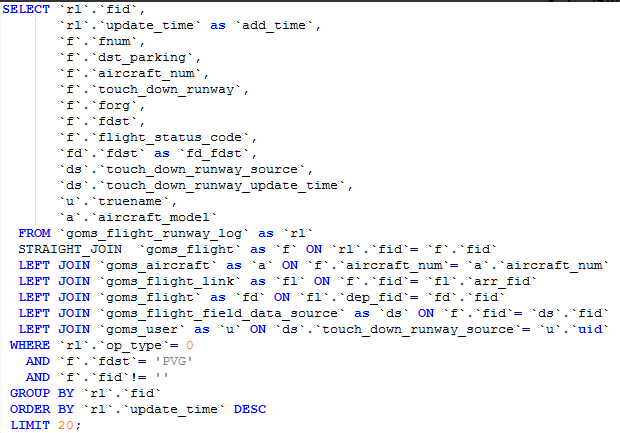
这个方式有时可能减少3倍的时间。
避免隐式类型转换
where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定where中的参数类型
select id ,time from test where type=77 //传入的是整形,type类型是字符串
对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id,name,school,可以直接用id字段,也可以id,name这样的顺序,但是name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面
不建议使用%前缀模糊查询
例如LIKE “%name”或者LIKE “%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用LIKE “name%”。
那如何查询%name%?
如下图所示,虽然给secret字段添加了索引,但在explain结果果并没有使用
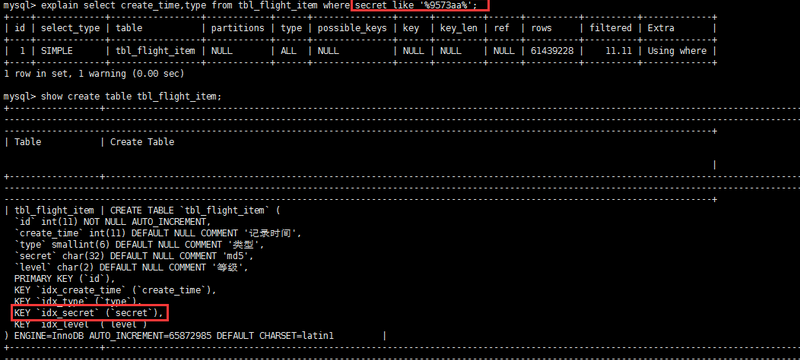
那么如何解决这个问题呢,答案:使用全文索引
在我们查询中经常会用到select id,fnum,fdst from dynamic_201606 where user_name like '%zhangsan%'; 。这样的语句,普通索引是无法满足查询需求的。庆幸的是在MySQL中,有全文索引来帮助我们。
创建全文索引的sql语法是:
ALTER TABLE `dynamic_201606` ADD FULLTEXT INDEX `idx_user_name` (`user_name`);复制代码
使用全文索引的sql语句是:
select id,fnum,fdst from dynamic_201606 where match(user_name) against('zhangsan' in boolean mode);复制代码
注意:在需要创建全文索引之前,请联系DBA确定能否创建。同时需要注意的是查询语句的写法与普通索引的区别
EXPLAIN
做MySQL优化,我们要善用 EXPLAIN 查看SQL执行计划。
-
type列,连接类型。一个好的sql语句至少要达到range级别。杜绝出现all级别
-
key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式
-
key_len列,索引长度
-
rows列,扫描行数。该值是个预估值
-
extra列,详细说明。注意常见的不太友好的值有:Using filesort, Using temporary