---恢复内容开始---
所下内容都是对吴恩达教授的机器学习所做的笔记
下面是Arthur Samue对机器学习的定义
在没有明确设置的情况下,是计算机具有学习能力的研究领域。
这是一个比较陈旧一点的定义。
下面是Tom Mitchell的定义
计算机程序从经验(E)中学习,解决某一任务(T)进行某一性能度量(P),通过P测定在T上的表现因经验E而提高。
主要两种学习算法:1.监督学习 2. 无监督学习
简单来说监督学习就是我们会教计算机做某件事,然而在无监督学习中,是我们让计算机自己学习。
Supervised Learning (监督学习)
例子: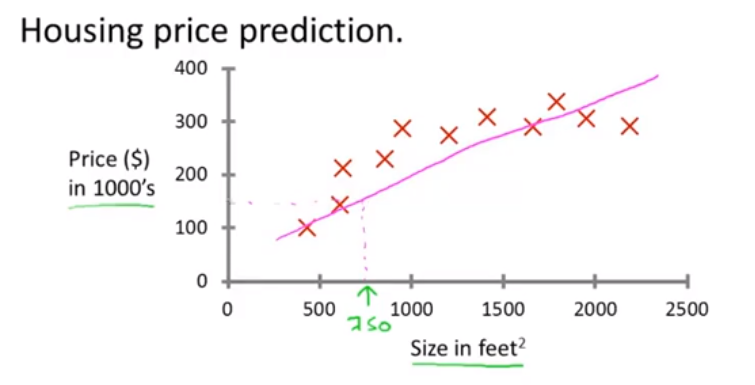
一个学生收集了这些数据,假设你绘制了一个数据集就像上图这样,横轴是不同房屋的平方英尺数,纵轴是不同房子的价格 单位是千美元,交涉你的朋友右一栋750平方英尺的房子,他想知道能卖多少钱, 然而学习算法能干吗呢?学习算法能做到的一件事就是根据数据画一条直线或者说用一条直线拟合数据,从而估计房子可以卖大约15万美元。
监督学习是指我们给算法一个数据集,其中包含了正确答案,也就是说我们给它一个房价数据集,在这个数据集中的每个样本,我们都给出正确的价格,即这个房子实际卖价,算法的母的就是给出更多的正确答案,例如为你朋友想要卖掉的这所新房子给出估价 ,用更专业的术语来定义称为回归问题,我们想要预测连续的数值输出价格。价格实际上是一个离散值。我们设法预测连续值的属性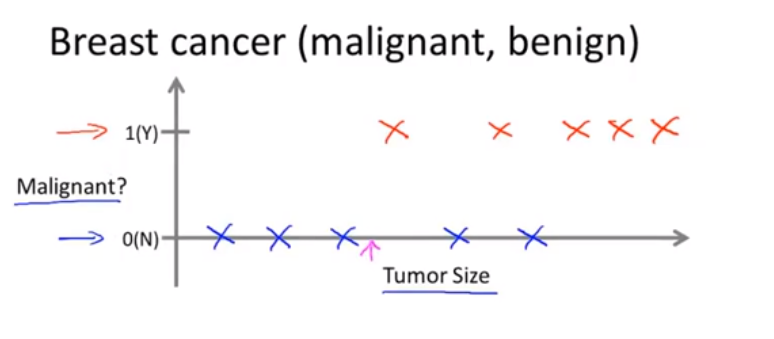
例子:下面这一行是良性肿瘤, 上面这一行是恶性肿瘤,假设我们有个朋友不幸患了乳腺肿瘤, 它的大小可能是这个值 (紫色标记) 附近,机器学习的问题就是,你能否估计出肿瘤是良性还是恶性的概率,用更专业的术语讲这就是一个分类问题,分类是指我们设法预测一个离散值的输出 良性或恶性。实际上,你可能有两个以上的可能的输出值,在分类问题中有另一种方法来绘制这些数据, 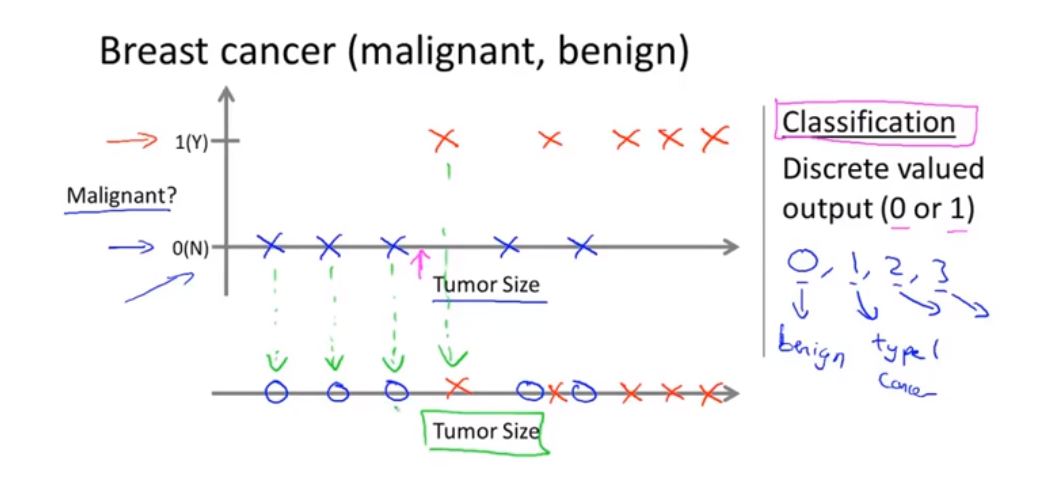 我们用不同的符号对应到一条线上。
我们用不同的符号对应到一条线上。
Unsupervised Learning(无监督学习)
例子:
在无监督学习中我们使用的数据和之前不同,没有任何标签,都具有相同的标签或者都没有标签,我们得到一个数据集,我们不知道拿它做什么,我们只是被告知在这里有一个数据集,你能在其中找到某种结构吗,对于给定的数据集,无监督学习算法可能判定,该数据集包含两个不同的簇 , 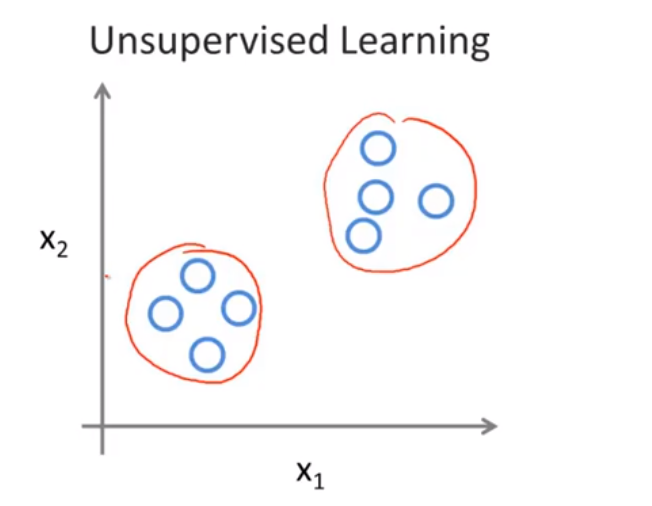 无监督学习算法可以把他们分成两簇,这就是聚类算法。其中有谷歌新闻就是应用聚类算法的例子。
无监督学习算法可以把他们分成两簇,这就是聚类算法。其中有谷歌新闻就是应用聚类算法的例子。
例子:
假设一个宴会上只有两个人,两人同时说话,我们把两个麦克风放在房间里,两个麦克风与这两个人的距离不相同,每个麦克风记录了来自两人不同的声音组合,也许第一个人的声音在一号麦克风里会响一点,也许第二个人的声音在二号麦克风里更响一些,因为两个麦克风相对于两个说话者的位置是不同的,但每个麦克风都会录到两个说话者重叠的声音,让它帮你找出数据的结构,称为鸡尾酒会算法,此外,它还会分离出这两个被混合到一起的音频源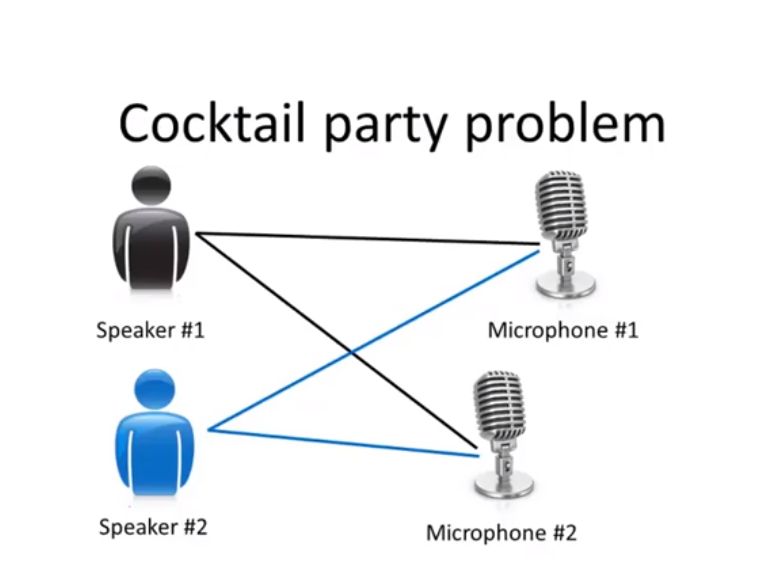 ,要实现这样的算法有多复杂,
,要实现这样的算法有多复杂, 这样一行就可以解决问题,
这样一行就可以解决问题,
---恢复内容结束---