1,BeautifulSoup库是解析,遍历,维护“标签树”代码的功能库;名字为beautifulsoup4或bs4;
引用方式为:from bs4 import BeautifulSoup 或者 import bs4;
1.1 BeautifulSoup类的五种基本元素:
1.1.1 Tag标签:<p class="title"> ... </p> ;
意义:最基本的信息组织单元,标签总是成对出现,标签头常包含有该标签的多对属性(attributes);
引用格式:对象.标签名字;
格式意义:表示返回标签名字为name的bs4类对象的标签全部内容;
以下四种属性都是tag标签基础上的衍生属性(便于理解这么记,语法上可能不成立);
1.1.2 Name 标签名字:<p>...</p>
意义:标签的名字为p;
引用格式:对象.标签名字.name;
格式意义:表示返回该标签的名字;
1.1.3 Attributes 标签属性,
<p class="title"><b>The demo python introduces several python courses.</b></p>
意义:class="title"为标签的类属性;
引用格式:对象.标签名字.attrs['class'];
格式意义:返回该标签属性的字典形式(包含该标签的所有属性);若是加上后缀中括号,表示返回中括号内 特定类的属性值,此处应返回'title';
1.1.4 NavigableString 标签内非属性字符串(...内容部分);
格式:对象.标签名字.string;
格式意义:返回该标签的内容部分;如1.1.3例中的灰色部分;
1.1.5 Comment 标签内字符串的注释部分,一种特殊的Comment类型;
格式:以 <! 开头表示注释;我们在提取内容的时候要注意和NavigableString内容进行类型的区分;
格式意义:(以后理解了补充)
import requests from bs4 import BeautifulSoup r=requests.get("http://www.python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,'html.parser') soup.prettify() print(soup.title) print(soup.title.name) print(soup.title.parent.name) print(soup.p.attrs) print(soup.title.string) <title>This is a python demo page</title> title head {'class': ['title']} This is a python demo page
1.2 beautifulsoup库的解析语法:
1.2.1 soup=BeautifulSoup('<name>...data...</name>','html.parser')
该函数表示以‘html.parser’的方式将'data'解析成BeautifulSoup类,存入对象soup中;
1.2.2 soup.prettify()
该函数为HTML文本对象soup增加 ,提高文本的可读性;
1.2.3 bs4库默认将HTML文本以utf-8编码解析,Python3.x也是;
1.2.4 type()
可以返回标签的类型,或者标签属性的类型;
2, bs4库的遍历方法:
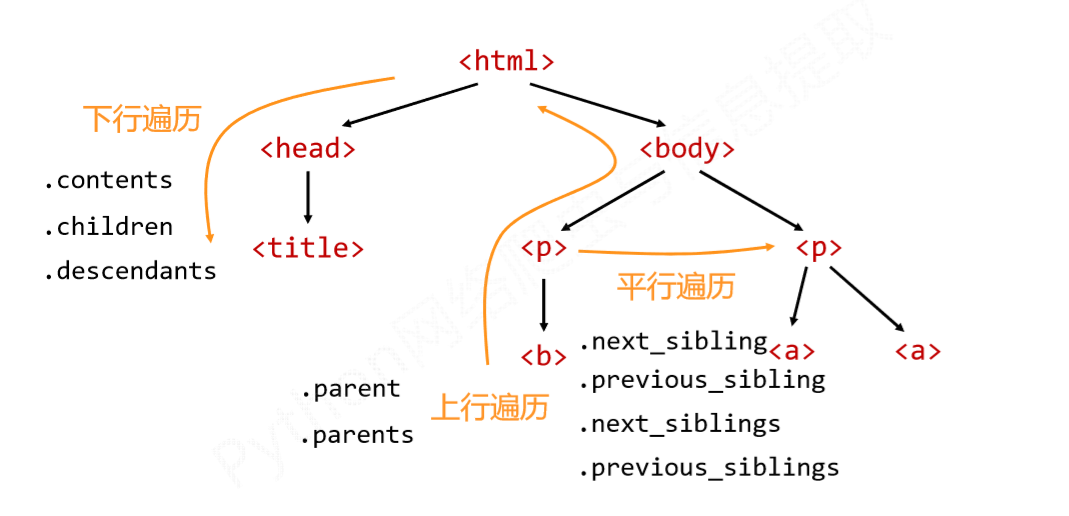
2.0 迭代类型:迭代类型只能用在for和in循坏语句中;
2.1 下行遍历:
2.1.1 .contents :返回所有子节点的节点信息存入列表;' '属于一个子节点;
2.1.2 .children: 用于循环遍历子节点;迭代类型;用法举例如下:
for child in soup.body.children: print(child)
2.1.3 .descendants: 用于循环遍历所有子孙节点;迭代类型;用法举例如下:
#先打印body的子节点p,接着打印p的子节点b,然后打印b的内容字符串;
#在遍历的时候可以把标签,标签内容,NavigitableString内容,换行符,都视为节点;因为都会遍历;
for child in soup.body.descendants: print(child)
2.2 上行遍历:
2.2.1 .parent : 返回父节点的标签;
2.2.2 .parents : 返回父节点以及先辈节点的标签;
2.2.3 我们在上行遍历parents的时候会遍历到对象本身,但是对象本身是不具有标签的,建议加上判断语句区分;
2.3 平行遍历:(不同父节点下的平行节点不能平行遍历)
2.3.1 .next_sibling : 返回当前节点的下一平行节点;标签之间的NavigableString内容也是节点;
2.3.2 .previous_sibling: 返回当前节点的上一平行节点;
2.3.3 .next_siblings: 用于循坏遍历当前节点的后续平行节点;迭代类型;
for sibling in soup.a.next_siblings: print(sibling)
2.3.4 .previous_siblings:用于循坏遍历当前节点的前续平行节点;迭代类型;
for sibling in soup.a.previous_siblings: print(sibling)