环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-2.6.5
hbase-0.98.12.1-hadoop2
HBase中表的设计
主要是将原来的关系解开
问题:

例子:

表设计一:

表设计二:

这是一个双向查询,根据人员查角色,根据角色查人员
问题:
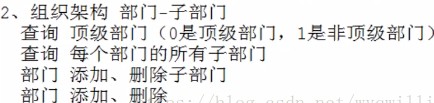
0为顶级部门,1为子部门

放到一张表中不会对效率产生影响,因为HBASE是海量存储,海量读写的。
Redis是一个内存数据库,新浪微博是使用Redis用的最好的一家公司
Redis可以持久化到本地,可以解决并发的问题
表设计中的两点:
1.加前缀,为了便于区分
2.不加前缀,进行解耦
表设计案例二:微博

规律:
如果是一对多,从一端保存多端的信息就可以
如果是一对一,就是单一的操作,不用建两张表
多对多建表的时候,数据冗余比较严重,需要建双端的查询
微博的表设计:一对多

rowkey尽量短,
列族尽量少于三个,太多的话会增加磁盘IO。
参考:
https://blog.csdn.net/wyqwilliam/article/details/82025004
https://www.cnblogs.com/cxzdy/p/5118456.html