环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
·字词的重要性随着它在文件中出现的次数成正比增加
·但同时会随着它在语料库中出现的频率成反比下降
TF-IDF加权的各种形式常被搜寻引擎应用
·作为文件与用户查询之间相关程度的度量或评级。
·除了TF-IDF以外,因特网上的搜寻引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序:PR。
词频 (term frequency, TF) 指的是某一个给定的词语在一份给定的文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
公式中:ni,j是该词在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。

逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
|D|:语料库中的文件总数
 包含ti文件的数目
包含ti文件的数目
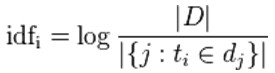
TF-IDF:

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。

package test.mr.tfidf; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FirstJob { public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.coress-paltform", "true"); conf.set("mapreduce.framework.name", "local"); try { FileSystem fs = FileSystem.get(conf); Job job = Job.getInstance(conf); job.setJarByClass(FirstJob.class); job.setJobName("weibo1"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setNumReduceTasks(4); job.setPartitionerClass(FirstPartition.class); job.setMapperClass(FirstMapper.class); job.setCombinerClass(FirstReduce.class); job.setReducerClass(FirstReduce.class); FileInputFormat.addInputPath(job, new Path("/root/tfidf/input/")); Path path = new Path("/root/tfidf/output/weibo1"); if (fs.exists(path)) { fs.delete(path, true); } FileOutputFormat.setOutputPath(job, path); boolean f = job.waitForCompletion(true); if (f) { } } catch (Exception e) { e.printStackTrace(); } } }
package test.mr.tfidf; import java.io.IOException; import java.io.StringReader; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; /** * 第一个MR,计算TF和计算N(微博总数) * * @author root * */ public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable> { protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //3823890210294392 今天我约了豆浆,油条 String[] v = value.toString().trim().split(" "); if (v.length >= 2) { String id = v[0].trim(); String content = v[1].trim(); StringReader sr = new StringReader(content); IKSegmenter ikSegmenter = new IKSegmenter(sr, true); Lexeme word = null; while ((word = ikSegmenter.next()) != null) { String w = word.getLexemeText(); context.write(new Text(w + "_" + id), new IntWritable(1)); //今天_3823890210294392 1 } context.write(new Text("count"), new IntWritable(1)); //count 1 } else { System.out.println(value.toString() + "-------------"); } } }
package test.mr.tfidf; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; /** * 第一个MR自定义分区 * @author root * */ public class FirstPartition extends HashPartitioner<Text, IntWritable>{ public int getPartition(Text key, IntWritable value, int reduceCount) { if(key.equals(new Text("count"))) return 3; else return super.getPartition(key, value, reduceCount-1); } }
package test.mr.tfidf; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * c1_001,2 c2_001,1 count,10000 * * @author root * */ public class FirstReduce extends Reducer<Text, IntWritable, Text, IntWritable> { protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : iterable) { sum = sum + i.get(); } if (key.equals(new Text("count"))) { System.out.println(key.toString() + "___________" + sum); } context.write(key, new IntWritable(sum)); } }
package test.mr.tfidf; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TwoJob { public static void main(String[] args) { Configuration conf =new Configuration(); conf.set("mapreduce.app-submission.coress-paltform", "true"); conf.set("mapreduce.framework.name", "local"); try { Job job =Job.getInstance(conf); job.setJarByClass(TwoJob.class); job.setJobName("weibo2"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(TwoMapper.class); job.setCombinerClass(TwoReduce.class); job.setReducerClass(TwoReduce.class); //mr运行时的输入数据从hdfs的哪个目录中获取 FileInputFormat.addInputPath(job, new Path("/data/tfidf/output/weibo1")); FileOutputFormat.setOutputPath(job, new Path("/data/tfidf/output/weibo2")); boolean f= job.waitForCompletion(true); if(f){ System.out.println("执行job成功"); } } catch (Exception e) { e.printStackTrace(); } } }
package test.mr.tfidf; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; //统计df:词在多少个微博中出现过。 public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> { protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取当前 mapper task的数据片段(split) FileSplit fs = (FileSplit) context.getInputSplit(); if (!fs.getPath().getName().contains("part-r-00003")) { //豆浆_3823890201582094 3 String[] v = value.toString().trim().split(" "); if (v.length >= 2) { String[] ss = v[0].split("_"); if (ss.length >= 2) { String w = ss[0]; context.write(new Text(w), new IntWritable(1)); } } else { System.out.println(value.toString() + "-------------"); } } } }
package test.mr.tfidf; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class TwoReduce extends Reducer<Text, IntWritable, Text, IntWritable> { protected void reduce(Text key, Iterable<IntWritable> arg1, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : arg1) { sum = sum + i.get(); } context.write(key, new IntWritable(sum)); } }
package test.mr.tfidf; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.filecache.DistributedCache; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LastJob { public static void main(String[] args) { Configuration conf =new Configuration(); // conf.set("mapred.jar", "C:\Users\root\Desktop\tfidf.jar"); //conf.set("mapreduce.job.jar", "C:\Users\root\Desktop\tfidf.jar"); conf.set("mapreduce.app-submission.cross-platform", "true"); try { FileSystem fs =FileSystem.get(conf); Job job =Job.getInstance(conf); job.setJarByClass(LastJob.class); job.setJobName("weibo3"); job.setJar("C:\Users\root\Desktop\tfidf.jar"); //2.5 //把微博总数加载到 job.addCacheFile(new Path("/root/tfidf/output/weibo1/part-r-00003").toUri()); //把df加载到 job.addCacheFile(new Path("/root/tfidf/output/weibo2/part-r-00000").toUri()); //设置map任务的输出key类型、value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(LastMapper.class); job.setReducerClass(LastReduce.class); //mr运行时的输入数据从hdfs的哪个目录中获取 FileInputFormat.addInputPath(job, new Path("/data/tfidf/output/weibo1")); Path outpath =new Path("/root/tfidf/output/weibo3"); if(fs.exists(outpath)){ fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job,outpath ); boolean f= job.waitForCompletion(true); if(f){ System.out.println("执行job成功"); } } catch (Exception e) { e.printStackTrace(); } } }
package test.mr.tfidf; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.net.URI; import java.text.NumberFormat; import java.util.HashMap; import java.util.Map; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; /** * 最后计算 * * @author root * */ public class LastMapper extends Mapper<LongWritable, Text, Text, Text> { // 存放微博总数 public static Map<String, Integer> cmap = null; // 存放df public static Map<String, Integer> df = null; // 在map方法执行之前 protected void setup(Context context) throws IOException, InterruptedException { System.out.println("******************"); if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) { URI[] ss = context.getCacheFiles(); if (ss != null) { for (int i = 0; i < ss.length; i++) { URI uri = ss[i]; if (uri.getPath().endsWith("part-r-00003")) {// 微博总数 Path path = new Path(uri.getPath()); // FileSystem fs // =FileSystem.get(context.getConfiguration()); // fs.open(path); BufferedReader br = new BufferedReader(new FileReader(path.getName())); String line = br.readLine(); if (line.startsWith("count")) { String[] ls = line.split(" "); cmap = new HashMap<String, Integer>(); cmap.put(ls[0], Integer.parseInt(ls[1].trim())); } br.close(); } else if (uri.getPath().endsWith("part-r-00000")) {// 词条的DF df = new HashMap<String, Integer>(); Path path = new Path(uri.getPath()); BufferedReader br = new BufferedReader(new FileReader(path.getName())); String line; while ((line = br.readLine()) != null) { String[] ls = line.split(" "); df.put(ls[0], Integer.parseInt(ls[1].trim())); } br.close(); } } } } } protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit) context.getInputSplit(); // System.out.println("--------------------"); if (!fs.getPath().getName().contains("part-r-00003")) { //豆浆_3823930429533207 2 String[] v = value.toString().trim().split(" "); if (v.length >= 2) { int tf = Integer.parseInt(v[1].trim());// tf值 String[] ss = v[0].split("_"); if (ss.length >= 2) { String w = ss[0]; String id = ss[1]; double s = tf * Math.log(cmap.get("count") / df.get(w)); NumberFormat nf = NumberFormat.getInstance(); nf.setMaximumFractionDigits(5); context.write(new Text(id), new Text(w + ":" + nf.format(s))); } } else { System.out.println(value.toString() + "-------------"); } } } }
package test.mr.tfidf; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class LastReduce extends Reducer<Text, Text, Text, Text> { protected void reduce(Text key, Iterable<Text> iterable, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for (Text i : iterable) { sb.append(i.toString() + " "); } context.write(key, new Text(sb.toString())); } }