




Range
用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式:
Range:(unit=first byte pos)-[last byte pos]
Range 头部的格式有以下几种情况:
Range: bytes=0-499 表示第 0-499 字节范围的内容
Range: bytes=500-999 表示第 500-999 字节范围的内容
Range: bytes=-500 表示最后 500 字节的内容
Range: bytes=500- 表示从第 500 字节开始到文件结束部分的内容
Range: bytes=0-0,-1 表示第一个和最后一个字节
Range: bytes=500-600,601-999 同时指定几个范围
原始响应内容¶
在罕见的情况下,你可能想获取来自服务器的原始套接字响应,那么你可以访问 r.raw。 如果你确实想这么干,那请你确保在初始请求中设置了 stream=True。具体你可以这么做:
r = requests.get('https://api.github.com/events', stream=True)
r.raw
<requests.packages.urllib3.response.HTTPResponse object at 0x101194810>r.raw.read(10)
'x1fx8bx08x00x00x00x00x00x00x03'
但一般情况下,你应该以下面的模式将文本流保存到文件:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)
使用 Response.iter_content 将会处理大量你直接使用 Response.raw 不得不处理的。 当流下载时,上面是优先推荐的获取内容方式。 Note that chunk_size can be freely adjusted to a number that may better fit your use cases.
# -*- coding: utf-8 -*-
# @Time : 2019/2/13 8:17 PM
# @Author : cxa
# @File : mp4downloders.py
# @Software: PyCharm
import requests
from tqdm import tqdm
import os
import base64
from cryptography.fernet import Fernet
import aiohttp
import asyncio
import uvloop
try:
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
except ImportError:
pass
keystr = "X0JxSkg4NFVBQVBPODlUM0VzT1liNnloeWtLcndkSldRT2xURzQ4MEM5RT0="
def get_aes_key():
key = base64.b64decode(keystr).decode("utf8")
return key
cipher = Fernet(get_aes_key())
def aes_cbc_decrypt(message):
'''解密'''
decrypted_text = Fernet(base64.b64decode(keystr).decode("utf8")).decrypt(
bytes("{}".format(message), encoding="utf8"))
return decrypted_text.decode("utf8")
def aes_cbc_encrypt(message):
'''解密'''
encrypted_text = cipher.encrypt(bytes("{}".format(message), encoding="utf8"))
return encrypted_text
async def fetch(session, url, dst, pbar=None, headers=None):
if headers:
async with session.get(url, headers=headers) as req:
with(open(dst, 'ab')) as f:
while True:
chunk = await req.content.read(1024)
if not chunk:
break
f.write(chunk)
pbar.update(1024)
pbar.close()
else:
async with session.get(url) as req:
return req
async def async_download_from_url(url, dst):
'''异步'''
async with aiohttp.connector.TCPConnector(limit=300, force_close=True, enable_cleanup_closed=True) as tc:
async with aiohttp.ClientSession(connector=tc) as session:
req = await fetch(session, url, dst)
file_size = int(req.headers['content-length'])
print(f"获取视频总长度:{file_size}")
if os.path.exists(dst):
first_byte = os.path.getsize(dst)
else:
first_byte = 0
if first_byte >= file_size:
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
await fetch(session, url, dst, pbar=pbar, headers=header)
#
# req = requests.get(url, headers=header, stream=True)
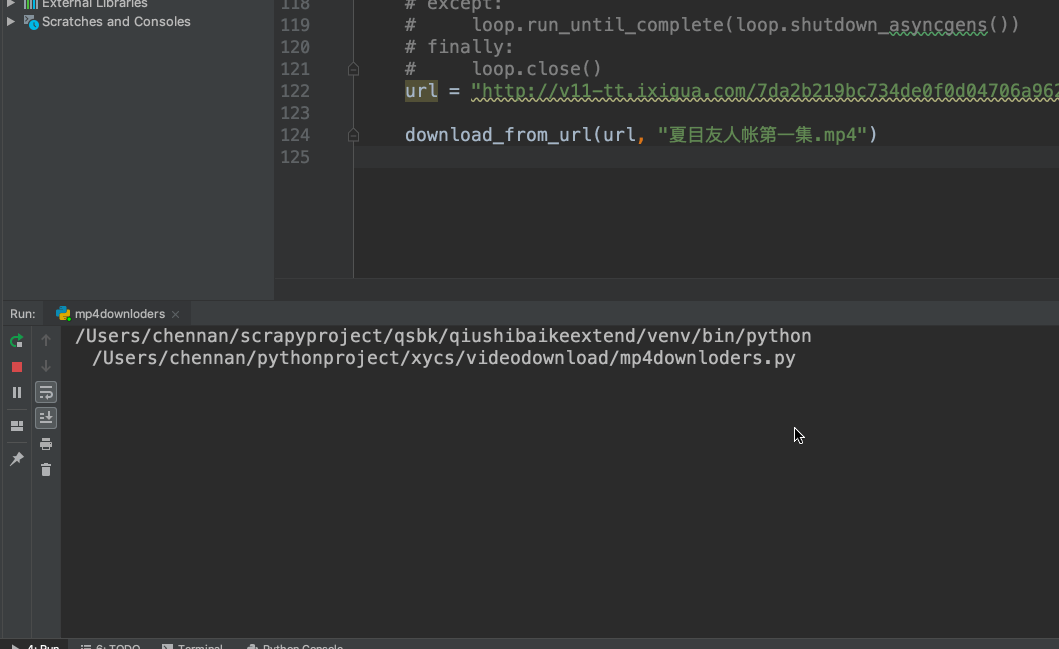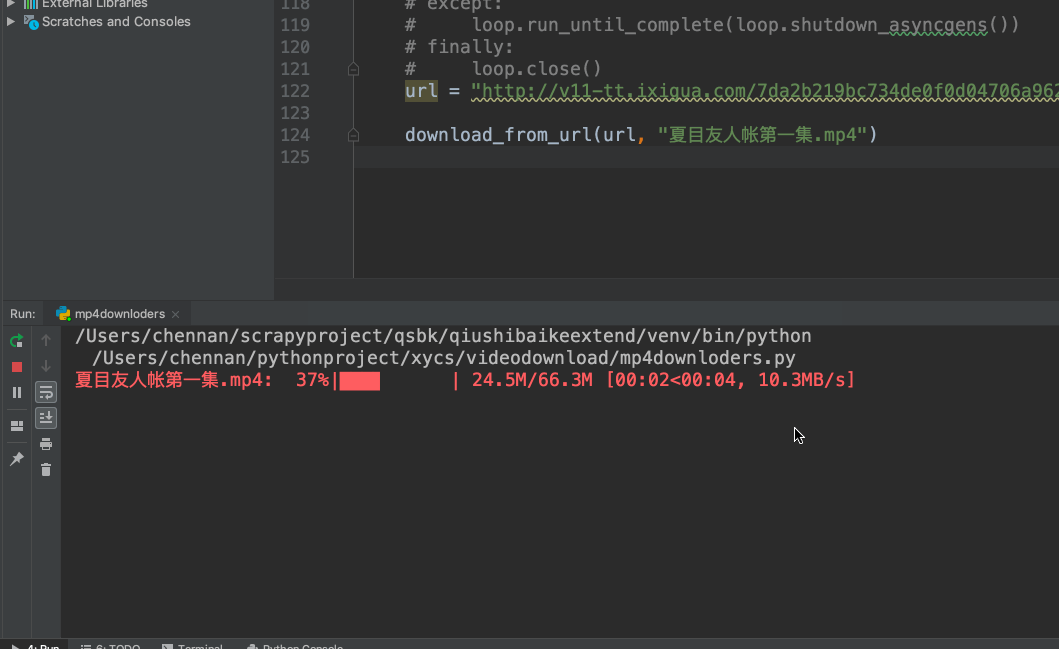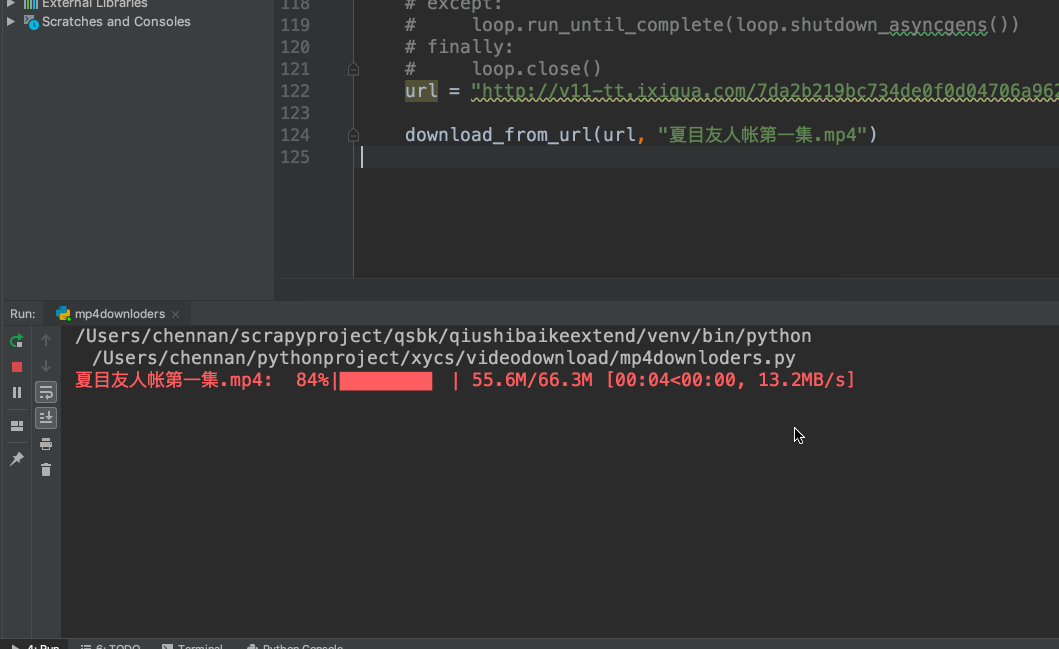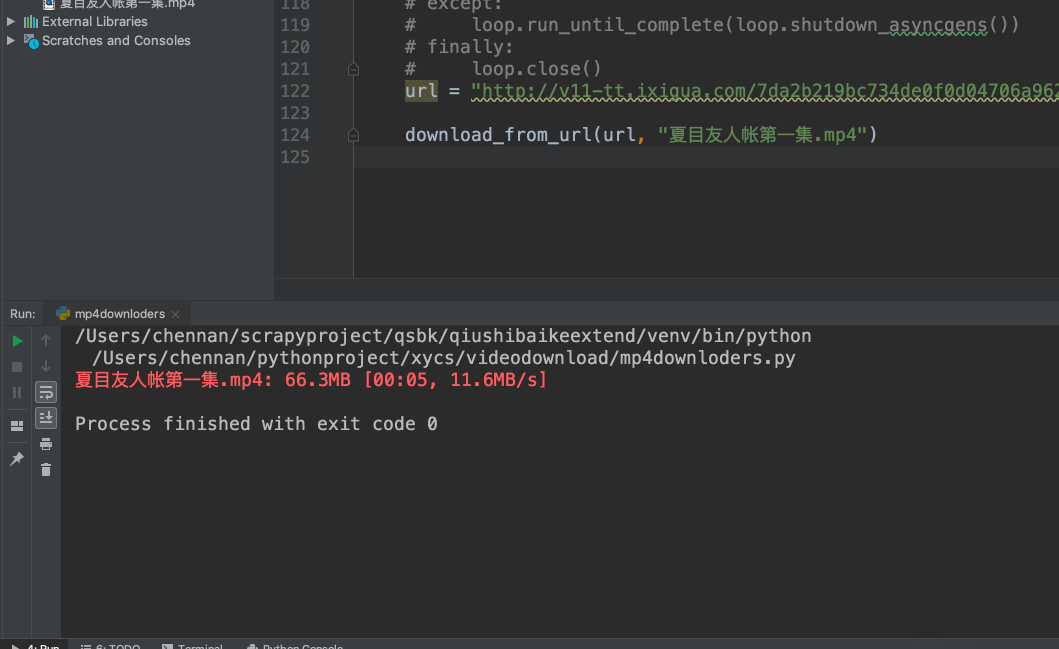
def download_from_url(url, dst):
'''同步'''
response = requests.get(url, stream=True)
file_size = int(response.headers['content-length'])
if os.path.exists(dst):
first_byte = os.path.getsize(dst)
else:
first_byte = 0
if first_byte >= file_size:
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=dst)
req = requests.get(url, headers=header, stream=True)
with(open(dst, 'ab')) as f:
for chunk in req.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
pbar.update(1024)
pbar.close()
return file_size
if __name__ == '__main__':
url = "xxxxx" #一个mp4链接即可。
task = [asyncio.ensure_future(async_download_from_url(url, f"{i}.mp4")) for i in range(2, 14)]
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
except:
loop.run_until_complete(loop.shutdown_asyncgens())
finally:
loop.close()
# download_from_url(url, "1.mp4")