这一个多周忙别的事去了,忙完了,接着看讲义~
这章讲的是深度网络(Deep Network)。前面讲了自学习网络,通过稀疏自编码和一个logistic回归或者softmax回归连接,显然是3层的。而这章则要讲深度(多层)网络的优势。
Deep Network:
为什么要使用深度网络呢?使用深度网络最主要的优势在于,它能以简洁的方式来表达比浅层网络大得多的函数集合。正式点说,可以找到一些函数,它们能够用k层网络简洁的表达出来(这里的简洁指的是使用隐层单元的数目与输入单元数目是多项式关系),但是对一个只有(k-1)层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
在处理对象是图像的情况下,能够通过使用深度网络学习到“部分-整体”的分解关系。例如,第一层可以学习将图像中的像素组合在一起来检测边缘(正如我们在前面的练习中做的那样)。第二层可以将边缘组合起来检测更长的轮廓或者简单的“目标的部件”。在更深的层次上,可以将这些轮廓进一步组合起来以检测更为复杂的特征。这个可以参考CSDN上的一篇博文(以前看到的,有点印象,就找了找)http://blog.csdn.net/abcjennifer/article/details/7804962
Deep Network无疑具有很大的优势,但是也很显然的就是训练的时候是非常困难的。讲义中讲了3方面的原因:数据难获取(标注数据量非常少),局部极值问题和梯度弥散问题。(这里就不具体写了,容易理解)。为了训练好深度网络,讲义中提到用逐层贪婪训练的方法:每次只训练一层网络,即我们首先训练一个只有一层隐层的网络,仅当这层网络训练结束之后才开始训练一个有两层隐层的网络,以此类推。在每一步中,我们把已经训练好的前K层固定,然后增加第K-1层(也就是将我们已经训练好的前的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但是更经常是无监督的(例如自动编码器)。下面就是一种逐层贪婪训练方法的介绍:
Stacked Autoencoders:
栈式自编码神经网络。这节中,我们将会学习如何将自编码器以贪心分层的方式栈化,从而预训练(或者说初始化)深度神经网络的权重。
关于这个栈式自编码神经网络,其实就是前面说的稀疏自编码神经网络一层一层叠起来。即先训练一个自编码神经网络,得到参数W,b后将原始数据通过W,b转化成由隐藏单元响应组成的向量,假设该向量为A,接着把A作为第二层的输入,继续训练得到第二层的参数W,b。对后面的各层同样采用将前层的输出作为下一层输入的方式依次训练。
在上述所有预训练完成后,再通过一次反响传播,调整所有层的参数。这个过程叫做微调(fine-tuning)。
讲义举了MINIST手写库识别的例子,感觉看这个例子就很清楚了:
首先,需要用原始输入x(k)训练第一个自编码器,它能够学习得到原始输入的一阶特征表示 h(1)(k)(如下图所示)。

接着,把所有原始数据输入到训练好的自编码器中,得到输出向量h(1)(k),然后将此输出向量作为下一个自编码器的输入,来得到二阶特征:
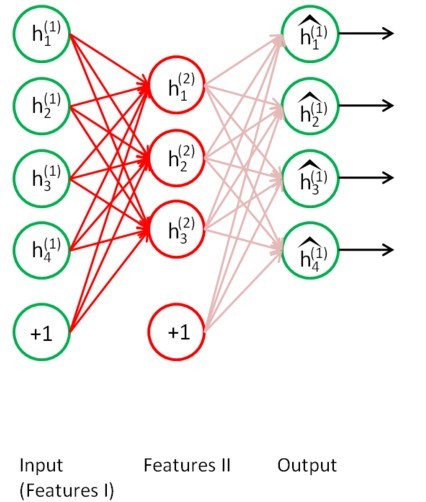
最后,经过几次以后,再用softmax分类器进行分类即可。
这样就得到了一个深度的神经网络结构。例如,叠加两个自编码器的情况:

Finetuning:
微调。前面提到了,要使结果更好,最后可以进行一次微调,利用反向传播法对所有层的参数进行一次调整。反向传播前面已经看过了,这里差别不大,直接把讲义上的复制过来了:

练习:
最后就是练习了。篇幅太长了,写在下篇吧。