目录:
- 什么是Kafka Connect
- Kafka Connect能干什么
- Kafka Connect使用示例
什么是Kafka Connect
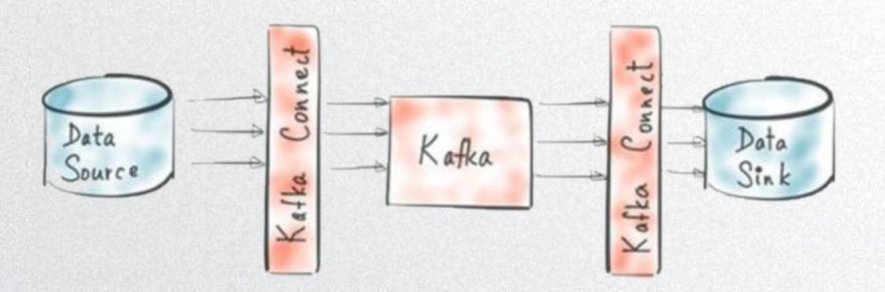
它是一种用于Kafka和其它系统之间(其它数据源)流式数据传输的工具,如Mysql >> Oracle,Json >> Mysql,MongoDB >> Elastic等。
常用于报表等,因为他们都需要从多个数据源中抽取需要的数据,然后再将这些数据处理,最后存到自己的数据源中。
——————————————————————————————————————————————————————
Kafka Connect功能:
- 规范接口:规范了其它数据系统与Kafka的集成,简化了连接器的开发、部署和管理。
- 提供分布式和单机模式:上至分布式集中管理,下到开发、测试和小规模的生产部署。
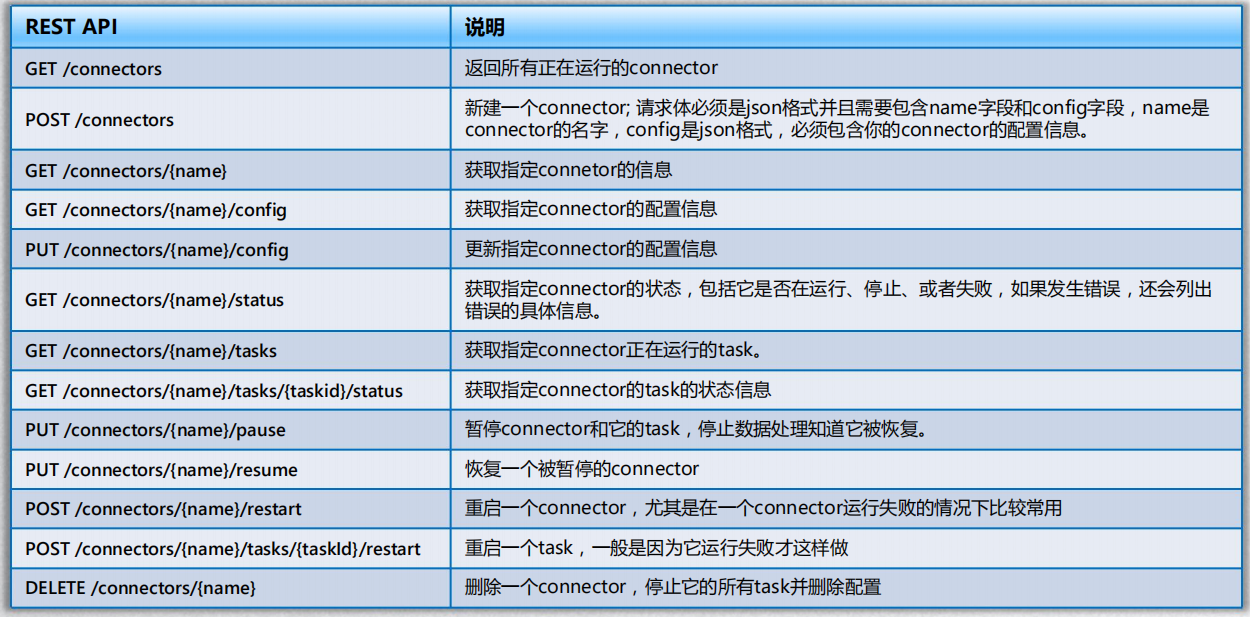
- 提供RestAPI接口:提供RestAPI管理Connector。
- 自动的offset管理:解决了开发连接器人员最难搞的offset维护问题。
- 可扩展性:Kafka Connect基于现有的组管理协议,可添加更多的worker来扩展Kafka Connect集群。
Kafka Connect能干什么
1、提升获取数据速度:当需要接受大数据,可以在几毫秒之内就拿到这些数据并开始进行处理。
2、提供高可用的数据传输:数据管道传输数据到业务系统的过程中,其间不会出现单点故障。即便出现故障也可以自动从故障中恢复,保证数据的可靠性。
3、提供高吞吐量管道、有效应对数据峰值:数据管道可以支持非常高的吞量,而且数据管道可以应对突发的吞吐量增长。
4、规范接口:对开发者提供了统一的实现接口,开发、部署和管理都非常方便。
5、提供高扩展性:使用分布式模式进行水平扩展。
6、提供RestAPI管理Connectors:在分布式模式下可以通过Rest Api提交和管理Connectors。
注:目前Kafka Connect已经支持绝大部分的主流数据源,如JDBC、HDFS、HBase等。
Kafka Connect使用示例
使用Kafka Connect之前先来了解些基本的概念:
- Source:负责导入数据到Kafka。
- Sink:负责从Kafka导出数据。
- Connectors:通过管理任务来协调数据流的高级抽象。
- Tasks:数据写入Kafka和从Kafka中读出的具体实现。
- Workers:运行connectors和tasks的进程。
- Converters:Kafka connect和其他存储系统直接发送或者接受数据之间转换数据。
- Transforms:一种轻量级数据调整的工具。
——————————————————————————————————————————————————————
1、单机模式
./connect-standalone.sh ../config/connect-file.properties ../config/connect-file-source.properties ../config/connect-file-sink.properties
2、分布式
- 下载相应的第三方Connect后打包编译。
- 将jar丢到Kafka的libs目录下。
- 启动connector。
- 使用Rest API提交connector配置。
./connect-distributed.sh ../config/connect-distributed.properties