0x00 前言
上一篇爬取豆瓣评论的文章地址:https://www.cnblogs.com/byyanxia/p/14423708.html
今天写的是作业3——实时的对本次春节档的电影票房进行爬取,然后我加了个推送到微信功能,这样我们可以在微信上实时监控。
本篇程序所利用的库如下:
import requests,json,schedule,time
from lxml import etree
打个小广告(网络安全俱乐部人才多多,人长的好看,说话又好听我超喜欢这里的。下一次纳新的时候欢迎踊跃报名。诚招:WEB,REVERSER,PWN,MISC各类方向优秀人才,只要肯学就OK!)
好了步入正题
0x01 正文
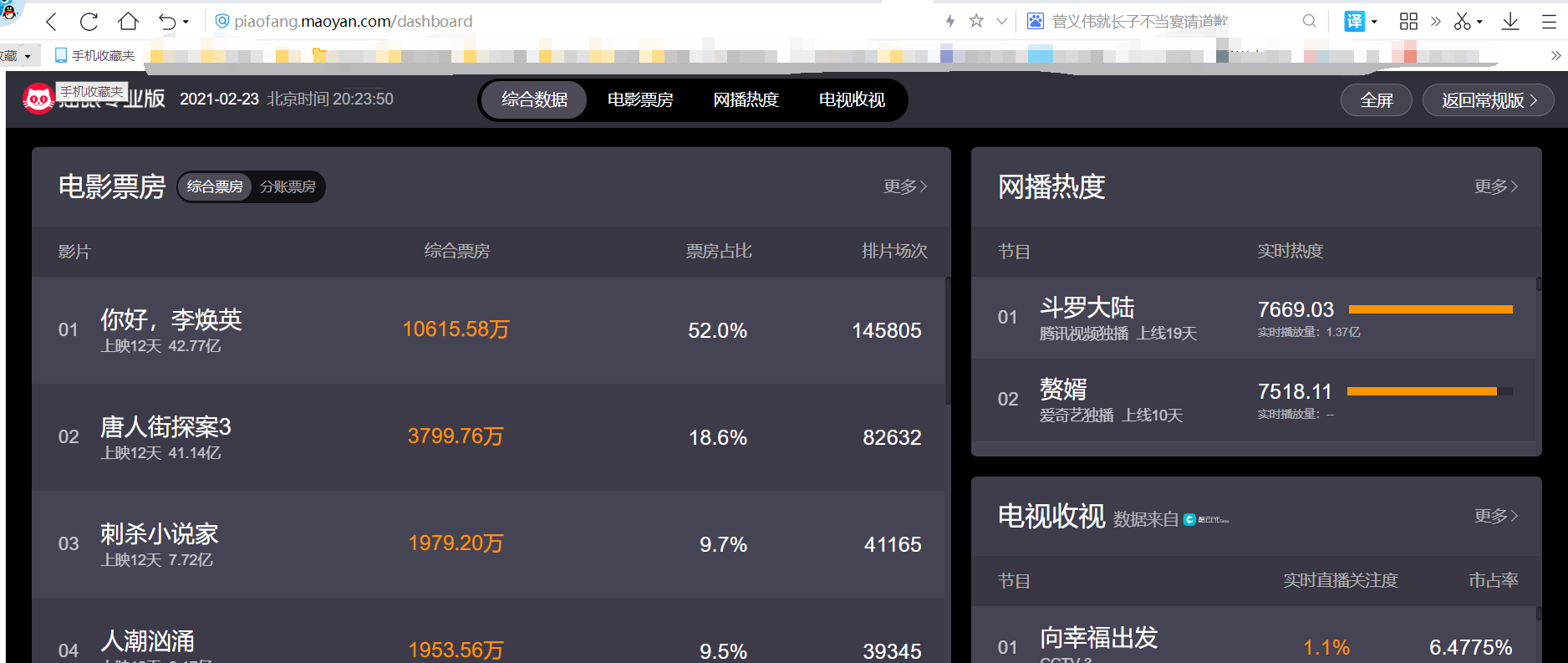
打开过这个地址的bro一定会发现,综合票房的数据进行了反爬虫处理,如果想要绕过限制还需要下载该网站匹配字体等系列操作进行绕过。(还挺麻烦)
我辈弟子怎能轻言放弃?
不得不说,猫眼的程序员,放松了警惕。以为大家都在专业版晃悠??(确实,一堆人晃悠)
咱直接打开http://piaofang.maoyan.com/box-office?ver=normal这个地址。便会发现,好家伙。这里没有半点加密。
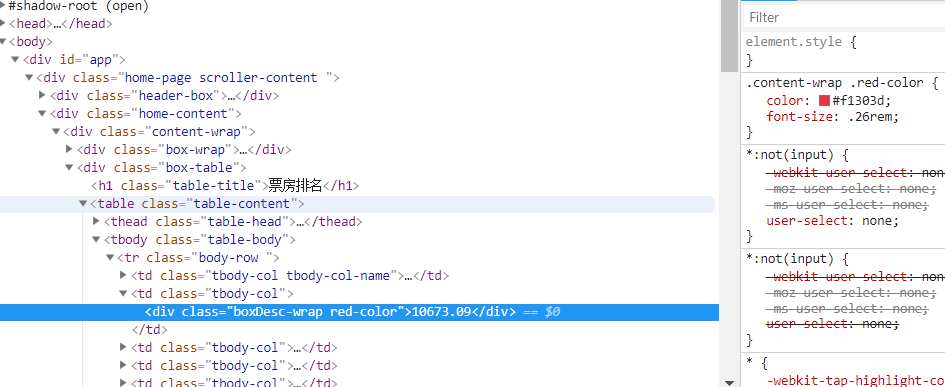
那还说啥,直接爬就完事了。这里我们依旧用到了XPATH的定位方法。效率贼高!不会用的朋友,请看一下上一篇文章。
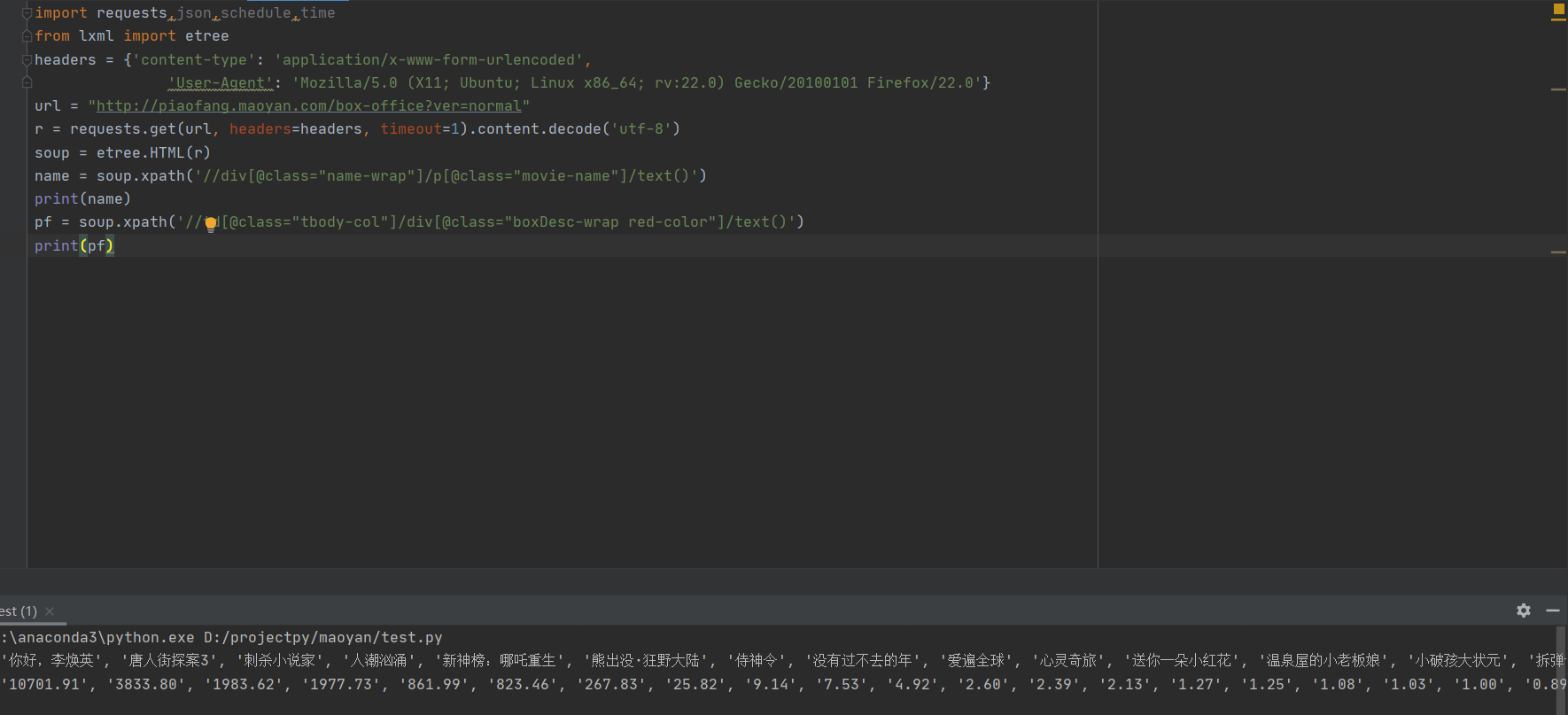
好的。现在这里我们的电影+实时票房已经成功爬取了。
那么现在我们需要把他们给对应起来并保存。我们该怎么做呢?
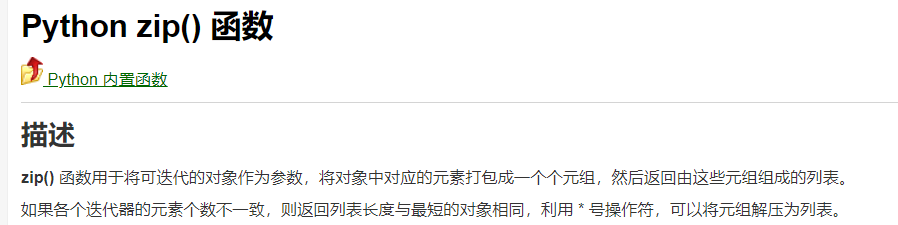
是,俩个循环嵌套?不是,这样是一对多的关系。我们必须将循环同时进行。且,这里我们需要利用zip函数
for i,ii in zip(name, pf):
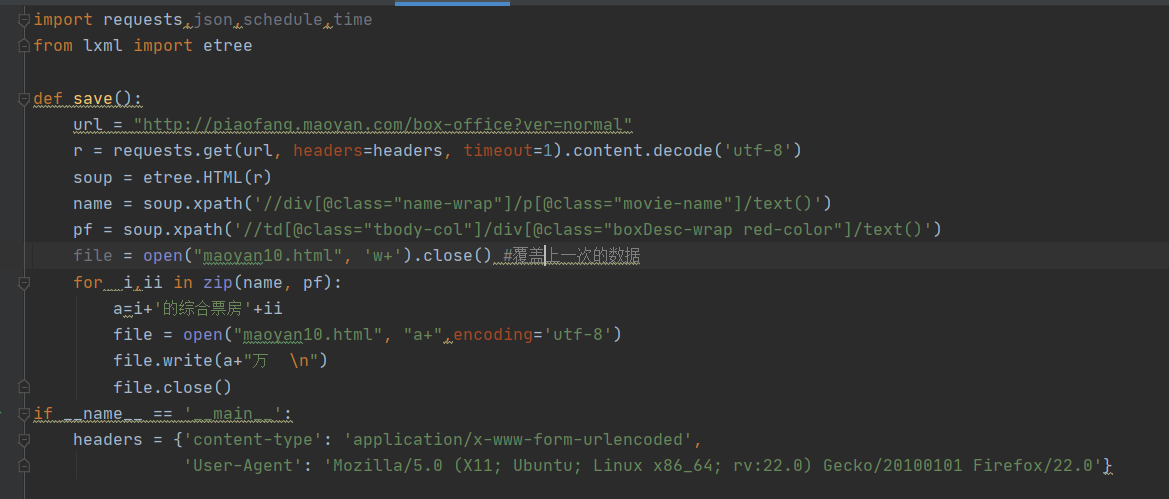
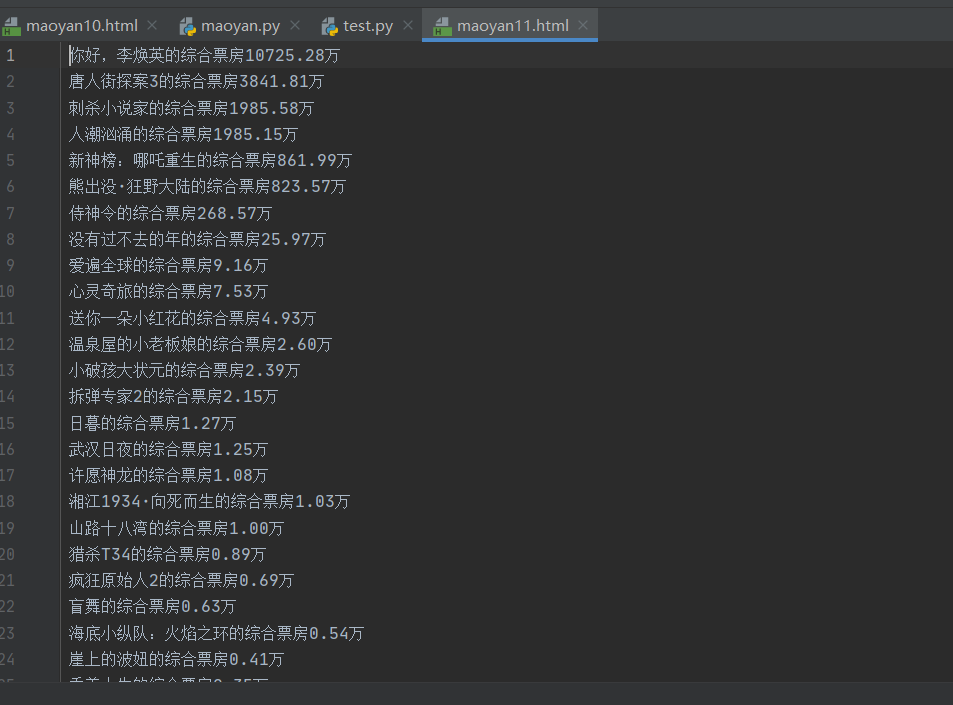
成功保存。这样我们这里的第一部分功能实现了。现在来做第二个功能推送到微信消息。在做这个消息之前,我们需要注册一个企业微信。(信息随便填,不是让你注册企业)
注册成功后,点 管理企业 进入管理界面,然后选择应用管理 → 应用 → 创建应用
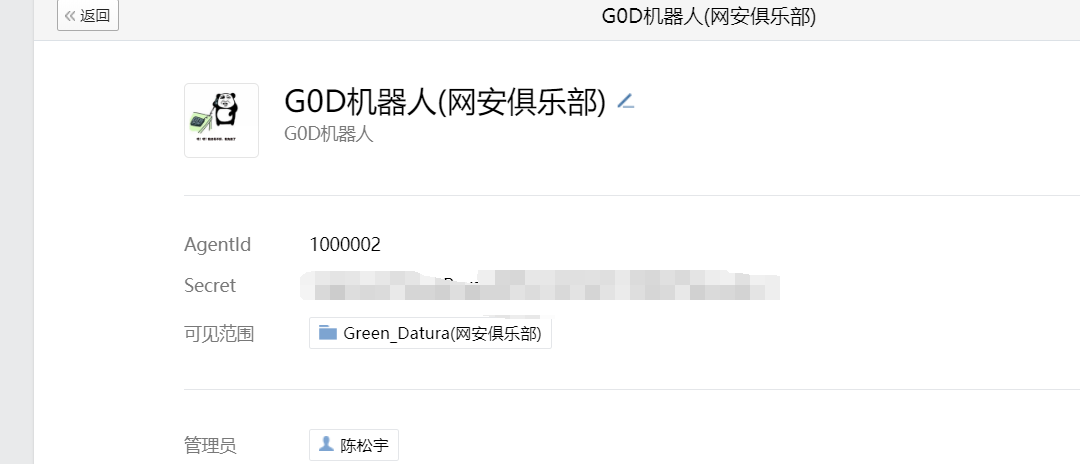
AgentId,Secret后面要用。
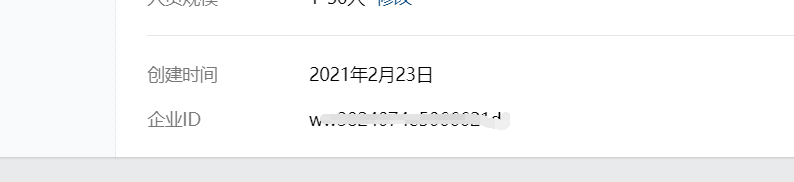
然后点击我的 我的企业可以看到企业ID
OK,然后在下面这个连接输入信息并访问。用来获取access_token
https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=填AgentId&corpsecret=填Secret

现在我们需要提取access_token。(他是动态变化的)
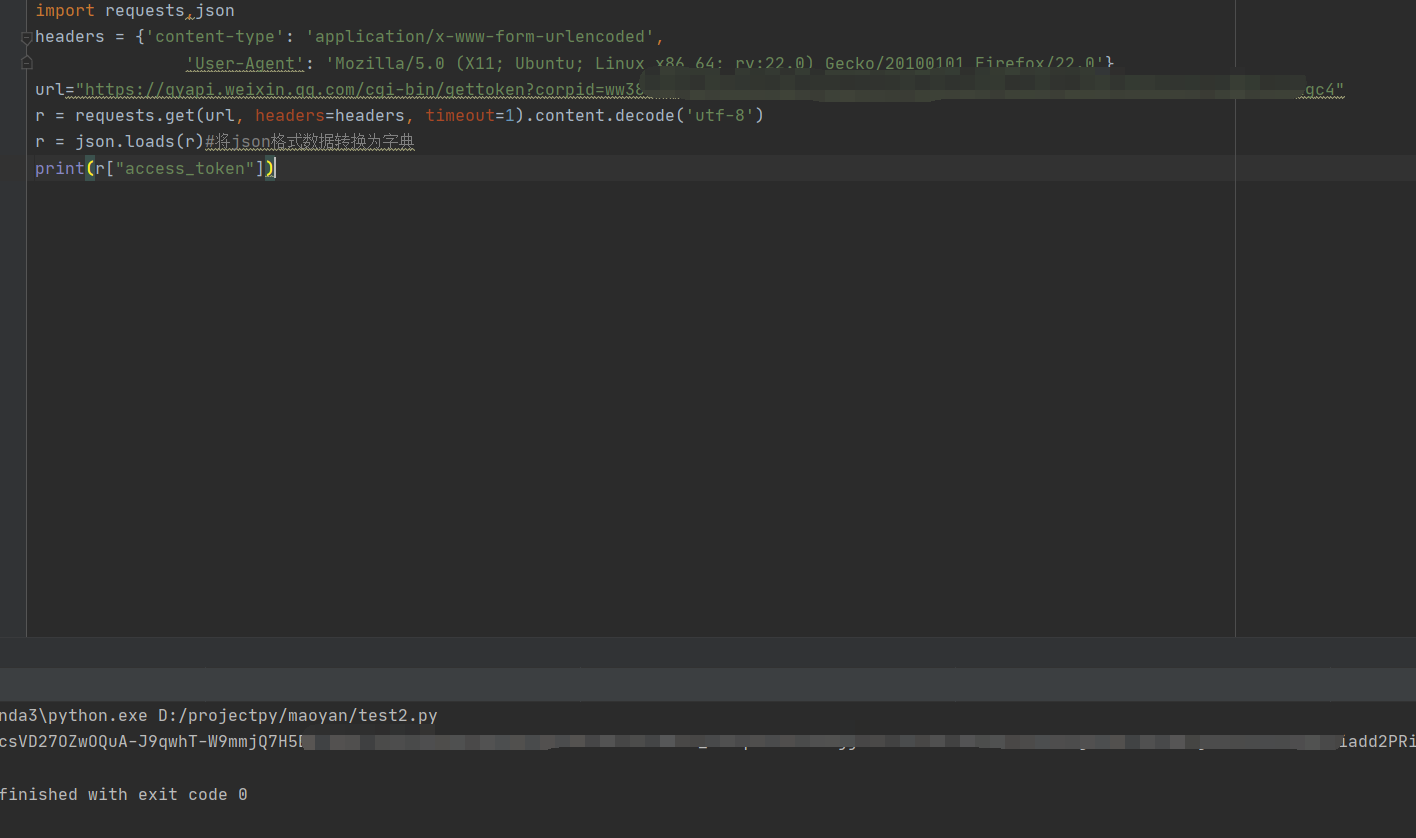
r = json.loads(r)#将json格式数据转换为字典
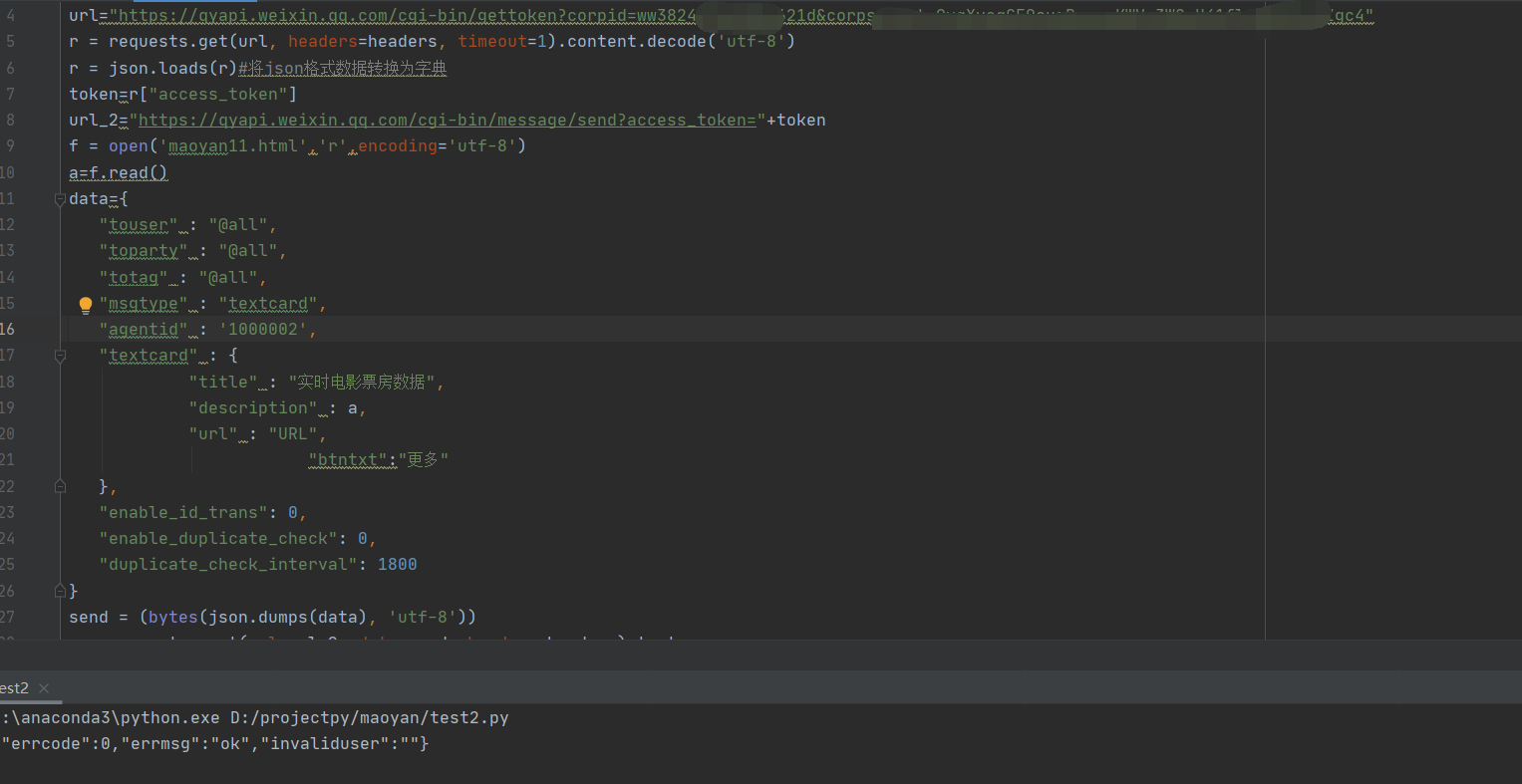
接下来我们就需要post卡片消息到微信的接口
{
"touser" : ["userid1","userid2","CorpId1/userid1","CorpId2/userid2"],
"toparty" : ["partyid1","partyid2","LinkedId1/partyid1","LinkedId2/partyid2"],
"totag" : ["tagid1","tagid2"],
"toall" : 0,
"msgtype" : "textcard",
"agentid" : 1,
"textcard" : {
"title" : "领奖通知",
"description" : "<div class="gray">2016年9月26日</div> <div class="normal">恭喜你抽中iPhone 7一台,领奖码:xxxx</div><div class="highlight">请于2016年10月10日前联系行政同事领取</div>",
"url" : "URL",
"btntxt":"更多"
}
}
结果如图

接下来我们对于俩个功能进行封装。(文件上传到github。觉得还行的xd点波STAR谢谢!)
对了。我们还需要一个定时功能,就用到了schedule函数
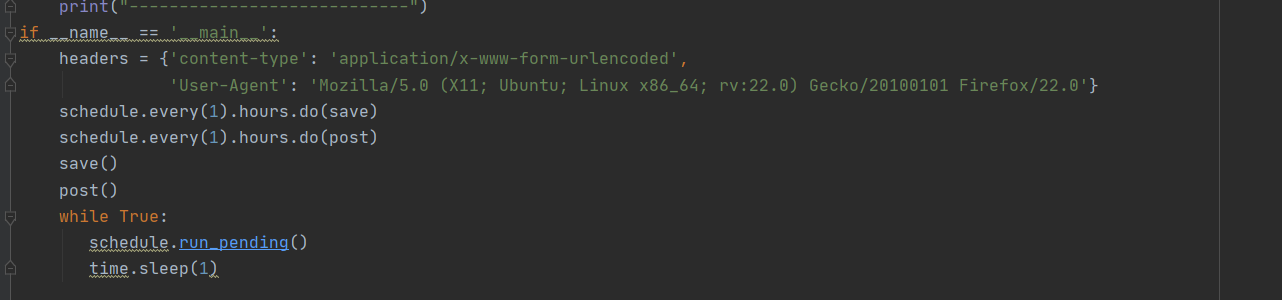
最后成效如下

0x03 文末
python的功能还是十分强大,哈哈!有什么想法,可以在下面留言一起探讨~~~~