◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:https://www.cnblogs.com/by-dream/p/12895967.html
一个分类模型的训练的基本过程:
收集正、负样本——>训练——>模型收敛
现象:
当训练数据比较干净、纯净的情况下,模型的训练在很少轮的情况下就可以达到收敛,而当训练数据不干净,有大量噪声样本混入,训练的次数可能会成倍的增加,甚至都无法得到比较好的收敛。
因此需要寻找噪音样本。
依据:
通常噪音样本属于难以学习或其他样本差异较大的样本。这些噪音的样本在学习过程中,loss下降的比较慢,比较难的收敛,通俗解释就是由于神经网络是一个记忆的过程,这些离群点很有可能在一次学习之后就会被忘记,所以loss下降缓慢,最终导致它的loss值就会被干净的样本值更大,因此找到loss值大,难以训练的样本就是噪音样本。
过程:
训练的过程可以认为是在解一个多元复杂方程的过程,通常我们使用梯度下降来寻找最优解,也就是在凸函数上的极小值。假设定义我们的学习为0.001,在训练收敛后,我们便得到了我们想要的模型。
由于我们要找loss比较大的样本,因此我们进行多轮训练,尝试让噪音样本表现和正常样本更加的区分。
此时我们调整学习率到0.01并且按照每一轮下降0.001的规则,一共进行10轮,从0.01->0.009->0.008 ... ->0.001
由于复杂深度网络模型中,存在很多局部最小值点,因此不同的学习率最终都可以找到一个局部最小值点。在每一轮的训练收敛后,每个样本都会得到一个loss值,根据前面我们定义的10轮,在10轮训练结束后,每个样本都会有十个loss值,我们针对每个样本的loss值计算其方差,然后得到一个值,最终方差比较大的就是噪音样本数据。
用处:
我们以一个内容生产的链路来看看优质内容的保障方案:
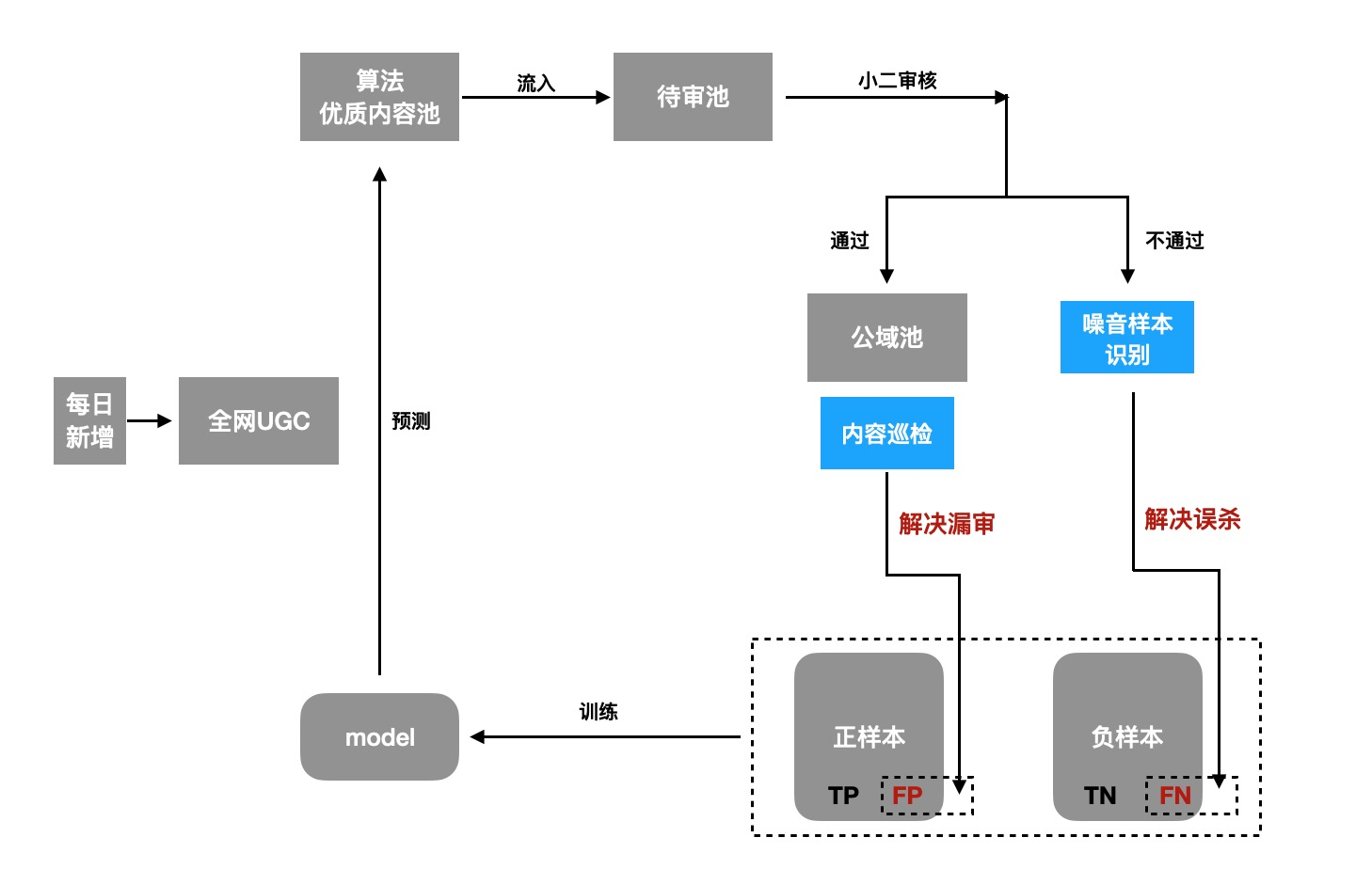
通过算法挖掘出优质内容在进行人工审核后,进入公域池。一方面通过对公域底池内容进行巡检,确保线上不能透出劣质内容,另一方面需要对不通过样本进行噪音样本识别,挽回优质内容的同时,净化训练数据,从而提升模型效果,让模型挖掘出更加优质的内容,形成良性闭环。