业务:查询指定月份每天经过指定线路的客流量
SELECT
day, count(*) num
from `data_set`
WHERE MONTH(day) = 03
and (station_in_line = 2 or station_out_line = 2) GROUP BY day ORDER BY day

但是这里面查的 station_in_line, station_out_line, day都是加了索引的。
用EXPLAN来分析为什么会查的慢:

possible_keys:可能使用到的索引。
key:实际使用到的索引。
key_len:当前使用的索引的长度。
ref:关联 id 等信息。
rows:查找到记录所扫描的行数。
filtered:查找到所需记录占总扫描记录数的比例。
Extra:额外的信息。
从type里得到结论,是因为进行了索引全表扫描,此时遍历整个索引树。发现只用了day这个索引诶,72w条,基本就是全表扫描了,不慢才怪。。
还是很懵懂,于是删去OR条件再看看看,
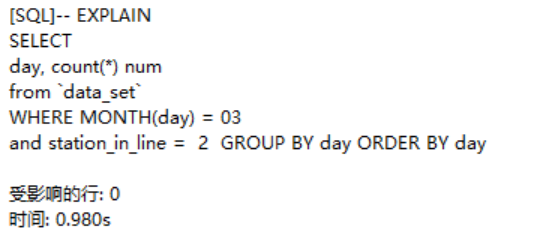

这次终于没有扫描全表,且用的是line_in索引,
ref:非唯一索引扫描,还可见于唯一索引最左原则匹配扫描。
那问题来了,究竟如何去优化呢?
问题:假设有一张订单表 order,主要包含了主键订单编码 order_no、订单状态 status、提交时间 create_time 等列,并且创建了 status 列索引和 create_time 列索引。此时通过创建时间降序获取状态为 1 的订单编码,以下是具体实现代码:select order_no from order where status =1 order by create_time desc
答案:status和create_time单独建索引,在查询时只会遍历status索引对数据进行过滤,不会用到create_time列索引,将符合条件的数据返回到server层,在server对数据通过快排算法进行排序,Extra列会出现file sort;应该利用索引的有序性,在status和create_time列建立联合索引,这样根据status过滤后的数据就是按照create_time排好序的,避免在server层排序
也就是,对于当前的这条SQL语句,可以去建立联合索引,对station_in_line和day先尝试建立联合索引。
经过一番捣鼓,本憨憨发现原来联合索引还会和谁先谁后有关系,
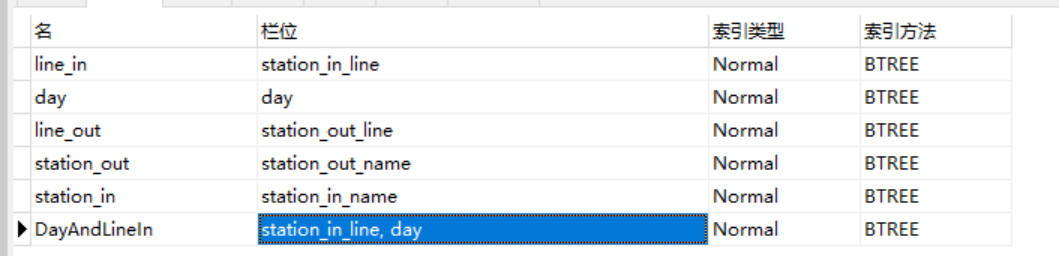
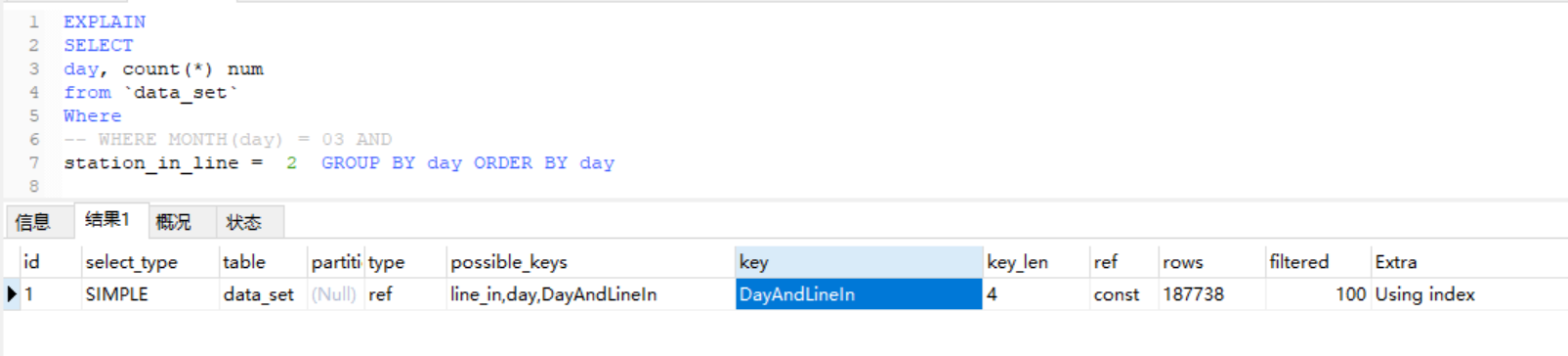
看到一篇博文里说用了函数会导致索引不生效,但是测试加了Month()仍然是生效的(截图就不放了)
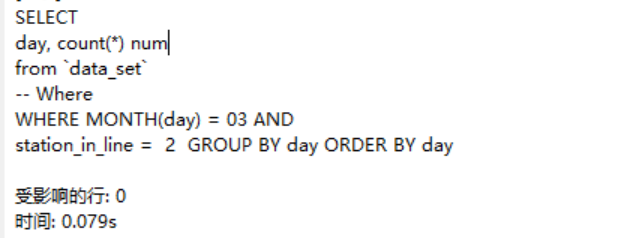
然后!
联合索引对or关系不起作用,必须要使用and作为条件。
可以说是非常心痛,就是再怎么弄也不能把"OR"给优化掉鸭。。。
找了比较久找到了Union,果然还是太久没写SQL啥都不知道了呜呜,
但是,费心费力加上了联合索引,

索引老哥,你的心不会痛吗

隔了两秒发现是自己太蠢了,
SELECT SUM(cnt) FROM (
SELECT day, count(station_in_line) as cnt from `data_set` where MONTH(day) = #{month}
AND station_in_line = #{line}
GROUP BY day
UNION
SELECT day, count(station_out_line) as cnt from `data_set` where MONTH(day) = #{month}
AND station_out_line = #{line}
GROUP BY day )
AS result GROUP BY day
行吧,这就算是我的优化成品了

